SiFive Announces First RISC-V OoO CPU Core: The U8-Series Processor IP
by Andrei Frumusanu on October 30, 2019 10:00 AM ESTThe U8-Series Microarchitecture
We’ve had the pleasure of being briefed on the key aspects of the U8 microarchitecture, and we’ll be able to have a more in-depth look (albeit high-level) at how the new CPU design functions.
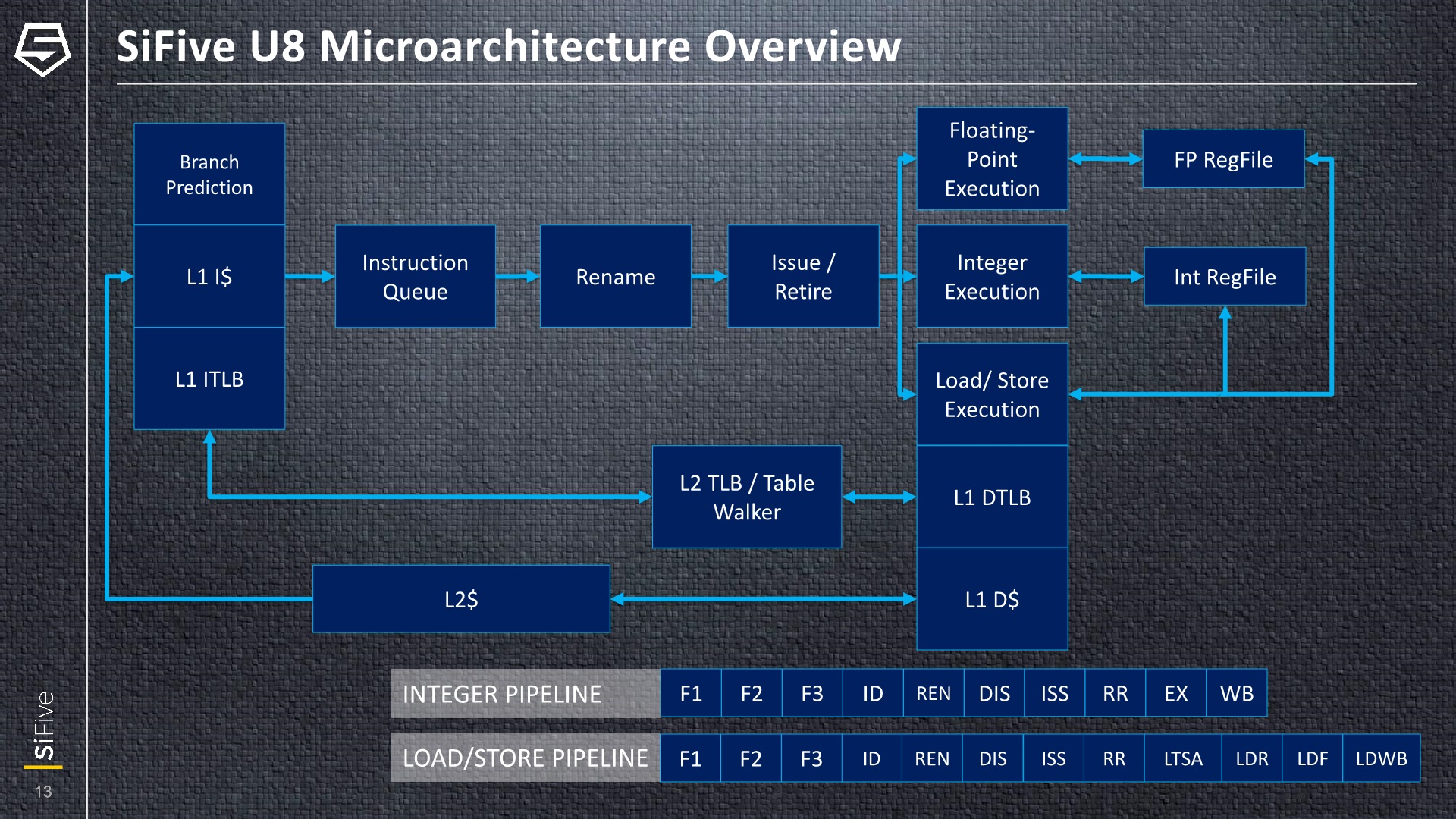
At the highest level, the U8 is a 3-wide issue out-of-order CPU with a pipeline depth of 12 stages, feeding 3 execution units. It’s a pretty traditional OoO-design and the noteworthy design choice here is the core’s use of physical register files instead of an architectural one, such as seen in initial Arm designs such as the A72.
