The Intel Xeon E7-8800 v3 Review: The POWER8 Killer?
by Johan De Gelas on May 8, 2015 8:00 AM EST- Posted in
- CPUs
- IT Computing
- Intel
- Xeon
- Haswell
- Enterprise
- server
- Enterprise CPUs
- POWER
- POWER8

The story behind the high-end Xeon E7 has been an uninterrupted triumphal march for the past 5 years: Intel's most expensive Xeon beats Oracle servers - which cost a magnitude more - silly, and offers much better performance per watt/dollar than the massive IBM POWER servers. Each time a new generation of quad/octal socket Xeons is born, Intel increases the core count, RAS features, and performance per core while charging more for the top SKUs. Each time that price increases is justified, as the total cost of a similar RISC server is a factor more than an Xeon E7 server. From the Intel side, this new generation based upon the Haswell core is no different: more cores (18 vs 15), better RAS, slightly more performance per core and ... higher prices.
However, before you close this tab of your browser, know that even this high-end market is getting (more) exciting. Yes, Intel is correct in that the market momentum is still very much in favor of themselves and thus x86.
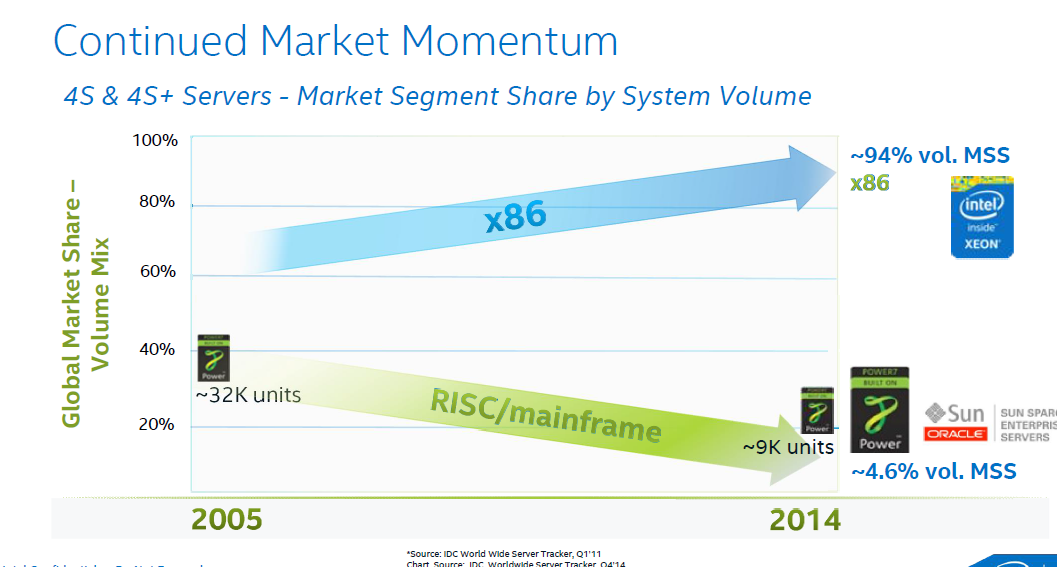
No less than 98% of the server shipments have been "Intel inside". No less than 92-94% of the four socket and higher servers contain Intel Xeons. From the revenue side, the RISC based systems are still good for slightly less than 20% of the $49 Billion (per year) server market*. Oracle still commands about 4% (+/- $2 Billion), but has been in a steady decline. IBM's POWER based servers are good for about 12-15% (including mainframes) or $6-7 Billion depending on who you ask (*).
It is however not game over (yet?) for IBM. The big news of the past months is that IBM has sold its x86 server division to Lenovo. As a result, Big Blue finally throw its enormous weight behind the homegrown POWER chips. Instead of a confusing and half heartly "we will sell you x86 and Itanium too" message, we now get the "time to switch over to OpenPOWER" message. IBM spent $1 billion to encourage ISVs to port x86-linux applications to the Power Linux platform. IBM also opened up its hardware: since late 2013, the OpenPower Foundation has been growing quickly with Wistron (ODM), Tyan and Google building hardware on top of the Power chips. The OpenPOWER Foundation now has 113 members, and lots of OpenPower servers are being designed and build. Timothy Green of the Motley fool believes OpenPower will threaten Intel's server hegemony in the largest server market, China.
But enough of that. This is Anandtech, and here we quantify claims instead of just rambling about changing markets. What has Intel cooked up and how does it stack up to the competion? Let's find out.
(*) Source: IDC Worldwide Quarterly Server Tracker, 2014Q1, May 2014, Vendor Revenue Share








146 Comments
View All Comments
Kevin G - Monday, May 18, 2015 - link
@Brutalizer“I told you umpteen times. The problem is that scalability in code that branches heavily can not be run on SGI scale-out clusters as explained by links from SGI and links from ScaleMP (who also sells a 100s-socket Linux scale out server). And the SGI UV2000 is just a predecessor in the same line of servers. Again: UV2000 can. not. run. monolithic. business. software. as. explained. by. SGI. and. ScaleMP”
Running branch heavy code doesn’t seem to be a problem for x86: Intel has one of the best branch predictors in the industry. I don’t see a problem there. I do think you mean something else when you say ‘branch predictor’ but I’m not going to help you figure it out.
The UV line is a different system architecture than a cluster because it has shared memory and cache coherency between all of its sockets. It is fundamentally different than the systems SGI had a decade go where those quotes originated from. Here is my challenge to you: can you show that the UV 2000 is not a scale up system? I’ve provided links and video where it clearly is but have you provided anything tangible to counter it? (Recycling a 10 year old link about different SGI system to claim otherwise continues to be just deceptive.)
As mentioned by me and others before, Scale MP has nothing to do with the UV 2000. It is relevant to that system. Every time you bring it up it is shifting the discussion to something that does not matter in the context of the UV2000.
“Again, SAP HANA is a clustered database, designed to run on scale-out servers. Oracle TimesTen is a nische database that is used for in-memory analytics, not used as a normal database - as explained in your own link. No one use scale-out servers to run databases, SAP, etc. No one. Please post ONE SINGLE occurence. You can not.”
The key thing you’re missing is that UV 2000 is a scale up server, not scale out. You have yet to demonstrate otherwise.
There are plenty of examples and I’ve provided some here. The US Post Office has a SGI UV2000 to do just that. Software like HANA and TimesTen are database products and are used by businesses for actual work and some businesses will do that work on x86 chips. Your continued denial of this is further demonstrated by your continual shifting of goal posts of what a database now is.
Enterprise databases are designed to run as a cluster anyway due to the necessity to fail over in the event of a hardware issue. That is how high availability is obtained: if the master server dies then a slave takes over transparently to outside requests. It is common place to order large database servers in sets of two or three for this very reason. Of course I’ve pointed this out to you before: http://www.anandtech.com/comments/7757/quad-ivy-br...
“On scale-up servers, you need to redesign everything for the scalability problem - that is why they are extremely expensive. 32-socket scale up servers cost many times the price of 256-socket scale-out clusters.”
I agree and that is why the UV 2000 has the NUMALink6 chips inside: that is the coherent fabric that enables the x86 chips to scale beyond 8 sockets. That is SGI’s solution to the scalability problem. Fundamentally this is the same topology Oracle uses with their Bixby interconnect to scale up their SPARC servers. This is also why adding additional sockets to the UV2000 is not linear: more NUMALink6 node controllers are necessary as socket count goes up. It is a scale up server.
“Banks would be very happy if they could buy a cheap 256-socket SGI UV2000 server with 64TB RAM, to replace a single 16- or 32-socket server with 8-16TB RAM that costs many times more. The Unix high end market would die in an instant if cheap 256-socket scale-out clusters could replace 16- or 32-socket scale-up servers. And facts are: NO ONE USE SCALE-OUT SERVERS FOR BUSINESS SOFTWARE! Why pay many times more if investment banks could buy cheap x86 clusters? You havent thought of that?”
Choosing an enterprise system is not solely about performance, hardware platform and cost. While those three variables do weigh on a purchase decision, there are other variables that matter more. Case in point: RAS. Systems like the P595 have far more reliability features than the UV2000. Features like lock step can matter to large institutions where any downtime is unacceptable to the potential tune of tens of millions of dollars lost per minute for say an exchange.
Similarly there are institutions who have developed their own software on older Unix operating systems. Porting old code from HPUX, OpenVMS, etc. takes time, effort to validate and money to hire the skill to do the port. In many cases, it has been simpler to pay extra for the hardware premium and continue using the legacy code.
For entities like the US Post Office, they could actually tolerate far more downtime as their application load is not as time sensitive nor carries the same financial burden for the downtime. A SGI UV system would be fine in this scenario.
“You are wrong again. The top record is held by a SPARC server, and the record is ~850.000 saps.
download.sap.com/download.epd?context=40E2D9D5E00EEF7C569CD0684C0B9CF192829E2C0C533AA83C6F5D783768476B”
OK, 5 times the number of sockets, 4.5 times the number of cores for 3x times the work. Still not very impressive in terms of scaling. My point still stands.
Let me ask you again, for the umpteen time: CAN YOU POST ANY GOOD x86 SAP SCORE??? I talk about close to a million saps, not 200-300.000. If you can not post any such x86 scores, then I suggest you just sh-t up and stop FUD. You are getting very tiresome with your ignorance. We have talked about this many times, and still you claim that SGI UV2000 can replace Unix/Mainframe servers - well if they can, show us proof, show us links where they do that! If there are no evidence that x86 can run large databases or large SAP configurations, etc, stop FUD will you?????
