Cortex-M7 Launches: Embedded, IoT and Wearables
by Stephen Barrett on September 23, 2014 7:01 PM ESTThe Cortex-M7 CPU
The primary focus of the Cortex-M7 is improved performance. ARM’s goal was to elevate the M series performance to a level previously unseen, while maintaining the M series' signature small die size and tiny power consumption. There are at least two reasons ARM focused on performance for the M7 processor. First, they want to further drive a wedge between traditional 8- and 16-bit microcontrollers and provide ARM a further differentiated market position; second, the M7 will help support the IoT (Internet of Things) and wearable device markets. Focusing on enhanced DSP capabilities, the M7 is more suited to audio and visual sensor hub processing than any previous M series design.
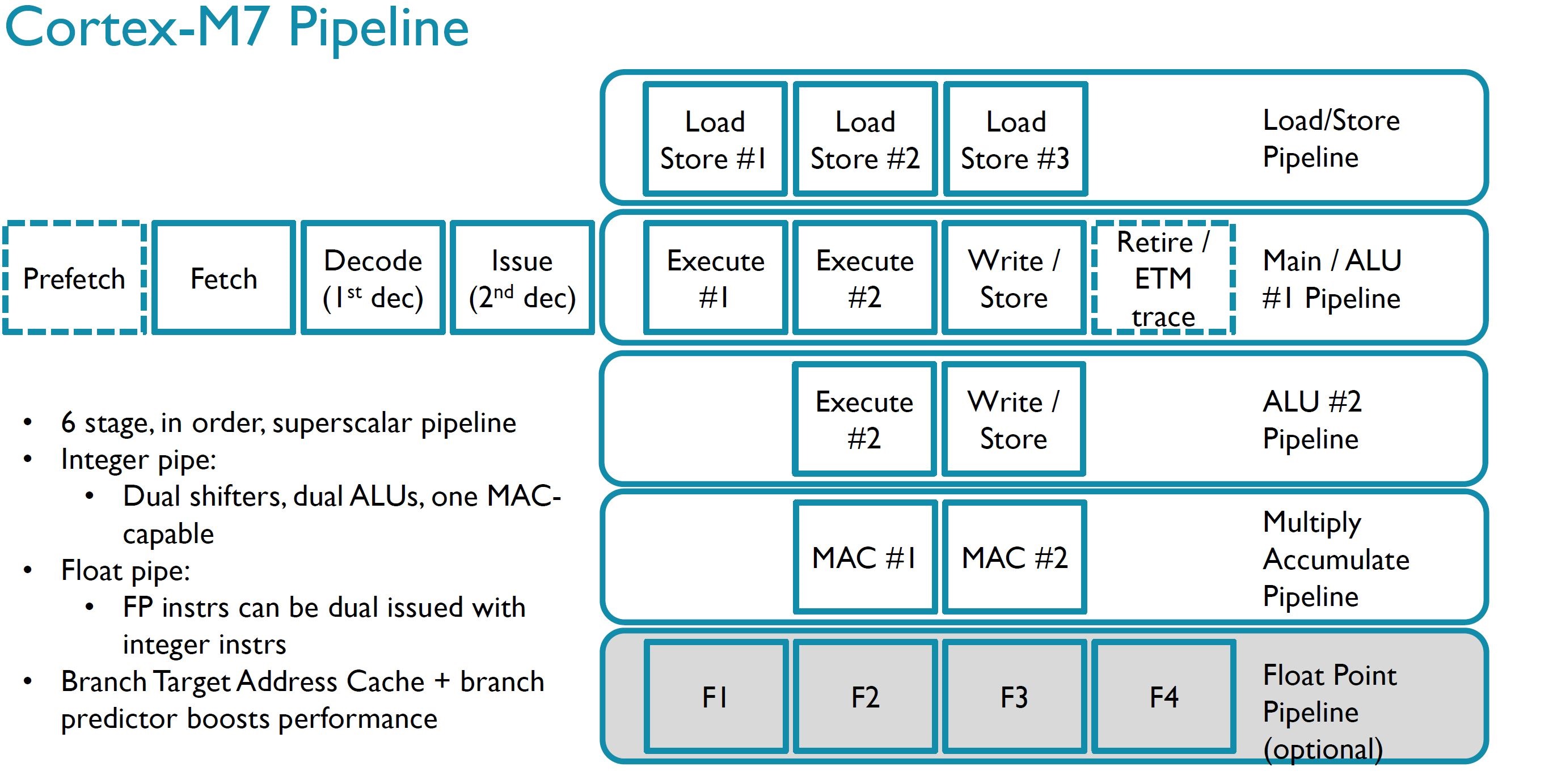
Digging into the details, the Cortex-M7 features a six-stage, in-order, dual-issue superscalar pipeline with single- and double-precision floating point units, instruction and data caches, branch prediction, SIMD support, and tightly coupled memory. Here's the high level view of the pipeline:
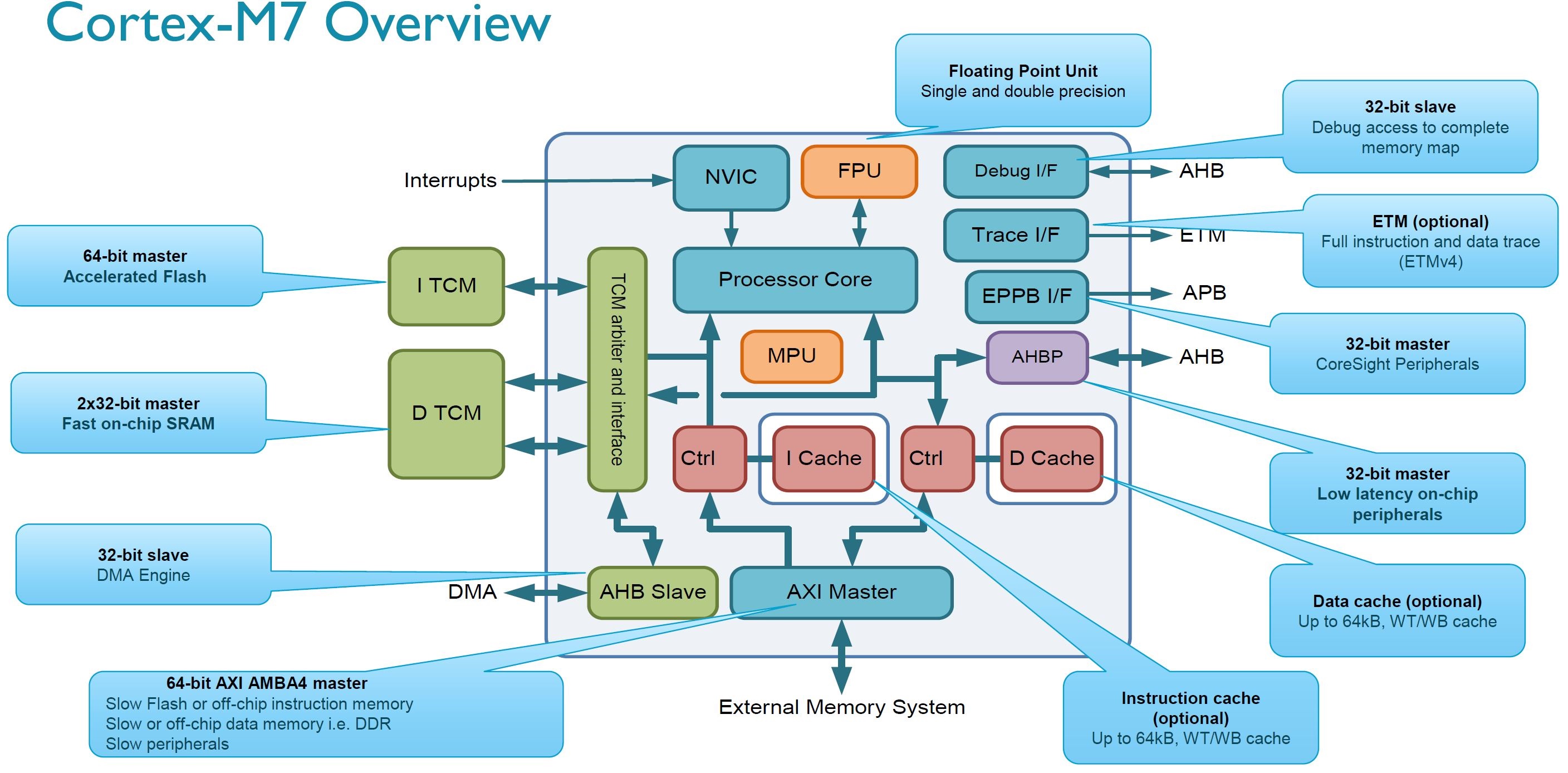
The presence of instruction and data caches, branch prediction, as well as tightly coupled memory are differentiating features of the M7 versus previous M series processors. Microcontrollers often forego caches and sometimes even operate with flash as the only memory interface. By providing high performance instruction and data caches, the M7 approaches more typical high performance processor design.