One thing to note as we’re covering the microarchitecture is that SiFive didn’t disclose the exact sizes of some of the structures, which is somewhat natural given the core’s purported scalable configuration design where one can change many aspects of the IP, and we’re only covering the generic U8-Series microarchitecture as individual implementations (Such as an U84) will have different configurations.
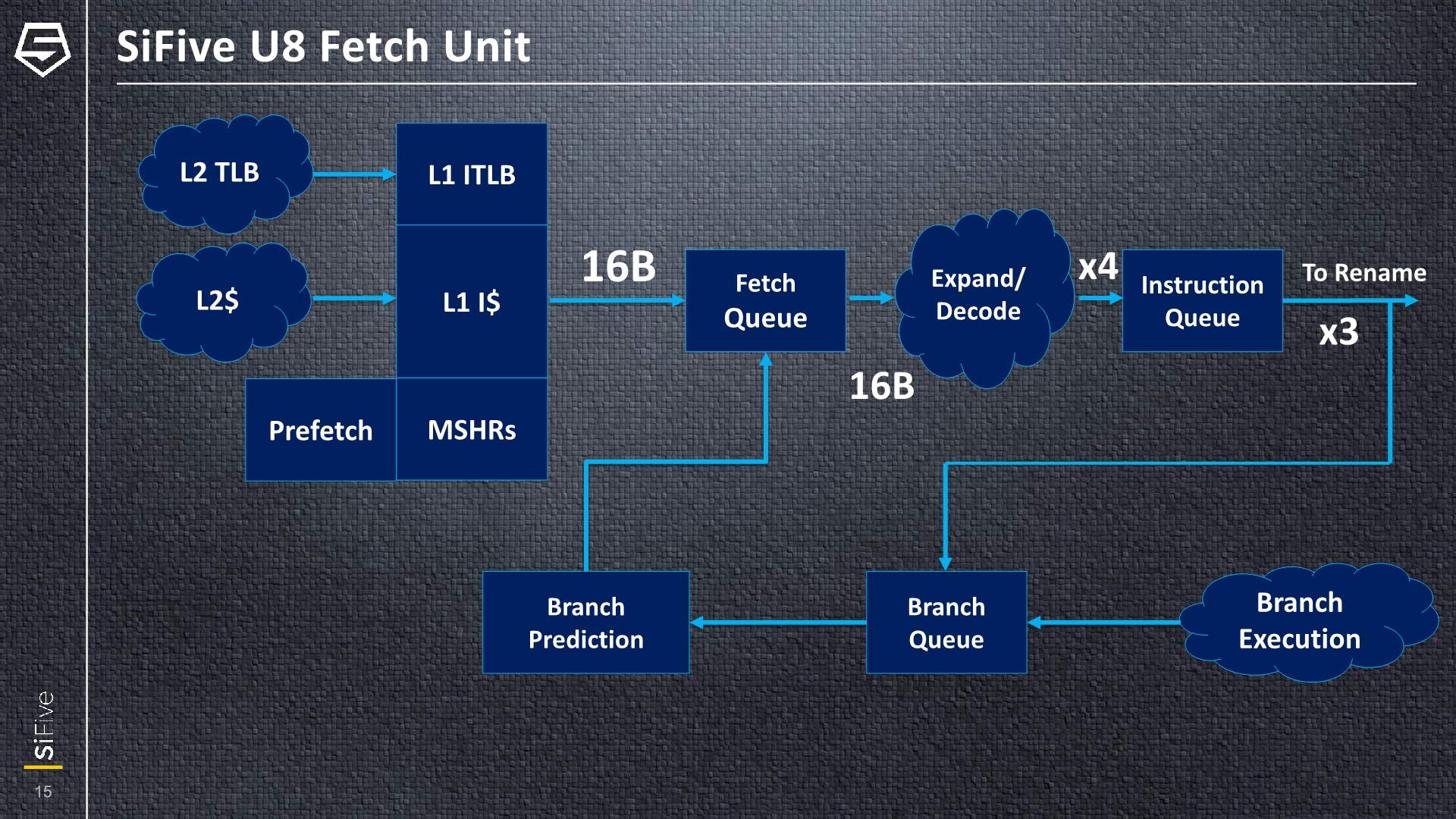
The fetch unit of the core is able to request instructions out of the L1I at 16 bytes per cycle and put it into the fetch queue of the front-end. The RISC-V ISA has a variable instruction encoding size, so it’s not possible to map this to an exact number on instructions as one can on the Arm ISA, but if we naively assume a 32-bit average, it would correspond to 4 instructions per cycle. Of course, this isn’t surprising as the decoder on the U8 is 4-wide, feeding expanded instructions into the instruction queue.