A score of 320K is actually pretty good for the socket and core count. It is also in the top 10. There are numerous SAP scores below that mark from various Unix vendors from the likes of Oracle/Sun, IBM and HP. I’ve also shown links where HANA and TimesTen are used on UV2000 systems with examples like the US Post Office using them. Instead, you’re ignoring my links and shifting the goal posts further.
Brutalizer - Wednesday, May 20, 2015 - link
@KevinGYou are confusing things. First of all, normal databases are not scale-out, they are scale-up. Unless you design the database as a clustered scale-out (SAP Hana) to run across many nodes (which is very difficult to do, it is hard to guarantee data integrity in a transaction heavy environment with synchronizing data, roll back, etc etc, se my links). Sure, databases can run in a High Availability configuration but that is not scale-out. If you have one database mirroring everything in two nodes does not mean it is scale-out, it is still scale-up. Scale-out is distributing the workload across many nodes. You should go and study the subject before posting inaccurate stuff.
http://global.sap.com/corporate-en/news.epx?PressI...
"With the scale out of SAP HANA, we see almost linear improvement in performance with additional computing nodes," said Dr. Vishal Sikka, member of the SAP Executive Board, Technology & Innovation. ...The business value of SAP HANA was demonstrated recently through scalability testing performed by SAP on SAP HANA with a 16-node server cluster."
Do you finally understand that HANA is clustered? I dont know how many times I must explain this?
.
"...Software like HANA and TimesTen are database products and are used by businesses for actual work and some businesses will do that work on x86 chips. Your continued denial of this is further demonstrated by your continual shifting of goal posts of what a database now is...."
What denial? I have explained many times that SAP Hana is clustered. And running a database as mirror for High Availability, is not scale-out. It is still scale-up. And I have explained that Oracle TimesTen is a "database" used for queries, not used as a normal database as explained in your own link. Read it again. It says that TimesTen is only used for fraud detection, not used as a normal database storing and altering information, locking rows, etc etc. Read your link again. It is only used for quering data, just like a DataWare House.
In Memory Databases often don't even have locking of rows, as I showed in links. That means they are not meant for normal database use. It is stupid to claim that a "database" that has no locking, can replace a real database. No, such "databases" are mainly used to query information, not for altering data. What is so difficult to understand here?
.
"...OK, 5 times the number of sockets, 4.5 times the number of cores for 3x times the work. Still not very impressive in terms of scaling. My point still stands..."
What is your point? That there are no suitable x86 servers out there for extreme SAP workloads? That, if you want high SAP score, you need to go to a 16- or 32-socket Unix server? That x86 servers will not do? SAP and business software is very hard to scale, as SGI explained to you, as the code branches too much. So it is outright stupid when you claim that SPARC has bad scaling, as it scales up to close to a million saps. How much does x86 servers scale? Up to a few 100.000 saps? Geee, you know, x86 scales much better than SPARC. What are you thinking? Are you thinking? How can anything that scales up to 32-sockets and close to a million saps not be impressive in comparison to x86 and much less saps? Seriously? O_o
Seriously, what is it that you don't understand? Can you show us a good scaling x86 benchmark that rivals, or outperforms large SPARC servers? Can you just post one single x86 benchmark close to the top SPARC benchmarks? Use scale-out or scale-up x86 servers, just post one single x86 benchmark. Where are the SGI UV2000 sap benchmarks, as you claim SGI are scale-up, which means they can replace any 16- or 32-socket Unix server? Surely a 256-socket SGI UV2000 must be faster than 32-socket Unix server on sap - according to your FUD? Why are there no top x86 sap benchmarks? Why are you ducking this question - why dont you post any links and prove that SGI UV2000 can replace Unix servers? Why are you FUDing?
Kevin G - Wednesday, May 20, 2015 - link
@Brutalizer“You are confusing things. First of all, normal databases are not scale-out, they are scale-up. Unless you design the database as a clustered scale-out (SAP Hana) to run across many nodes (which is very difficult to do, it is hard to guarantee data integrity in a transaction heavy environment with synchronizing data, roll back, etc etc, se my links). Sure, databases can run in a High Availability configuration but that is not scale-out. If you have one database mirroring everything in two nodes does not mean it is scale-out, it is still scale-up. Scale-out is distributing the workload across many nodes. You should go and study the subject before posting inaccurate stuff.”
SAP HANA is primarily scale up but it can scale out if necessary. https://blogs.saphana.com/2014/12/10/sap-hana-scal...
In fact, that link has this quote from SAP themselves under the heading ‘How does Scale-up work?’: “SGI have their SGI UV300H appliance, available in building blocks of 4-sockets with up to 8 building blocks to 32 sockets and 8TB for analytics, or 24TB for Business Suite. They use a proprietary connector called NUMAlink, which allows all CPUs to be a single hop from each other.”
If you read further, you’ll see that SAP recommends scaling up before scaling out with HANA. That article, if you bother to read it, also indicates how they resolved the coherency problem so that it can be both scale up and scale out.
Though if you really wanted an example of a clustered RMDBS, then the main Oracle database itself can run across a cluster via Oracle RAC. That is as in your own words below ‘normal’ of a database as you can get. http://www.oracle.com/us/products/database/options...
IBM’s DB2 can also run in a clustered mode where all nodes are active in transaction processing.
“I have explained many times that SAP Hana is clustered. And running a database as mirror for High Availability, is not scale-out. It is still scale-up. And I have explained that Oracle TimesTen is a "database" used for queries, not used as a normal database as explained in your own link.”
You are shifting further and further away from the point which was that large x86 based are used for actual production work using databases. This is also highlighted by your continued insistence that SAP HANA and TimesTen are not 'normal' databases and thus don’t count for some arbitrary reason.
“In Memory Databases often don't even have locking of rows, as I showed in links. That means they are not meant for normal database use. It is stupid to claim that a "database" that has no locking, can replace a real database. No, such "databases" are mainly used to query information, not for altering data. What is so difficult to understand here?”
I think you need to re-read that link you provided as it clearly had the word *some* in the quote you provided about locking. If you were to actually comprehend that paper, you’d realize that locking and in-memory databases are totally independent concepts.
“What is your point? That there are no suitable x86 servers out there for extreme SAP workloads? “That, if you want high SAP score, you need to go to a 16- or 32-socket Unix server?[ … ]So it is outright stupid when you claim that SPARC has bad scaling, as it scales up to close to a million saps. How much does x86 servers scale? Up to a few 100.000 saps? Geee, you know, x86 scales much better than SPARC. What are you thinking? Are you thinking? How can anything that scales up to 32-sockets and close to a million saps not be impressive in comparison to x86 and much less saps? Seriously? O_o”
Yes, being able to do a third of the work with one fifth of the resources is indeed better scaling and that’s only with an 8 socket system. While true that scaling is not going to be linear as socket count increases, it would be easy to predict that a 32 socket x86 system would take the top spot. As for the Fujitsu system itself, a score of ~320K is in the top 10 were the fastest system doesn’t break a million. It also out performs many (but obviously not all) 16 and 32 socket Unix servers. Thus I would call it suitable for ‘extreme’ workloads.
“That x86 servers will not do? SAP and business software is very hard to scale, as SGI explained to you, as the code branches too much.”
To quote the Princess Bride “You keep using that word. I do not think it means what you think it means.” Define code branches in context of increasing socket count for scaling.
Brutalizer - Thursday, May 21, 2015 - link
Seriously, I dont get it, what is so difficult to understand? Have you read your links?For SGI, they have UV2000 scale-out 256-socket servers and the SGI UV300H which only goes to 32-sockets. I suspect UV300H is a scale-up server, trying to compete with POWER and SPARC. This means that SGI UV2000 can not replace a UV300H. This is the reason SGI manufactures UV300H, instead of offering a small 32-socket UV2000 server. But now SGI sells UV2000 and UV300H, targeting different markets. The performance of UV300H sucks big time compared to POWER and SPARC, because otherwise we would see benchmarks all over the place as SGI claimed the crown. But SGI has no top records at all. And we all know that x86 does scale-up bad, which means performance sucks on SGI UV300H.
.
SAP Hana is designed to run on a cluster, and therefore it is a scale-out system. If you choose to run Hana on a single node (and scale-up by adding cpus and RAM) does not make Hana non clustered. If you claim that "Hana is not a clustered system, because you can scale-up on a single node" then you have not really understood much about scale-out or scale-up.
SAP says in your own link, that you should keep adding cpus and RAM to your single node as far as possible, and when you hit the limit, you need to switch to a cluster. And for x86, the normal limit, is 8-socket scale-up servers. (The 32-socket SGI UV300H has so bad performance that no one use it - there are no SAP or other ERP benchmarks nowhere. It is worthless vs Unix).
And in your own link:
https://blogs.saphana.com/2014/12/10/sap-hana-scal...
SAP says that Hana clustered version is only used for reading data, for gathering analytics. This scales exceptionally well and can be run on large clusters. SAP Hana also has a non clustered version for writing and storing business data which stops at 32 sockets because of complex synching.
There are mainly two different use cases for SAP Hana; "SAP BW and Analytics", and "SAP Business Suite". As I explained earlier talking about Oracle TimesTen, BusinessWarehouse and Analytics is used for reading data: gathering data, to make light queries, not to store and alter data. The data is fix, so no locking of rows are necessary, no complex synchronization between nodes. That is why DataWare House and other Business Intelligence stuff, runs great on clusters.
OTOH, Business Suite is another thing, it is used to record business work which alters data, it is not used as a analysis tool. Business Suite needs complex locking, which makes it unsuitable to run on clusters. It is in effect, a normal database used to write data. So this requires a scale-up server, it can not run on scale-out clusters because of complex locking, synching, code branches everywhere, etc. Now let me quote your own link from SAP:
https://blogs.saphana.com/2014/12/10/sap-hana-scal...