Tightly coupled memory (TCM) is a technology ARM’s partners can use to extend the effective caching of a single M7 processor and has only been seen in previous A and R series designs. In use, it can have the performance of a cache but, unlike cache, its contents are directly controlled by the developer. That is, TCM is part of the physical memory map of the microcontroller. Developers can place critical code and data inside TCM that can be deterministically accessed with high performance in routines such as interrupt service requests. The M7 supports up to 16 MB of tightly coupled memory.
Adding branch prediction allows arm to target dedicated DSP devices with its Cortex-M7 microcontroller. DSP code is often analog data stream filters for applications such as audio input keyword detection, audio output equalization, and frequency domain amplitude peak searching. When running on an always-on microcontroller these tasks are almost always looped. Without a branch predictor, the code must continually evaluate a loop condition that 99.9% of the time results in the same outcome. Branch predictors cost extra die space but when DSP is your target, they are an obvious design benefit.

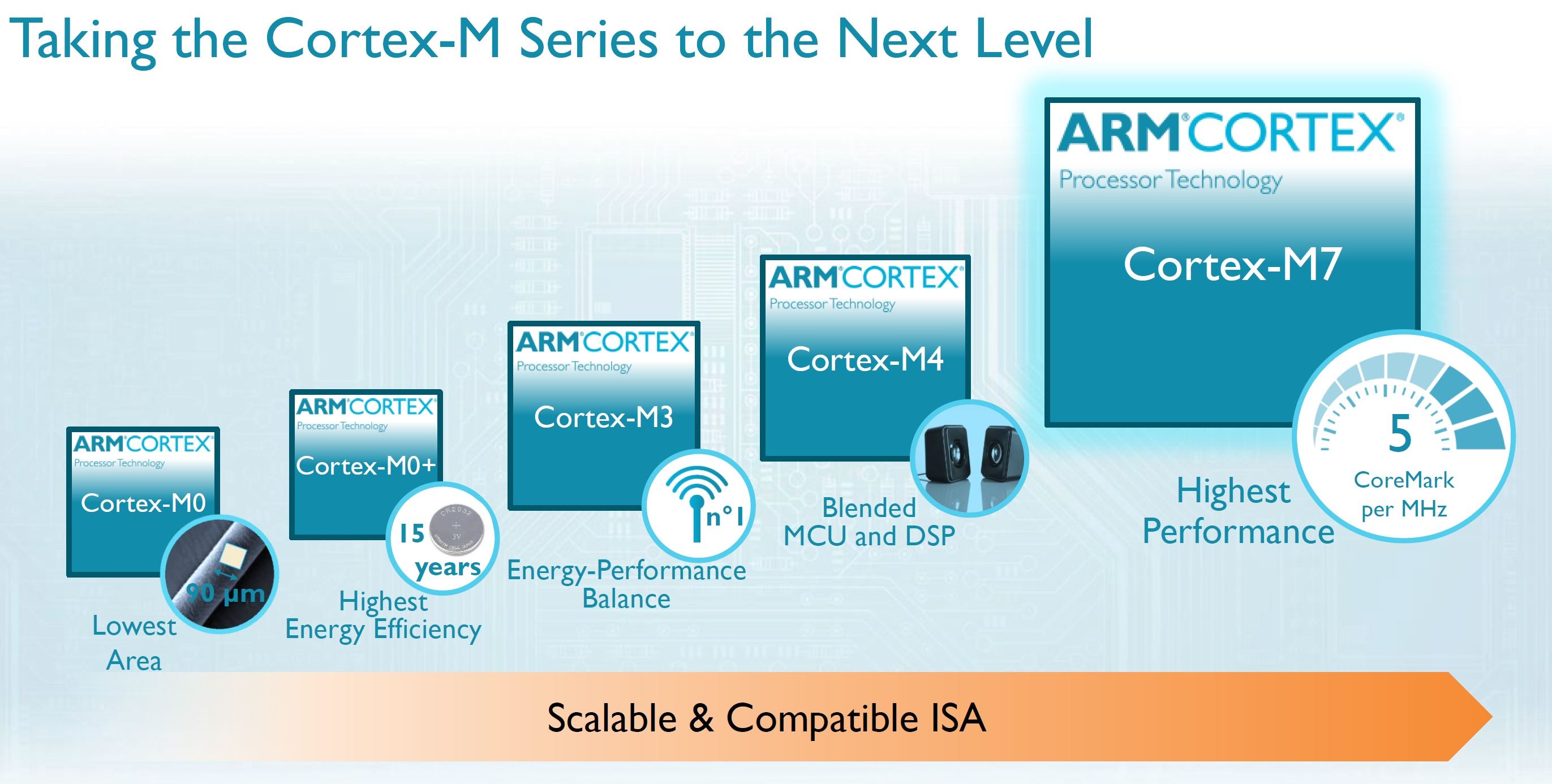
Summarizing the M series cores can be done both from an instruction features standpoint and also a die size and performance standpoint. Unfortunately ARM, who provides HDL (Hardware Description Language) that can be synthesized to physical chips, was not yet willing to provide die size numbers until their partner Cortex-M7 announcements, since the processor does not become physical until a partner gets involved. Until a partner releases data, we can simply assume the M7 somewhat larger than its predecessors.
| ARM Cortex-M Instruction Sets | |||||||||||
| M0 | M0+ | M3 | M4 | M7 | |||||||
| Thumb | Most | Most | Entire | Entire | Entire | ||||||
| Thumb-2 | Subset | Subset | Entire | Entire | Entire | ||||||
| Hardware multiply | 1 or 32 cycles | 1 or 32 cycles | 1 cycle | 1 cycle | 1 cycle | ||||||
| Hardware divide | No | No | Yes | Yes | Yes | ||||||