The interesting thing here about the core is that the instruction queue is only able to issue 3 instructions out to the rename stage. Having the fetch width being higher than your issuing rate helps in the case of branch mispredictions and bubbles and allows the front-end to catch up with the execution backend, something we’ve also seen in other cores; however, we never quite saw an implementation in which the decoder was wider than the issue rate (Actually, only Intel's recent Tremont microarchitecture would also fit this characteristic). Beyond it being a deliberate design decision for the balance of the microarchitecture, maybe it’s also a forward-looking implementation on the part of the decoder whilst we may see wider issue configurations in future U8 designs.
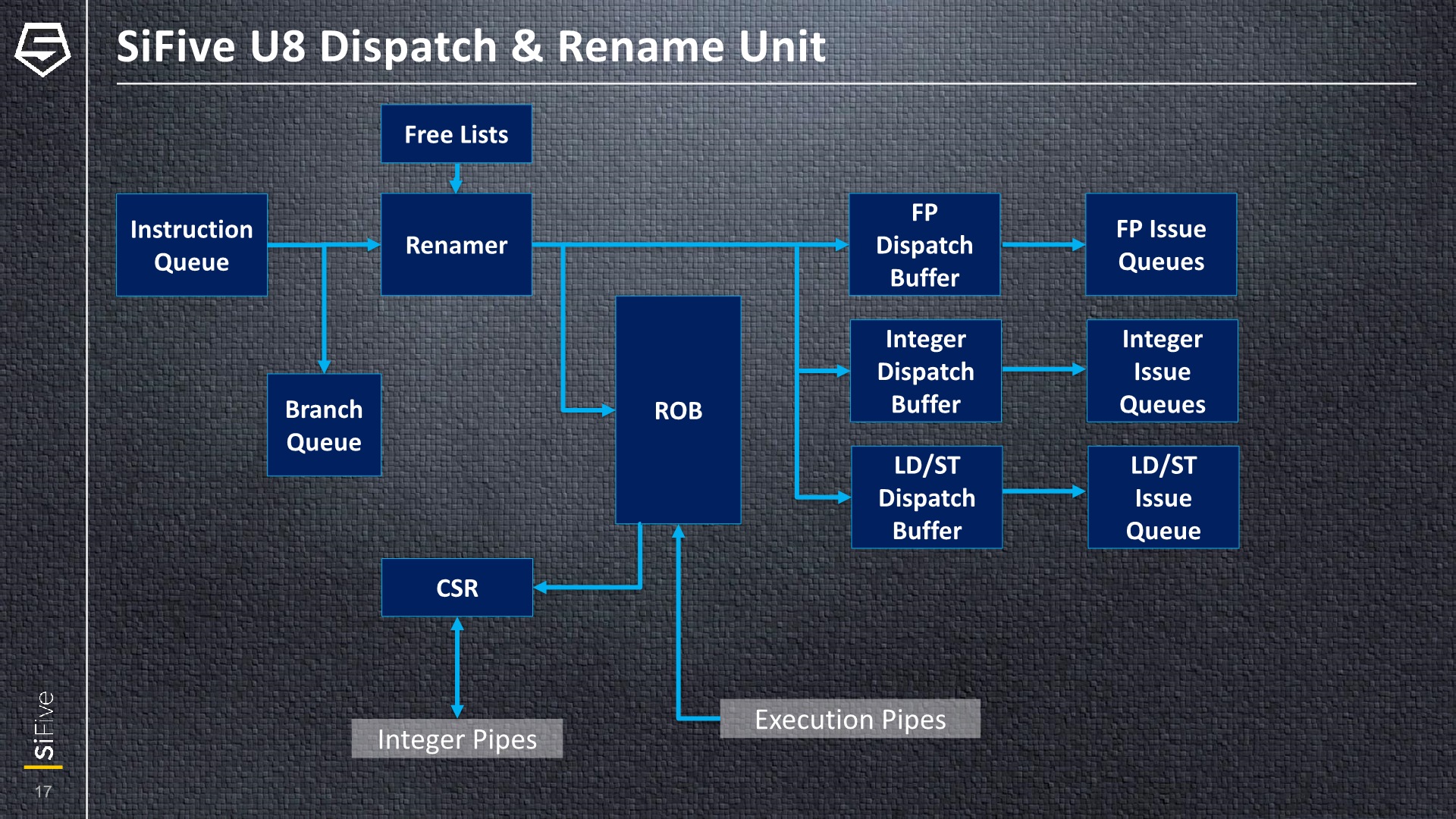
Moving on to the mid-core, we see a traditional design into the rename stage, a re-order buffer and three dispatch engines feeding into the execution pipelines. The diagram here is a bit misleading in terms of the arrows going into the issue queues – it doesn’t mean that it’s only one instruction per issue queue, the core can still dispatch up to 3 instructions into the integer issue queues for example.