"...Should you scale-up, or out Business Suite?: The answer for the SAP Business Suite is simple right now: you HAVE to scale-up. This advice might change in future, but even an 8-socket 6TB system will fit 95% of SAP customers, and the biggest Business Suite installations in the world can fit in a SGI 32-socket with 24TB..."
Note that SAP does not say you can run Business Suite on a 256-socket UV2000. They explicitly say SGI 32-socket servers is the limit. Why? Do you really believe a UV2000 can replace a scale-up server??? Even SAP confirms it can not be done!!
"...Should you scale-up, or out BW and Analytics?...My advice is to scale-up first before considering scale-out....If, given all of this, you need BW or Analytics greater than 2TB, then you should scale-out. BW scale-out works extremely well, and scales exceptionally well – better than 16-socket or 32-socket scale-up systems even....Don’t consider any of the > 8-socket systems for BW or Analytics, because the NUMA overhead of those sockets is already in effect at 8-sockets (you lose 10-12% of power, or thereabouts). With 16- and 32-sockets, this is amplified slightly, and whilst this is acceptable for Business Suite, but not necessary for BW..."
SAP says that for analytics, avoid 16- or 32-sockets because you will be latency punished. This punishment is not necessary for analytics, because you dont need complex synching when only reading data in a cluster. Reading data "scales exceptionally well". SAP also says that for Business Suite, when you write data, the latency punishment is unavoidable and you must accept it, which means you can as well as go for one 16- or 32-socket server. Diminishing returns. Scaling is difficult.
There you have it. SAP Hana clustered version is only used for reading data, for analytics. This scales exceptionally well. SAP Hana also has a non clustered version for writing and storing business data which stops at 32 sockets. Now, can you stop your FUD? Stop say that scale-out servers can replace scale-up servers. If you claim they can, where are your proofs? Links? Nowhere. "Trust me on this, I will not prove this, you have to trust me". That is pure FUD.
.
Again, SAP Hana and TimesTen is only used for gathering and reading data. OTOH, normal databases are used for altering data, which needs heavy locking algorithms.
"...You are shifting further and further away from the point which was that large x86 based are used for actual production work using databases. This is also highlighted by your continued insistence that SAP HANA and TimesTen are not 'normal' databases and thus don’t count for some arbitrary reason..."
.
"...If you were to actually comprehend that paper, you’d realize that locking and in-memory databases are totally independent concepts...."
Again, in memory databases are mainly used for reading data. This means that they dont need locking of rows or other synchronizing features which are required for editing data. You only need to lock when you need to alter data, so that no one else changes the same data as you. Hence, normal databases always have elaborate locking algorithms, which is why you can only run databases on scale-up servers. In memory databases often dont even have locks - which means they are designed to only read data, which makes them excellent at clusters. Why is this concept so difficult to understand? Have you studied comp sci at all at the university?
.
"...Yes, being able to do a third of the work with one fifth of the resources is indeed better scaling and that’s only with an 8 socket system. While true that scaling is not going to be linear as socket count increases, it would be easy to predict that a 32 socket x86 system would take the top spot. As for the Fujitsu system itself, a score of ~320K is in the top 10 were the fastest system doesn’t break a million. It also out performs many (but obviously not all) 16 and 32 socket Unix servers. Thus I would call it suitable for ‘extreme’ workloads...."
This must be the weirdest thing I have heard for a while. On the internet, there are strange people. Look, scaling IS difficult. That means as you add more resources, the benefit will be smaller and smaller. That is why scaling is difficult. At some point, you can not just add more and more resources. If you were a programmer you would have known. But you are not, everybody can tell from your flawed logic. And you have not studied comp sci either. Sigh. You are making it hard for us with your absolute ignorance. I need to learn you what you should have learned at uni.
Fujitsu SPARC 40-socket M10-4S gets 844,000 saps. It uses a variant as the same highly performant SPARC 16-core cpu as in the K supercomputer, no 5 in top500.
Fujitsu SPARC 32-socket M10-4S gets 836.000 saps. When you add 8 sockets to a 32-socket server, you gain 1000 sap per each cpu.
Fujitsu SPARC 16-socket M10-4S gets 448.000 saps. When you add another 16 sockets you gain 24.000 sap per socket.
See? You go from 16-sockets to 32-sockets and gain 24.000 sap per cpu. Then you go from 32-sockets to 40-sockets and gain 1,000 sap per cpu. Performance has dropped 96% per cpu!!!
And if you went from 40 sockets to 48 sockets I guess you gain 100 saps per cpu. And if you go up to 64 sockets I guess you gain 10 saps per cpu. That is the reason there are no 64-socket M10-4S benchmarks, because the score would roughly be the same as a 40-socket server. SCALING IS DIFFICULT.
Your fantasies about the x86 sap numbers above are just ridiculous. As ridiculous as your claim "SPARC does not scale" - well, it scales up to 40-sockets. And x86 scales up to 8-sockets. Who has bad scaling? x86 or SPARC? I dont get it, how can you even think so flawed?
.
And your claim that "8-socket E7 server is in the top 10 of SAP benchmarks therefore 300.000 sap is a top notch score" is also ridiculous. There are only SPARC and POWER, there are no other good scaling servers out there. After a few SPARC and POWER, you only have x86, which comes in at the very bottom, far far away from the top Unix servers. That does not make x86 a top notch score.
Again, post a x86 sap benchmarks close to a million saps. Do it, or stop FUDing. x86 has no use in the high end scale-up server market as we can see from your lack of links.
POST ONE SINGLE X86 BENCHMARK RIVALING OR OUTPERFORMING SPARC!!! Do it. Just one single link. Prove your claim, that SGI UV2000 with 256 sockets can replace a POWER or SPARC server in business software. Prove it. If you can not, you are lying. Are you a liar? And FUDer?
Kevin G - Saturday, May 23, 2015 - link
@Brutalizer“Seriously, I dont get it, what is so difficult to understand? Have you read your links?”
I have and I understand them rather well. In fact, I think I’ve helped you understand several of my points due to your changing positions as I’ll highlight below.
“For SGI, they have UV2000 scale-out 256-socket servers and the SGI UV300H which only goes to 32-sockets. I suspect UV300H is a scale-up server, trying to compete with POWER and SPARC. This means that SGI UV2000 can not replace a UV300H. This is the reason SGI manufactures UV300H, instead of offering a small 32-socket UV2000 server. But now SGI sells UV2000 and UV300H, targeting different markets. The performance of UV300H sucks big time compared to POWER and SPARC, because otherwise we would see benchmarks all over the place as SGI claimed the crown. But SGI has no top records at all. And we all know that x86 does scale-up bad, which means performance sucks on SGI UV300H.”
The UV 2000 can replace the UV300H if necessary as they’re both scale up. The reason you don’t see SAP HANA benchmarks with the 32 socket UV300H is simple: while it is expected to pass the UV300H is still going through validation. The UV 2000 has no such certification and that’s a relatively big deal for support from SAP customers (it can be used for nonproduction tasks per SAP’s guidelines). The UV 3000 coming later this year may obtain it but they’d only go through the process if a customer actually asks for it from SGI as there is an associated cost to doing the tests.
“SAP Hana is designed to run on a cluster, and therefore it is a scale-out system. If you choose to run Hana on a single node (and scale-up by adding cpus and RAM) does not make Hana non clustered. If you claim that "Hana is not a clustered system, because you can scale-up on a single node" then you have not really understood much about scale-out or scale-up.”
I’ll take SAP’s own words from my previous link over your assertions. HANA is primarily scale up with the option to scale out for certain workloads. It was designed from the ground up to do *both* per SAP so that it is flexible based upon the workload you need it to run. There is nothing wrong with using the best tool for the job.
“OTOH, Business Suite is another thing, it is used to record business work which alters data, it is not used as a analysis tool. Business Suite needs complex locking, which makes it unsuitable to run on clusters. It is in effect, a normal database used to write data. So this requires a scale-up server, it can not run on scale-out clusters because of complex locking, synching, code branches everywhere, etc. “
Correct and that is what HANA does. The key point here is that x86 systems like the UV300H can be used for the business suite despite your continued claims that x86 does does scale up to perform such workloads.
“Note that SAP does not say you can run Business Suite on a 256-socket UV2000. They explicitly say SGI 32-socket servers is the limit. Why? Do you really believe a UV2000 can replace a scale-up server??? Even SAP confirms it can not be done!!”
The key point here is that you are *finally* admitting is that the UV 300H is indeed a scale up server. UV 2000 and UV 300H do share a common topology for interconnect. The difference between the NUMALink6 in the UV 2000 and the NUMALink7 in the UV 300H is mainly the latency involved with a slight increase in bandwidth between nodes. The UV300H only has one central NUMALink7 chip to ensure that latency is consistent between nodes but this limits scalability to 32 sockets. The UV 2000 uses several NUMALink6 nodes to scale up to 256 sockets but access latencies vary between the source and destination sockets due the additional hops between nodes. The future UV 3000 will be using the NUMALink7 chip to lower latencies but they will not be uniform as it will inherit the same node topology as the UV2000. Essentially if one system is scale up, so is the other. So yes, the UV 2000 is a scale up server and can replace the UV 300H if additional memory or processors are necessary. Sure the additional latencies between sockets will hurt the performance gains but the point is that you can get to that level by scaling upward with a x86 platform.
http://www.theplatform.net/2015/05/01/sgi-awaits-u...
http://www.enterprisetech.com/2014/03/12/sgi-revea...
Also I think it would be fair to repost this link that you originally provided: http://www.theregister.co.uk/2013/08/28/oracle_spa...