| Saturated math | No | No | Yes | Yes | Yes | ||||||
| DSP Extensions | No | No | No | Yes | Yes, enhanced | ||||||
| Floating-point | No | No | No | Optional single precision | Yes | ||||||
| Tightly coupled memory | No | No | No | No | yes | ||||||
| Architecture | ARMv6-M | ARMv6-M | ARMv7-M | ARMv7-M | ARMv7-M | ||||||
| Cache Architecture | Von Neuman | Von Neuman | Harvard | Harvard | Harvard | ||||||
| ARM Cortex-M Area, Power, Performance | |||||||||||
| M0 | M0+ | M3 | M4 | M7 | |||||||
| 90nm LP dynamic power (µW/MHz) | 16 | 9.8 | 32 | 33 | n/a | ||||||
| 90nm LP area mm2 | 0.04 | 0.035 | 0.12 | 0.17 | n/a | ||||||
| 40nm G dynamic power (µW/MHz) | 4 | 3 | 7 | 8 | n/a | ||||||
| 40nm G area mm2 | 0.01 | 0.009 | 0.03 | 0.04 | n/a | ||||||
| Dhrystone (official) DMIPS/MHz | 0.84 | 0.94 | 1.25 | 1.25 | 2.14 | ||||||
| Dhrystone (max options) DMIPS/MHz | 1.21 | 1.31 | 1.89 | 1.95 | 3.23 | ||||||
| CoreMark/MHz | 2.33 | 2.42 | 3.32 | 3.40 | 5.04 | ||||||
ARM did state that power consumption of M7 is roughly in line with previous performance/mW, so we could estimate a corresponding increase of 50% to 75% more power consumption. Area is anyone's guess at the moment.








43 Comments
View All Comments
nathanddrews - Wednesday, September 24, 2014 - link
For as often as my phone, computer, stove, and microwave all get out of sync, you'd think we humans haven't yet mastered the whole "tracking of time" thing. Most of my devices are supposed to auto-update online, but that doesn't excuse the poor time-keeping of modern devices in between updates. Smart watch? Doubtful.markmuehlbauer - Wednesday, September 24, 2014 - link
Good point. 2014 and where are standards for this across all devices? The only devices that are truly accurate subscribe to a network time protocol (NTP) service.How about we recycle amplitude modulated carriers toward a narrow band digital signal broadcast NTP service. Then every device out there can have a simple AM loop antenna in it to "listen" to the NTP service and update. Of course this would require the FCC and IEEE to actually work together. Sigh. . .