It would have been interesting to hear about the exact structure sizes on this part of the core but SiFive didn’t cover these details during the presentation.
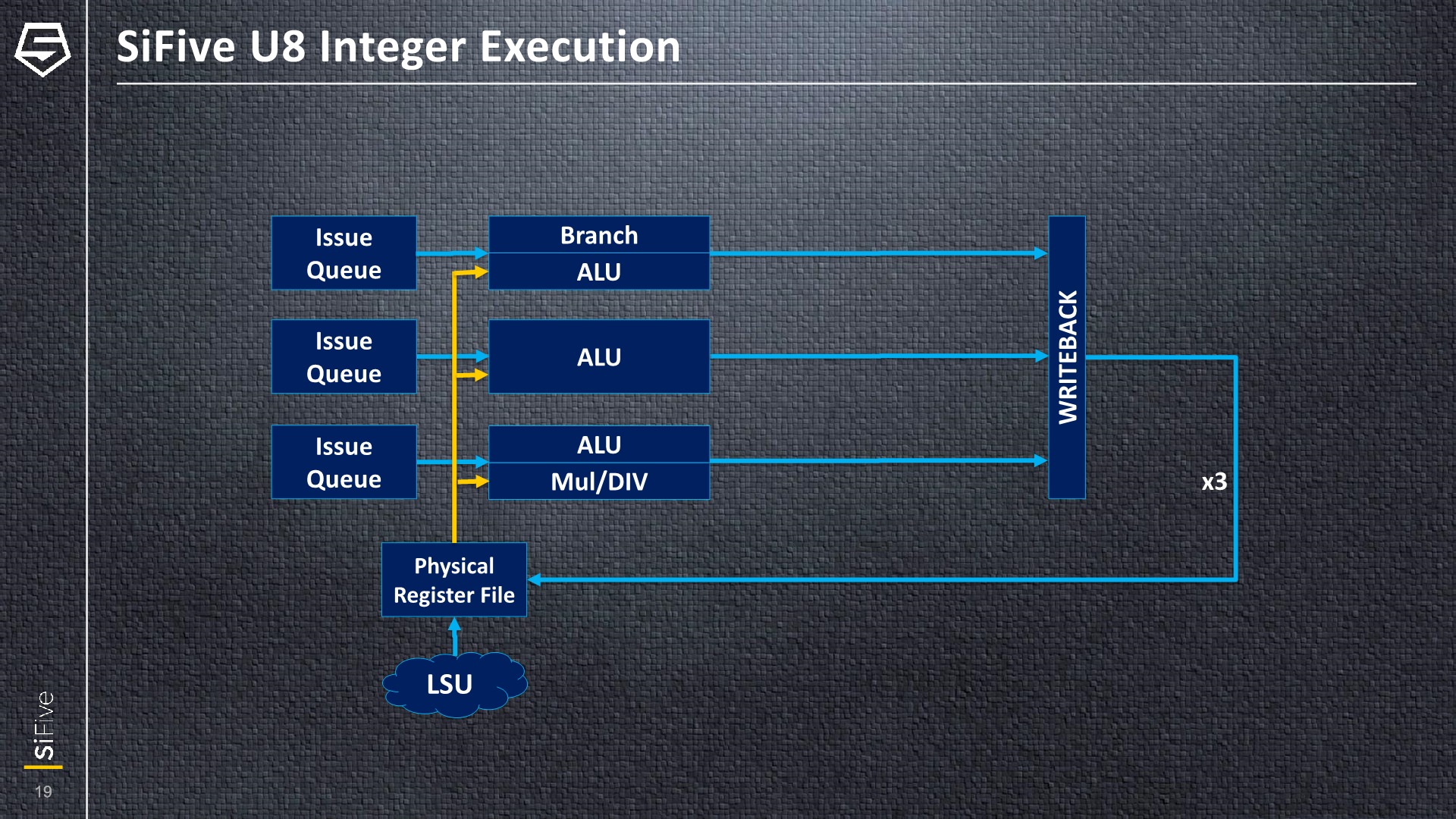
On the integer execution block, we see that it’s actually composed of three execution pipelines. Each has its own issue queue, feeding into three ALU pipelines with different capabilities. One pipeline serves just as a regular ALU, a second one shares the port with the branch unit, while the third pipeline is a more complex one capable of integer multiplication and division.