This link discusses the Bixby interconnect on SPARC M5 system and includes this quote for comparison about the topology: “This is no different than the NUMAlink 6 interconnect from Silicon Graphics, which implements a shared memory space using Xeon E5 chips”
“There you have it. SAP Hana clustered version is only used for reading data, for analytics. This scales exceptionally well. SAP Hana also has a non clustered version for writing and storing business data which stops at 32 sockets. Now, can you stop your FUD? Stop say that scale-out servers can replace scale-up servers. If you claim they can, where are your proofs? Links? Nowhere. "Trust me on this, I will not prove this, you have to trust me". That is pure FUD.”
Progress! Initially you were previously claiming that there were no x86 servers that scaled past 8 sockets that were used for business applications. Now you have finally accepted that there is a 32 socket x86 scale up server with the UV 300H as compared to your earlier FUD remarks here: http://www.anandtech.com/comments/9193/the-xeon-e7...
“Again, in memory databases are mainly used for reading data. This means that they dont need locking of rows or other synchronizing features which are required for editing data. You only need to lock when you need to alter data, so that no one else changes the same data as you. Hence, normal databases always have elaborate locking algorithms, which is why you can only run databases on scale-up servers. In memory databases often dont even have locks - which means they are designed to only read data, which makes them excellent at clusters. Why is this concept so difficult to understand? Have you studied comp sci at all at the university?”
Oh I have and one of my favorite courses was logic. My point here is that being an in-memory database and requiring locks are NOT mutually exclusive ideas as you’re attempting to argue. Furthermore the locking is not a requirement is a strict necessity for a write heavy transaction processing as long as there is a method in place to maintain data concurrency. Now for some examples.
ENEA AB is an in-memory database with a traditional locking mechanism for transactions: http://www.enea.com/Corporate/Press/Press-releases...
MonetDB doesn’t use a locking mechanism for write concurrency and started life out as a traditional disk based DB. (It has since evolved to add in-memory support.)
Microsoft’s Hekaton does fit the description of an in-memory database without a locking mechanism but is targeted at the OLTP market. There are other methods of maintaining data concurrency outside of locking and with memory being orders of magnitude faster than disk, more of these techniques are being viable. http://research.microsoft.com/en-us/news/features/...
“Fujitsu SPARC 40-socket M10-4S gets 844,000 saps. It uses a variant as the same highly
performant SPARC 16-core cpu as in the K supercomputer, no 5 in top500.
Fujitsu SPARC 32-socket M10-4S gets 836.000 saps. When you add 8 sockets to a 32-socket server, you gain 1000 sap per each cpu.
Fujitsu SPARC 16-socket M10-4S gets 448.000 saps. When you add another 16 sockets you gain 24.000 sap per socket.”
Actually if you looked at the details between these submissions, you should be able to spot why the 40 socket and 32 socket systems have very similar scores. Look at the clock speeds: the 40 socket system is running at 3 Ghz while the 32 socket system is running at 3.7 Ghz.
The 32 socket system also using a different version of the Oracle database than the 40 and 16 socket systems which could also impact results, especially depending on how well tuned each version was for the test.
Thus using these systems as means to determine performance scaling by adding additional sockets to a design is inherently flawed.
“Your fantasies about the x86 sap numbers above are just ridiculous. As ridiculous as your claim "SPARC does not scale" - well, it scales up to 40-sockets. And x86 scales up to 8-sockets. Who has bad scaling? x86 or SPARC? I dont get it, how can you even think so flawed?”
Well considering you finally accepted that a 32 socket x86 scale up systems exists earlier this post, I believe you need to revise that statement. Also the SGI UV 2000 is a scale up server that goes to 256 sockets.
“And your claim that "8-socket E7 server is in the top 10 of SAP benchmarks therefore 300.000 sap is a top notch score" is also ridiculous. There are only SPARC and POWER, there are no other good scaling servers out there. After a few SPARC and POWER, you only have x86, which comes in at the very bottom, far far away from the top Unix servers. That does not make x86 a top notch score.”
Go here:
http://global.sap.com/solutions/benchmark/sd2tier....
Sort by SAP score. Count down. As for 5/22/2015, the 9th highest score out of *789* submissions is this:
http://download.sap.com/download.epd?context=40E2D...
Then compare it to the 10th system on that very same list, a 12 socket POWER system:
http://download.sap.com/download.epd?context=40E2D...
Again, I would say x86 is competitive as an 8 socket machine is in the top 10 contrary to your claims that it could not compete.
You want a faster system, there are higher socket count x86 systems from SGI and HP.
Brutalizer - Sunday, May 24, 2015 - link
@KevinGYou claim you have studied "logic" at university, well if you have, it is obvious you did not complete the course because you have not understood anything of logic.
For instance, you claim "x86 that goes maximum to 8-sockets and ~300.000 saps has better scaling than SPARC that scales to 40 sockets and getting close to a million saps". This logic of yours is just wrong. Scalability is about how successfull a system is in tackling larger and larger workloads. From wikipedia article on "Scalability":
"...Scalability is the ability of a system... to handle a growing amount of work in a capable manner or its ability to be enlarged to accommodate that growth..."
QUESTION_A) If x86 stops at 8-sockets and ~300.000 saps vs SPARC stops at 40-sockets and ~850.000 saps - who is most capable of tackling larger and larger workloads? And still you insist in numerous posts that x86 is more scalable?? Que?
Have you problems understanding basic concepts? "There are no stupid people, only uninformed" - well, if you are informed by wikipedia and you still reject basic concepts, then you _are_ stupid. And above all, anyone versed in logic would change their mind after being proven wrong. As you dont change your mind after proven wrong, it is clear you have not understood any logic, which means you were a drop out on logic classes. The most probable is you never studied at uni because of your flawed reasoning ability. This is obvious, so dont lie about you studied any logic classes at uni. I have double Master's, one in math (including logic) and one in theoretical comp sci, so I can tell you know nothing about these subjects because you have proved numerous times you dont even understand basic concepts.
.
Another example of you not understanding basic concepts is when you discuss why customers choose extremely expensive IBM P595 Unix 32-sockets server costing $35 million, instead of a very cheap SGI cluster with 256-socket (which do have much higher performance). Your explanation why customers choose IBM P595? Because P595 has better RAS!!! That is so silly I havent bothered to correct this among all your silly misconceptions. It is well known that it is much cheaper and gives better RAS to scale-out than scale-up:
http://natishalom.typepad.com/nati_shaloms_blog/20...
"....Continuous Availability/Redundancy: You should assume that it is inevitable that servers will crash, and therefore having one big system is going to lead to a single point of failure. In addition, the recovery process is going to be fairly long which could lead to a extended down-time..."
Have you heard about Google? They have loads of money, and still choose millions of very cheap x86 servers because if any crashes, they just failover to another server. This gives much better uptime to have many cheap servers in a cluster, than one single large server that might crash. So, all customers prioritizing uptime would choose a cheap large x86 cluster, instead of a single very very expensive server. So this misconception is also wrong, customers dont choose expensive 32-socket Unix servers because of better uptime. Any cluster beats a single server when talking about uptime. So, now knowing this, answer me again on QUESTION_B) Why have not the market for high end Unix servers died immediately, if a cheap x86 scale-out cluster can replace any expensive Unix server? Why do customers choose to spend $millions on a single Unix server, instead of $100.000s on a x86 cluster? Unix servers are slow compared to a large x86 cluster, that is a fact.
.
I have shown that you gain less and less saps for every cpu you add, for 16-sockets SPARC M10-4S server you gain 24.000 saps for every cpu. And after 32-socket you gain only 1000 saps for every cpu you add up to 40-sockets M10-4S server.
To this you answer that the SPARC cpus are differently clocked, and the servers use different versions of the database - therefore I am wrong when I show that adding more and more cpus gives diminishing returns.
Ok, I understand what you are doing. For instance, the 16-socket M10-4S has 28.000 saps per socket, and the 32-socket M10-4S has 26.000 saps per socket - with exactly the same 3.7GHz cpu. Sure, the 32 socket used a newer and faster version of the database - and still gained less for every socket as it had more sockets i.e. scalability is difficult when you have a large number of sockets. Scaling small number of sockets is never a problem, you almost always gets linear performance in the beginning, and then it drops of later.
But, it does not matter much. If I showed you identical databases, you would say "but that scalability problem is restricted to SPARC, therefore you are wrong when you claim that adding cpus gives diminishing performance". And if I showed you that SPARC scales best on the market, you would say "then the scalability problem is in Solaris so you are wrong". And if I showed you that Solaris also scales best on the market you would make up some other excuse. It does not matter how many links I show you, your tactic is very ugly. Maybe the cpus dont come from the same wafer so the benchmarks are not comparable. And if I can prove they do, maybe the wafer differ a bit in different places. etc etc etc.
The point in having benchmarks is to compare between different systems, even though not everything is equal to 100%. Instead you extrapolate and try to draw conclusions. If you reject that premise and require that everything must be 100% equal, I can never prove anything with benchmarks or links. I am surprised you dont reject SPARC having close to a million saps because those saps are not 100% equal to x86 saps. The hard disks are different, they did not share the same disks. The current is different, etc.
Anyway, your ugly tactic forces me to prove my claim about "law of diminishing returns" by show you links instead. I actually try to avoid mathematics and comp sci, because many might not understand it, but your ugly tactic forces me to do it. Here you see that there actually is something called law of diminshing returns:
http://en.wikipedia.org/wiki/Amdahl%27s_law#Relati...
"...Each new processor you add to the system will add less usable power than the previous one. Each time you double the number of processors the speedup ratio will diminish, as the total throughput heads toward the limit of 1 / (1 - P)...."
So there you have it. You are wrong when you believe that scaling always occurs linearly.