otherwise - Wednesday, September 24, 2014 - link
There are already at least two ways to get a reference timestamp over the air. First is GPS, which will get you accurate timestamps into the sub-millisecond domain, which is why you see GPS devices in data centers usually as a stratum0 NTP device and/or a PTP Master. The second is WWVB operated by the NIST, which broadcasts reference timestamps at the 60KHz band. If you have an alarm clocks that sets itself this is probably the source it uses.makerofthegames - Tuesday, September 23, 2014 - link
So for my own understanding of roughly how powerful these are, what x86 processor would you say they're most comparable to? From the general architecture they look like a first-gen P5 Pentium, minus the MMU (and optionally minus the cache and FPU). Would that be an accurate analogy?jdesbonnet - Tuesday, September 23, 2014 - link
It's hard to directly compare MCUs to application processors. They have different types of tasks. Application processors are about computational throughput and you pay for that in enormous gate counts (=area=cost) and energy consumption. Eg the quad core Intel Xeon I'm using right now has a gate count in excess of 2G gates. By comparison a small Cortex M0 will have as few as 12K gates and can run tasks such as wireless security sensors for years on end from a single coin cell battery. Also MCUs facilitate deterministic code execution where timing of events is critical (eg detect car crashing -> deploy airbag). For benchmarks look a this table: http://en.wikipedia.org/wiki/Instructions_per_seco... Seems a ARM Cortex M0 at 50MHz is somewhere between an Intel 486DX and the original Pentium.makerofthegames - Tuesday, September 23, 2014 - link
Yeah, it's never going to be an exact comparison. I pulled the P5 guess from the architecture - both P5 and M7 are in-order, two-issue superscalar with two main integer paths and an FPU. And while their goals were very different, they both were very constrained for transistors (by current standards), so I figured they might have some level of comparison.wetwareinterface - Wednesday, September 24, 2014 - link
the nearest comparison to an x86 processor is the new intel edison. however where this will excel at certain tasks the edison will excel at others.to break it down any task that is memory bandwidth constrained will be better on edison.
any task that is latency critical and served best by an interrupt (the car crash airbag analogy above serves well) is better performed on the m7.
any task that is math based, requires simple calculations, and parallel execution or reordering on the fly of the task being performed is done frequently then the m7 would be a good choice with the inclusion of the dsp. an example of this is manipulation of incoming audio or video data in response to user input (examples like a guitar pedal for audio or video mixing effects like on a club's screens).
the simple fact is there's no perfect "one solution".
what one does better the other does worse and no processor is best in all catagories
Stephen Barrett - Wednesday, September 24, 2014 - link
edison isnt so much a processor as it is a SoM or system on module. It contains an atom silvermont applications processor (AP) and an Intel Quark microcontroller (MCU).HardwareDufus - Tuesday, September 23, 2014 - link
hmmm.. they are a risc based architecture (armv7 ISA), so they wouldn't have as high as an IPC as a cisc based architecture like pentium. however this cortex-m7 mcu is more a soc than just a straight processor like the pentium was. hard to say as the workloads are so absolutely different.BTW, with the embargo lifted.... ARM just updated their website:
http://arm.com/products/processors/cortex-m/cortex...
http://arm.com/Cortex-M7-chip-diagramLG.png
will be exciting to watch some of the initial development & prototyping boards introduced by some of the big players (ti, stmicroelectronics and atmel) to see what native capabilities they break out.
hopefully ethernet, sdio, jtag, and multiple channels of uart, can, spi, i2c/twi, dac are givens. would love a basic lcd interface too.
Wilco1 - Tuesday, September 23, 2014 - link
No, by definition RISCs have better IPC than CISCs, not the other way around (on a RISC pretty much every instruction executes in a single cycle, unlike the complex CISC instructions). Studies have shown x86 and ARM actually do the same amount of work per instruction due to x86 compilers avoiding the complex instructions (this observation is why RISC exists!), and ARM doing a lot of work per instruction (compared to other RISCs - such as allowing shift+add as a single instruction, conditional execution, load/store multiple). This effectively means any IPC difference is not due to ISA but due to microarchitecture.Looking at the Dhrystone results, the M7 is a bit faster than A7, so should obliterate Quark, beat an old Pentium and do well against Silverthorne at similar frequency.