Unfortunately, SiFive didn’t go into any detail of the floating-point pipelines or the L/S units. On the FP side, things should be relatively simple in terms of the execution capabilities, at least on the U84 core. Currently, RISC-V does not have any SIMD/Vector instructions as that ISA extension has not been finalized yet. SiFive explains that this might happen at the end of the year, and the U87 is poised to adopt the new vector capabilities next year.








68 Comments
View All Comments
peevee - Tuesday, November 5, 2019 - link
"ARM is literally 80's RISC too"Armv8? No it is not. It has very many complex instructions, more than any CISC CPU from the 80s.
TeXWiller - Wednesday, October 30, 2019 - link
On the other hand you can find demonstrations on how targeting RISC-V ISA can produce smaller end-products compared to targeting ARM or specifically MIPS.Modularity of the ISA is another thing and the most appealing factor still is the open nature of the ISA. This is what likely drives the adoption outside of US academia in companies like WD and in academic-industrial projects in Europe (the exascale accelerator) and India (national ISA). The aim for some schools is to produce graduates directly familiar with an ISA and architectures utilized in the industry without additional training.
I do wonder what effect the variable length instruction ecoding have on security if the system software is lacking on those demanding edge use-cases in the future, though.
Wilco1 - Wednesday, October 30, 2019 - link
Smaller products in what way? Saving a fraction of a mm^2 due to simplified decode is a great marketing story without doubt. However if you look at a modern SoC, typically less than 5% is devoted to the actual CPU cores. If the resulting larger codesize means you need to add more cache/flash/DRAM, increase clock frequency to deal with the extra instructions or makes it harder for a compiler to produce efficient code, is it really an optimal system-wide decision?TeXWiller - Wednesday, October 30, 2019 - link
I meant in terms of codesize as that was one of the bases of the MIPS comparison. Sorry for the confusion.Wilco1 - Thursday, October 31, 2019 - link
RISC-V is very similar to MIPS - MIPS never was great at codesize. When optimizing for size, compilers call special library functions to emulate instructions which are available on Arm. So you pay for saving a few transistors with lower performance and higher power consumption.zmatt - Thursday, October 31, 2019 - link
It's not a MIPS variant. MIPS is based on work at Stanford. RISC-V is the latest incarnation of the Berkeley RISC project. You are probably thinking of SPARC which is a derivative of earlier RISC project work. MIPS is only related in that it comes from similar ideas but the two projects, Stanford and Berkeley were different.name99 - Thursday, October 31, 2019 - link
That's like making a big deal about the difference between Spanish and Portuguese.Sure, if you're Spanish this is a big deal. But to the rest of the world they're basically the same thing; created by people in constant contact and with the same world view.
zmatt - Friday, November 1, 2019 - link
Well, Spanish and Portuguese are different. And claiming they are the same gets you labeled as either an idiot or a bigot.name99 - Friday, November 1, 2019 - link
Are they as different as Portuguese and Arabic? Spanish and Chinese?Are you really so ignorant that you don't know the family resemblance of Romance languages?
Wilco1 - Thursday, October 31, 2019 - link
RISC-V has practically nothing in common with Berkeley RISC-I/SPARC (no condition codes, no register windows etc). Basically Berkeley adopted Stanford's approach to RISC and created a MIPS variant.