You need to give an example where your claim is correct: show us a SAP server that runs on 8-sockets and when you go to 32-sockets the performance has increased 4x. You will not find any such benchmarks, because your misconception is not true. There is something called law of diminishing returns. Which you totally have missed, obviously.
.
"...The UV 2000 can replace the UV300H if necessary as they’re both scale up...."
It seems you claim that UV300H is basically a stripped down UV2000. Well, if the UV2000 really can replace the UV300H, why dont SGI just sell a smaller configuration, say a 32-socket UV2000 with only one NUMAlink6? This is QUESTION_C)
The most probable explanation is they are different servers targeting different workloads. UV2000 is scale-out and UV300H is scale-up. It does not make sense to manufacture different lines of servers, if they have the same use case. Have never thought about that?
As you strongly believe, and claim that UV2000 can replace UV300H, you should prove this. Show us links where anyone has done so. You do realize you can not just spew out things without backing claims up? That would be the very definition of FUD: "trust me on this, I will not prove this, but you will have to believe me. Yes, SGI UV2000 can replace a large Unix server, I will not show any links on this, you have to trust me" - that is actually pure FUD.
.
"...The reason you don’t see SAP HANA benchmarks with the 32 socket UV300H is simple: while it is expected to pass the UV300H is still going through validation....
...The UV 3000 coming later this year may obtain it but they’d only go through the process if a customer actually asks for it from SGI as there is an associated cost to doing the tests...."
QUESTION_D) Why have we never ever seen any SGI server on the sap benchmark list?
SGI claims they have the fastest servers on the market, and they have been selling 100s-socket server for decades (SGI Altix) but still no SGI server has never ever made it into the SAP top benchmark list. Why dont any customer run SAP on cheap SGI servers, and never have? This is related to QUESTION_B). Is it because SAP is a scale-up system and SGI only does scale-out clusters?
Show us a x86 benchmark close to a million saps. If you can not, stop saying that x86 is able to tackle the largest sap workloads - because it can not. If it can, you can show us benchmarks.
.
"...Correct and that is what HANA does. The key point here is that x86 systems like the UV300H can be used for the business suite despite your continued claims that x86 does [not] scale up to perform such workloads..."
But if I am wrong, then you can prove it, right? Show us ONE SINGLE LINK that supports your claim. If you are right, then there will be lot of links on the vast internet showing that customers replace large Unix servers with x86 clusters such as SGI UV2000 and saving lot of money and gaining performance in the process.
Show us ONE SINGLE link where a cheap SGI UV2000 or Altix or whatever SGI scale-out server replaces one very expensive high end Unix on SAP. During all these decades, one single customer must have existed that want to save millions by choosing cheap x86 servers? But there are no one. Why?
QUESTION_E) Why are there no such links nowhere on the whole internet?
Maybe it is not true that SGI UV2000 servers can do scale-up?
.
Regarding the SPARC interconnect Bixby: “This is no different than the NUMAlink 6 interconnect from Silicon Graphics, which implements a shared memory space using Xeon E5 chips”
There is a big difference! The Bixby stops at 32 sockets. Oracle that charges millions for large servers and tries to win business benchmarks such as database, SAP, etc - knows that if Oracle goes to 256 socket SPARC servers with Bixby, then business performance would suck. It would be a cluster. Unix and Mainframes have for decades scaled very well, and they have always stopped at 32-sockets or so. They could of course gone higher, but Big Iron targets business workloads, not HPC number crunching clustering. That is the reason you always see Big Iron on the top business benchmarks, and never see any HPC cluster. Bixby goes up to 96-sockets but Oracle will never release such a server, performance would be bad.
QUESTION_F) Small supercomputers (just a cluster of a 100 of nodes) are quite cheap in comparison to a single expensive 32-socket Unix server. Why do we never see supercomputers in top benchmarks for SAP and other business enterprise benchmarks? The business systems are very very expensive, and which HPC company would not want to earn easy peasy $millions by selling dozens of small HPC clusters to SAP installations? I know people that are SAP consultants, and large SAP installations can easily cost more than $100 millions. And also talking about extremely expensive database servers, why dont we see any small supercomputers for database workloads running Oracle? Why dont small supercomputers replace very expensive Unix servers in the enterprise business workloads?
Why have never ever a single customer on the whole internet, replaced business enterprise servers with a cheap small supercomputer? Why are there no such links nowhere?
.
"...Progress! Initially you were previously claiming that there were no x86 servers that scaled past 8 sockets that were used for business applications. Now you have finally accepted that there is a 32 socket x86 scale up server with the UV 300H as compared to your earlier FUD remarks here..."
Wrong again. I have never changed my mind. There are NO x86 servers that scales past 8-sockets used for business applications today. Sure, 16-sockets x86 servers are for sale, but no one use them. Earlier I showed links to Bull Bullion 16-socket x86 server. And I have known about 32-socket SGI x86 servers earlier.
The problem is that all x86 servers larger than 8-sockets - are not deployed anywhere. No customer are using them. There are no business benchmarks. I have also known about HP Big Tux experiment, it is a 64-socket Integrity (similar to Superdome) Unix server running Linux. But performance was so terribly bad, that cpu utilization under full load, under 100% full burn load - the cpu utilization was ~40% on 64-socket Unix server running Linux. So, HP never sold the Big Tux because it sucked big time. Just because there exists 16-sockets x86 servers such as Bull Bullion - does not mean anybody are using them. Because they suck big time. SGI have had large x86 servers for decades, and nobody have ever replaced large Unix servers with them. Nobody. Ever.
The largest in use for business workloads are 8-sockets. So, no, I have not changed my mind. The largest x86 servers used for business workloads are 8-sockets. Can you show us a single link with a customer using a 16-socket or 32-socket x86 server used to replace a high end Unix server? No you can not. Search the whole internet, there are no such links.
.
"...My point here is that being an in-memory database and requiring locks are NOT mutually exclusive ideas as you’re attempting to argue. Furthermore the locking is not a requirement is a strict necessity for a write heavy transaction processing as long as there is a method in place to maintain data concurrency...."
Jesus. "Locking is no requirement as long as there is another method to maintain data integrity"? How do you think these methods maintains data integrity? By locking of course! Deep down in these methods, they must make sure that only one alters the data. Two cpus altering the same data will result in data loss. And the only way to ensure they do not alter the same data, is by some sort of synchronization mechanism: one alters, and the other waits - that is, one locks the data before altering data. Making a locking signal is the only way to signal other cpus that certain data is untouchable at the moment! So, the other cpus reads the signal and waits. And if you have 100s of cpus, all trying to heavily alter data, chances increase some data is locked, so many cpus need to wait => performance drops. The more cpus, the higher the chance of waiting because someone else is locking the data. The more cpus you add in a transaction heavy environment -> performance drops because of locking. This is called "Law of diminishing returns". How in earth can you say that: locks are not necessary in a transaction heavy environment??? What do you know about parallel computing and comp sci??? Jesus you really do know much about programming or comp sci. O_o
Regarding in memory databases, some of them dont even have locking mechanisms, that is, no method of guaranteeing data integrity. The majority (all?) of them have only very crude basic locking mechanisms. On such "databases" you can not guarantee data integrity which makes them useless in an environment that alters data heavily - i.e. normal database usage. That is the reason in memory databases such as Oracle TimesTen are only used for reading data for analytics. Not normal database usage. A normal database stores and edits data. These can not alter data.
I ask again:
“There you have it. SAP Hana clustered version is only used for reading data, for analytics. This scales exceptionally well. SAP Hana also has a non clustered version for writing and storing business data which stops at 32 sockets. Now, can you stop your FUD? Stop say that scale-out servers can replace scale-up servers. If you claim they can, where are your proofs? Links? Nowhere."
So now you can read from SAP web site in your own link, that SAP Hana cluster which is in memory database is only used for data analytics read usage. And for the business suite, you need a scale-up server. So you are wrong again.
.
As you display such large ignorance, here is the basics about scale-up vs scale-out that you should read before trying to discuss this. Otherwise everything will be wrong and people will mistake you for being an stupid person, when instead you are just informed and have not studied the subject. Here they say that maintaining state in transaction heavy environments is fiendishly complex and can only be done by scaling up.
http://www.servercentral.com/scalability-101/
"....Not every application or system is designed to scale out. Issues of data storage, synchronization, and inter-application communication are critical to resolve.
To scale out, each server in the pool needs to be interchangeable. Another way of putting this is servers need to be “stateless”, meaning no unique data is kept on the server. For instance, an application server may be involved in a transaction, but once that transaction is complete the details are logged elsewhere – typically to a single database server.
For servers that must maintain state—database servers, for instance—scaling out requires they keep this state in sync amongst themselves. This can be straightforward or fiendishly complex depending on the nature of the state and software involved. For this reason, some systems may still need to scale up despite the benefits of scaling out
However, scaling up to ever-larger hardware poses some serious problems.
The larger a server gets, the more expensive it becomes. It’s more difficult to design a ten-core processor than a dual-core, and it’s more difficult to create a four-processor server than one with a single CPU. As such, the cost for a given amount of processing power tends to increase as the size of the server increases. Eventually, as you reach into the largest servers, the number of vendors decreases and you can be more locked into specific platforms.
As the size of the server increases, you’re placing more and more computing resources into a single basket. What happens if that server fails? If it’s redundant, that’s another large node you have to keep available as insurance. The larger the server, the more you’re exposed for failure.
Most systems only scale up so far before diminishing returns set in. One process may have to wait on another, or has a series of tasks to process in sequence. The more programs and threads that run sequentially rather than in parallel, the less likely you’ll be to take advantage of the additional processor power and memory provided by scaling up." - Law of diminishing returns!!!!
.
I am not going to let you get away this time. We have had this discussion before, and everytime you come in an spew your FUD without any links backing up your claims. I have not bothered correcting your misconceptions before but I am tired of your FUD, in every discussion. We WILL settle this, once and for all. You WILL back up your claims with links, or stop FUD. And in the future, you will know better than FUDing. Period.
Show us one single customer that has replaced a single Unix high end server with a SGI scale-out server, such as UV2000 or Altix or ScaleMP or whatever. Just one single link.
Kevin G - Monday, May 25, 2015 - link
@Brutalizer“For instance, you claim "x86 that goes maximum to 8-sockets and ~300.000 saps has better scaling than SPARC that scales to 40 sockets and getting close to a million saps". This logic of yours is just wrong. Scalability is about how successfull a system is in tackling larger and larger workloads."
And if you can do the same work with less resources, scalability is also better as the overhead is less. Say if you want to increase performance to a given level, x86 systems would require fewer additional sockets to do it and thus lower overhead that reduces scalability.
“QUESTION_A) If x86 stops at 8-sockets and ~300.000 saps vs SPARC stops at 40-sockets and ~850.000 saps - who is most capable of tackling larger and larger workloads? And still you insist in numerous posts that x86 is more scalable?? Que?”
Actually the limits you state are flawed on both the x86 *AND* SPARC sides. Oracle can go to a 96 socket version of the M6 if they want. Even though you refuse to acknowledge it, the UV 2000 is a scale up server that goes to 256 sockets. Last I checked, 256 > 96 in terms of scalability. However socket count is only one aspect of performance but when the Xeon E5v2’s and E7v3’s are out running the SPARC chips in the M6 on a per core and per socket basis, it would be logical to conclude that an UV 2000 system would be faster and it wouldn’t even need all 256 sockets to do so.
“Another example of you not understanding basic concepts is when you discuss why customers choose extremely expensive IBM P595 Unix 32-sockets server costing $35 million, instead of a very cheap SGI cluster with 256-socket (which do have much higher performance). Your explanation why customers choose IBM P595? Because P595 has better RAS!!! That is so silly I havent bothered to correct this among all your silly misconceptions. It is well known that it is much cheaper and gives better RAS to scale-out than scale-up:”
My previous statements on this matter are perfectly in-line with the quote you’ve provided. So I’ll just repeat myself “That is how high availability is obtained: if the master server dies then a slave takes over transparently to outside requests. It is common place to order large database servers in sets of two or three for this very reason.” And then you scoffed at that statement but now you are effectively using your own points against yourself now. http://anandtech.com/comments/9193/the-xeon-e78800...
“Have you heard about Google? They have loads of money, and still choose millions of very cheap x86 servers because if any crashes, they just failover to another server. This gives much better uptime to have many cheap servers in a cluster, than one single large server that might crash. So, all customers prioritizing uptime would choose a cheap large x86 cluster, instead of a single very very expensive server. So this misconception is also wrong, customers dont choose expensive 32-socket Unix servers because of better uptime. Any cluster beats a single server when talking about uptime. So, now knowing this, answer me again on QUESTION_B) Why have not the market for high end Unix servers died immediately, if a cheap x86 scale-out cluster can replace any expensive Unix server? Why do customers choose to spend $millions on a single Unix server, instead of $100.000s on a x86 cluster? Unix servers are slow compared to a large x86 cluster, that is a fact.”
No surprise that you have forsaken your database arguments here as that would explain the differences between what Google is doing with their massive x86 clusters and the large 32 socket servers: the workloads are radically different. For Google search, the clusters of x86 system are front end web servers and back end application servers that crawl through Google’s web cache to provide search result. Concurrency here isn’t an issue as the clusters are purely reading from the web index so scaling out works exceptionally well for this workload. However there are some workloads that are best scale up due to the need to maintain concurrency like OLTP databases which we were previously discussing. So we should probably get back on topic instead of shifting further and further away.
I’ve also given another reason before why large Unix systems will continue to exist today: “Similarly there are institutions who have developed their own software on older Unix operating systems. Porting old code from HPUX, OpenVMS, etc. takes time, effort to validate and money to hire the skill to do the port. In many cases, it has been simpler to pay extra for the hardware premium and continue using the legacy code.” http://anandtech.com/comments/9193/the-xeon-e78800...
“I have shown that you gain less and less saps for every cpu you add, for 16-sockets SPARC M10-4S server you gain 24.000 saps for every cpu. And after 32-socket you gain only 1000 saps for every cpu you add up to 40-sockets M10-4S server.”
All you have shown is a horribly flawed analysis since the comparison was done between systems with different processor clock speeds. Attempting to determine the scaling of additional sockets between a system with 3.0 Ghz processors and another 3.7 Ghz processor isn’t going to work as the performance per socket is inherently different due to the clock speeds involved. This should be obvious.
“The point in having benchmarks is to compare between different systems, even though not everything is equal to 100%. Instead you extrapolate and try to draw conclusions. If you reject that premise and require that everything must be 100% equal, I can never prove anything with benchmarks or links. I am surprised you dont reject SPARC having close to a million saps because those saps are not 100% equal to x86 saps. The hard disks are different, they did not share the same disks. The current is different, etc.”
I reject your scaling comparison because to determine scaling by adding additional sockets, the only variable you want to change is just the number of sockets in a system.
For SAP scores as a whole, the comparison is raw performance, not specifically how that performance is obtained. Using different platforms here is fine as long as they perform the benchmark and validated.
“Anyway, your ugly tactic forces me to prove my claim about "law of diminishing returns" by show you links instead. I actually try to avoid mathematics and comp sci, because many might not understand it, but your ugly tactic forces me to do it. Here you see that there actually is something called law of diminshing returns [. . .] So there you have it. You are wrong when you believe that scaling always occurs linearly.”
Citation please where I stated that performance scales linearly. In fact, I can quote myself twice in this discussion where I’ve stated that performance *does not* scale linearly. “While true that scaling is not going to be linear as socket count increases,” from http://anandtech.com/comments/9193/the-xeon-e78800... and “This is also why adding additional sockets to the UV2000 is not linear: more NUMALink6 node controllers are necessary as socket count goes up.” from http://anandtech.com/comments/9193/the-xeon-e78800...
So please stop the idea that performance scales linearly as it is just dishonest on your part.
“It seems you claim that UV300H is basically a stripped down UV2000. Well, if the UV2000 really can replace the UV300H, why dont SGI just sell a smaller configuration, say a 32-socket UV2000 with only one NUMAlink6?
They do. it is the 16 socket version of the UV 2000. I believe you have missed the ‘up to’ part of scaling up to 256 sockets. The UV 300H came about mainly due to market segmentation due to the lower latency involved by reducing the number of hops between sockets. By having a system with a more uniform latency, the scaling is better as socket count increases.
“This is QUESTION_C) The most probable explanation is they are different servers targeting different workloads. UV2000 is scale-out and UV300H is scale-up. It does not make sense to manufacture different lines of servers, if they have the same use case. Have never thought about that?”
Or the answer could simply be that the UV 2000 is a scale up server. Have you thought about that? I’ve given evidence before that the UV 2000 is a scale up server. I’ll repost again:
https://www.youtube.com/watch?v=lDAR7RoVHp0 <- shows how many processors and sockets that are on a single system running a single instance of Linux
https://www.youtube.com/watch?v=KI1hU5g0KRo <- explains the topology and how it is able to have cache coherency and shared memory making it a single large SMP system.
So far you have no provided anything that indicates that UV 2000 is a scale-out server as you claim.
“QUESTION_D) Why have we never ever seen any SGI server on the sap benchmark list?
SGI claims they have the fastest servers on the market, and they have been selling 100s-socket server for decades (SGI Altix) but still no SGI server has never ever made it into the SAP top benchmark list. Why dont any customer run SAP on cheap SGI servers, and never have? This is related to QUESTION_B). Is it because SAP is a scale-up system and SGI only does scale-out clusters?”
SGI has only been offering large scale up x86 servers for a few years starting with the UV 1000 in 2010. The main reason is that such a configuration would not be supported by SAP in production. In fact, when it comes to Xeons, only the E7 and older 7000 series get certified in production. The UV 2000 interestingly enough uses Xeon E5v2 chips.
“Show us a x86 benchmark close to a million saps. If you can not, stop saying that x86 is able to tackle the largest sap workloads - because it can not. If it can, you can show us benchmarks.”
This is again a shifting of the goal posts as initially you wanted to see an x86 system that simply could compete. So initially I provided a link to the Fujitsu system in the top 10. I would consider an 8 socket x86 system in the top 10 out of 789 systems that ran that benchmark as competitive. If wanted to, there are x86 systems that scale up further for additional performance.
“But if I am wrong, then you can prove it, right? Show us ONE SINGLE LINK that supports your claim. If you are right, then there will be lot of links on the vast internet showing that customers replace large Unix servers with x86 clusters such as SGI UV2000 and saving lot of money and gaining performance in the process.”
I’ll just repost this then: http://www.theplatform.net/2015/05/01/sgi-awaits-u...
The big quote from the article: “CEO Jorge Titinger said that through the end of that quarter SGI had deployed UV 300H machines at thirteen customers and system integrators, and one was a US Federal agency that was testing a move to convert a 60 TB Oracle database system to a single instance of UV running HANA.”
“There is a big difference! The Bixby stops at 32 sockets. Oracle that charges millions for large servers and tries to win business benchmarks such as database, SAP, etc - knows that if Oracle goes to 256 socket SPARC servers with Bixby, then business performance would suck. It would be a cluster.[. . .] Bixby goes up to 96-sockets but Oracle will never release such a server, performance would be bad.”
So using the Bixby interconnect to 32 socket is not a cluster but then scaling to 96 sockets with Bixby is a cluster? Sure performance gains here would be far from linear due to additional latency overhead between sockets but the system would still be scale up as memory would continued to be shared and cache coherency maintained. Those are the two big factors which determine if a system is scale up SMP device or a cluster of smaller systems. Your distinction between what is a cluster and what is scale up is apparently arbitrary as you’ve provided absolutely no technical reason.
“QUESTION_F) [. . .]Why have never ever a single customer on the whole internet, replaced business enterprise servers with a cheap small supercomputer? Why are there no such links nowhere?”
People like using the best tool for the job. Enterprise workloads benefit heavily from a shared memory space and cache coherent architectures for concurrency. This is why scale-up servers are generally preferred for business workloads (though there are exceptions).
“Wrong again. I have never changed my mind. There are NO x86 servers that scales past 8-sockets used for business applications today. Sure, 16-sockets x86 servers are for sale, but no one use them. Earlier I showed links to Bull Bullion 16-socket x86 server. And I have known about 32-socket SGI x86 servers earlier.”
Indeed you have. “The largest x86 servers are all 8 sockets, there are no larger servers for sale and have never been.” was said here http://anandtech.com/comments/9193/the-xeon-e78800... and now you’re claiming you’ve known about 16 socket x86 servers from Bull and earlier 32 socket x86 SGI servers. These statements made by you are clearly contradictory.
“The largest in use for business workloads are 8-sockets. So, no, I have not changed my mind. The largest x86 servers used for business workloads are 8-sockets. Can you show us a single link with a customer using a 16-socket or 32-socket x86 server used to replace a high end Unix server? No you can not. Search the whole internet, there are no such links.
At the launch HP’s x86 based SuperDome X included a customer name, Cerner. ( http://www8.hp.com/us/en/hp-news/press-release.htm... )
A quick bit of searching turned put that they used HPUX and Itanium systems before.
( http://www.cerner.com/About_Cerner/Partnerships/HP... )
“Jesus. "Locking is no requirement as long as there is another method to maintain data integrity"? How do you think these methods maintains data integrity? By locking of course! Deep down in these methods, they must make sure that only one alters the data.”
The key point, which you quote, is to maintain concurrency. Locking is just a means to achieve that goal but there are others. So instead of resorting to personal attacks as you have done, I’ll post some links to some non-locking concurrency techniques:
http://en.wikipedia.org/wiki/Multiversion_concurre...
http://en.wikipedia.org/wiki/Optimistic_concurrenc...
http://en.wikipedia.org/wiki/Timestamp-based_concu...
These other techniques are used in production systems. In particular Microsft’s Hekaton as part of SQL Server 2014 uses multi version concurrency control which I previously provided a link to.
“So now you can read from SAP web site in your own link, that SAP Hana cluster which is in memory database is only used for data analytics read usage. And for the business suite, you need a scale-up server. So you are wrong again.”
How so? The UV 300H works fine by your admission for the HANA business suite as it is a scale up server. We are in agreement on this!
“I am not going to let you get away this time. We have had this discussion before, and everytime you come in an spew your FUD without any links backing up your claims. I have not bothered correcting your misconceptions before but I am tired of your FUD, in every discussion. We WILL settle this, once and for all. You WILL back up your claims with links, or stop FUD. And in the future, you will know better than FUDing. Period.”
Fine, I accept your surrender.
“Show us one single customer that has replaced a single Unix high end server with a SGI scale-out server, such as UV2000 or Altix or ScaleMP or whatever. Just one single link.”
The Institute of Statistical Mathematics in Japan replaced their Fujitsu M9000 running Solaris with UV 2000’s running Linux:
http://virtualization.sys-con.com/node/2874817
http://www.ism.ac.jp/computer_system/eng/sc/super-...
http://www.ism.ac.jp/computer_system/eng/sc/super....
*Note that the Institute of Statistical Mathematics also keeps a separate HPC cluster. This used to be a Fujitsu PRIMERGY x86 cluster but has been replaced by a SGI ICE X cluster also using x86 chips.
Hamilton Sundstrand did their migration in two steps. The first was to migrate from Unix to Linux ( http://www.prnewswire.com/news-releases/hamilton-s... ) and then later migrated to a UV 1000 system ( http://pages.mscsoftware.com/rs/mscsoftware/images... )
Brutalizer - Monday, May 25, 2015 - link
@FUDer KevinG"...Say if you want to increase performance to a given level, x86 systems would require fewer additional sockets to do it and thus lower overhead that reduces scalability...."
And how do you know that x86 requires fewer sockets than SPARC? I have posted links about "Law of diminishing returns" and that sometimes you can only scale-up, scale-out does not do. SAP is a business system, i.e. scale-up system meaning scaling is difficult the more sockets you add - and if you claim that SAP gives linear scalability on x86, but not on SPARC - you need to show us links and backup up your claim. Otherwise it is just pure disinformation:
http://en.wikipedia.org/wiki/Fear,_uncertainty_and...
"FUD is generally a strategic attempt to influence perception by disseminating negative and dubious or false information...The term FUD originated to describe disinformation tactics in the computer hardware industry".
There you have it. If you spread pure disinformation (all your false statements) you are FUDing. So, I expect you to either confess that you FUD and stop spreading disinformation, or backup all your claims (which you can not because they are not true). Admit it, that you are a Troll and FUDer running SGI's errands, because nothing you ever say can be proven, because everything are lies.
.
"...Last I checked, 256 > 96 in terms of scalability. However socket count is only one aspect of performance but when the Xeon E5v2’s and E7v3’s are out running the SPARC chips in the M6 on a per core and per socket basis, it would be logical to conclude that an UV 2000 system would be faster and it wouldn’t even need all 256 sockets to do so...."
Why is it "logical"? You have numerous times proven your logic is wrong. On exactly what grounds do you base your weird claim? So, explain your reasoning or show us links to why your claim is true, why you believe that a 256 socket SGI would easily outperform 32-socket Unix servers:
I quote myself: "Note that SAP does not say you can run Business Suite on a 256-socket UV2000. They explicitly say SGI 32-socket servers is the limit. Why? Do you really believe a UV2000 can replace a scale-up server??? Even SAP confirms it can not be done!!"
And again, can you answer QUESTION_A)? Why do you claim that x86 going to 8-sockets and 300.000 saps can tackle larger workloads (i.e. scales better) than SPARC with 40-sockets and 850.000 saps? Why are you ducking the question?
.
"...My previous statements on this matter are perfectly in-line with the quote you’ve provided. So I’ll just repeat myself “That is how high availability is obtained: if the master server dies then a slave takes over transparently to outside requests. It is common place to order large database servers in sets of two or three for this very reason.” And then you scoffed at that statement but now you are effectively using your own points against yourself now..."
Jesus. You are in a twisted maze, and can't get out. Look. I asked you why companies pay $35 millions for a high end Unix IBM P595 with 32-sockets, when they can get a cheap 256-socket SGI server for much less money. To that you answered "because IBM P595 has better RAS". Now I explained that clusters have better RAS than a single point of failure server - so your RAS argument is wrong when you say that companies choose to spend more money on slower Unix servers than a cluster. To this you answer: "My previous statements on this matter are perfectly in-line with the quote you’ve provided. So I’ll just repeat myself “That is how high availability is obtained...now you are effectively using your own points against yourself now".
I did not ask about High Availability. Do you know what we are discussing at all? I asked why do companies pay $35 million for a 32-socket Unix IBM P595 server, when they can get a much cheaper 256-socket SGI server? And it is not about RAS as clusters have better RAS!!! So explain again why companies choose to pay many times more for a Unix server that has much lower socket count and lower performance. This is QUESTION_G)
.
I asked you "...So, now knowing this, answer me again on QUESTION_B) Why have not the market for high end Unix servers died immediately, if a cheap x86 scale-out cluster can replace any expensive Unix server?"
To this you answered:
“...Similarly there are institutions who have developed their own software on older Unix operating systems. Porting old code from HPUX, OpenVMS, etc. takes time..."
It seems that you claim that vendor lockin causes companies to continue buy expensive Unix servers, instead of choosing cheap Linux servers. Well, I got news for you, mr FUDer: if you have Unix code, then you can very easy recompile it for Linux on x86. So there is no vendor lockin, you are not forced to continue buying expensive Unix servers because you can not migrate off to Linux.
Sure if you have IBM Mainframes, or OpenVMS then you are locked in, and there are huge costs to migrate, essentially you have to rewrite large portions of the code as they are very different from POSIX Unix. But now we are talking about going from Unix to Linux. That step is very small and people routinely recompile code among Linux, FreeBSD, Solaris, etc. There is no need to pay $35 million for a single Unix servers because of vendor lockin.
So you are wrong again. Companies choose to pay $millions for Unix servers, not because of RAS, and not because of vendor lockin. So why do they do it? Can you answer this question? It is still QUESTION_B). Is it because large Unix servers are all scale-up whereas large x86 servers are all scale-out?
.
"....However there are some workloads that are best scale up due to the need to maintain concurrency like OLTP databases..."
Progress! You DO admit that there exists workloads that are scale-up!!! Do you also admit that scale-out servers can not handle scale-up workloads???? O_o
.
"...All you have shown is a horribly flawed analysis since the comparison was done between systems with different processor clock speeds. Attempting to determine the scaling of additional sockets between a system with 3.0 Ghz processors and another 3.7 Ghz processor isn’t going to work as the performance per socket is inherently different due to the clock speeds involved. This should be obvious....I reject your scaling comparison because to determine scaling by adding additional sockets, the only variable you want to change is just the number of sockets in a system...."
I also showed you that the same 3.7GHz SPARC cpu on the same server, achieves higher saps with 32-sockets, and achieves lower saps with 40-sockets. This was an effort to explain to you that as you add more sockets, SAP performance drops off sharply. The 40-socket benchmark uses the 12c latest version of the database vs 11g, which is marginally faster, but still performance dropped:
http://shallahamer-orapub.blogspot.se/2013/08/is-o...
.
"...Citation please where I stated that performance scales linearly. In fact, I can quote myself twice in this discussion where I’ve stated that performance *does not* scale linearly...."
So, why do believe that 32-socket x86 would easily be faster than Unix servers? Your analysis is... non rigorous. If you assume linear scaling, so yes. But as I showed you with SPARC 3.7GHz cpus, performance drops sub linear. Performance is not linear, so how do you know how well SAP scales? All accounts shows x86 scales awful (there would be SAP benchmarks all over the place if routinely x86 scaled to a milion saps). You write:
"...Yes, being able to do a third of the work with one fifth of the resources is indeed better scaling and that’s only with an 8 socket system. While true that scaling is not going to be linear as socket count increases, it would be easy to predict that a 32 socket x86 system would take the top spot...."
.
ME:“It seems you claim that UV300H is basically a stripped down UV2000. Well, if the UV2000 really can replace the UV300H, why dont SGI just sell a smaller configuration, say a 32-socket UV2000 with only one NUMAlink6?"
YOU:...They do. it is the 16 socket version of the UV 2000."
Oh, so the UV300 is the same as a smaller UV2000? Do you have links confirming this or did you just made it up?
Here SGI says they are targeting different workloads, it sounds they are different servers. Otherwise SGI would have said that UV2000 can handle all workloads so UV2000 is future proof:
https://www.sgi.com/products/servers/uv/
"SGI UV 2000...systems are designed for compute-intensive, fast algorithm workloads such as CAE, CFD, and scientific simulations...SGI UV 300...servers are designed for data-intensive, I/O heavy workloads"
I quote from your own link:
http://www.theplatform.net/2015/05/01/sgi-awaits-u...
"....This UV 300 does not have some of the issues that SGI’s larger-scale NUMA UV 2000 machines have, which make them difficult to program even if they do scale further....This is not the first time that SGI, in several of its incarnations, has tried to move from HPC into the enterprise space....Now you understand why SGI is so focused on SAP HANA for its UV 300 systems."
.
"...Or the answer could simply be that the UV 2000 is a scale up server...."
In the SGI link above, SGI explicitly says that UV2000 is for HPC number crunching workloads, i.e. scale-out workloads. Nowhere says SGI that is it good for business workloads, such as SAP or databases. SGI does not say UV2000 is a scale up server.
"...https://www.youtube.com/watch?v=lDAR7RoVHp0 <- shows how many processors and sockets that are on a single system running a single instance of Linux..."
It is totally irrelevant if it runs a single instance of Linux. As I have explained earlier, ScaleMP also runs a single instance of Linux. But ScaleMP is a software hypervisor that tricks the Linux kernel into believing the cluster is a single scale-up server. Some developer said "It looks like single image but latency was awful to far away nodes" I can show you the link. What IS relevant, is what kind of workloads do people run on the server. That is the only relevant thing. Not how SGI marketing describes the server. Microsoft marketing claims Windows is an enterprise OS, but no one would run a stock exchange on Windows. The only relevant thing is, if Windows is an enterprise OS, how many runs large demanding systems such as stock exchanges on Windows? No one. How many runs enterprise business systems on SGI UV2000? No one.
"...So far you have no provided anything that indicates that UV 2000 is a scale-out server as you claim..."
Que? I have talked all the time about how SGI says that UV2000 is only used for HPC number crunching work loads, an never business workloads! HPC number crunching and data analytics => scale out. Business Enterprise systems => scale-up. Scientific simulations are run on clusters. Business workloads can not run on clusters, you need a scale-up server for that.
OTOH, you have NEVER showed any links that proves UV2000 is suitable for scale-up workloads. Show us SAP benchmarks, I have asked numerous times in every post. You have not. No customer has ever run SAP on large SGI servers. No one. Never. Ever. For decades. If UV2000 is a scale up server, someone would have ran SAP. But no one. Why? Have you ever thought about this? Maybe it is not suitable for SAP?
.
QUESTION_D) Why have we never ever seen any SGI server on the sap benchmark list?
"...SGI has only been offering large scale up x86 servers for a few years starting with the UV 1000 in 2010. The main reason is that such a configuration would not be supported by SAP in production...."
But this is wrong again, SAP explicitly says 32-sockets is the limit. SAP says you can't run on UV2000. I quote myself: "Note that SAP does not say you can run Business Suite on a 256-socket UV2000. They explicitly say SGI 32-socket servers is the limit. Why? Do you really believe a UV2000 can replace a scale-up server??? Even SAP confirms it can not be done!!"
Also, SGI has certified SAP for the UV300H server which only scales to 16-sockets. So, SGI has certified servers. But not certified UV1000 nor UV2000 servers. SGI "UV" real name is SGI "Altix UV", and Altix servers have been on the market for long time. The main difference seems to be they used older NUMAlink3(?), and today it is NUMAlink6.
http://www.sgi.com/solutions/sap_hana/
.
ME:“Show us a x86 benchmark close to a million saps. If you can not, stop saying that x86 is able to tackle the largest sap workloads - because it can not. If it can, you can show us benchmarks.”
YOU:"This is again a shifting of the goal posts as initially you wanted to see an x86 system that simply could compete. So initially I provided a link to the Fujitsu system in the top 10. I would consider an 8 socket x86 system in the top 10 out of 789 systems that ran that benchmark as competitive. If wanted to, there are x86 systems that scale up further for additional performance."
No, this is wrong again. I wanted you to post x86 sap benchmarks with high scores that could compete at the very top. You posted small 8-socket servers and said they could compete with the very fastest servers. Well, to most people 300.000 saps can not compete with 850.000 saps. So you have not done what I asked you. So, I ask you again for the umpteen time; show us a x86 sap benchmark that can scale and compete with the fastest Unix servers. I have never "shifted goal posts" with this. My point is; x86 can not scale up to handle the largest workloads. And you claim this is wrong, that x86 can do that. In that case; show us sap benchmarks proving your claim. That has been the whole point all the time: asking you to prove your claim.
So again, show us SAP benchmarks that can compete with the largest Unix servers. And no, 300.000 saps can not compete with 850.000 saps. Who are you trying to fool? So, prove your claim. Show us a single benchmark.
.
Me:“But if I am wrong, then you can prove it, right? Show us ONE SINGLE LINK that supports your claim. If you are right, then there will be lot of links on the vast internet showing that customers replace large Unix servers with x86 clusters such as SGI UV2000 and saving lot of money and gaining performance in the process.”
YOU:"I’ll just repost this then: http://www.theplatform.net/2015/05/01/sgi-awaits-u...
The big quote from the article: “CEO Jorge Titinger said that through the end of that quarter SGI had deployed UV 300H machines at thirteen customers"
Que? Who are you trying to fool? I talked about UV2000, not UV300H!!! Show us ONE link where customers replaced high end Unix servers with a UV2000 scale-out server. UV300H stops at 32-sockets, so they are likely scale-up. And there have never been a question whether a scale-up server can run SAP. The question is whether UV2000 is suitable for scale-up workloads, and can replace Unix servers on e.g. SAP workloads. They can not. But you vehemently claim the opposite. So, show us ONE single link where customers run SAP on UV2000.
I quote myself: "Note that SAP does not say you can run Business Suite on a 256-socket UV2000. They explicitly say SGI 32-socket servers is the limit. Why? Do you really believe a UV2000 can replace a scale-up server??? Even SAP confirms it can not be done!!"
Why are you not giving satisfactory answers to my questions? I ask about UV2000, you show UV300H. I ask about one single link with UV2000 running large SAP, you never ever post such links. Why? If it is so easy to replace high end Unix servers with UV2000 - show us one single example. If you can not, who are you trying to fool? Is it even possible, or impossible? Has someone ever done it?? Nope. So... are you FUDing?
I quote from your own link:
http://www.theplatform.net/2015/05/01/sgi-awaits-u...
"....This UV 300 does not have some of the issues that SGI’s larger-scale NUMA UV 2000 machines have, which make them difficult to program even if they do scale further....This is not the first time that SGI, in several of its incarnations, has tried to move from HPC into the enterprise space....Now you understand why SGI is so focused on SAP HANA for its UV 300 systems."
It says, just like SAP says, that UV2000 is not suitable for SAP workloads. How can you keep on claiming that UV2000 is suitable for SAP workloads, when SGI and SAP says the opposite?
.
"...So using the Bixby interconnect to 32 socket is not a cluster but then scaling to 96 sockets with Bixby is a cluster?"
Of course a 32-socket Unix server is a NUMA server, they all are! The difference is that if you have very few memory hops between far away nodes as Bixby has, it can run scale-up workloads fine. But if you have too many hops between far away nodes as scale-out clusters have, performance will suck and you can not run scale-up workloads. Oracle can scale Bixby much higher I guess, but performance would be bad and no one would use it to run scale-up workloads.
Oracle is in war with IBM and both tries vigorously to snatch top benchmarks, and do whatever they can. If Oracle 96-socket Bixby could win all benchmarks, Oracle would have. But scaling drops off sharply, that is the reason Oracle stops at 32-sockets. In earlier road maps, Oracle talked about 64-socket SPARC servers, but dont sell any such today. I guess scaling would not be optimal as SPARC M7 servers with 32-sockets already has great scalability with 1024 cores and 8.192 threads and 64 TB RAM. And M7 servers are targeting databases and other business workloads. That is what Oracle do. So M7 servers are scale-up. Not scale-out.
.
"...People like using the best tool for the job. Enterprise workloads benefit heavily from a shared memory space and cache coherent architectures for concurrency. This is why scale-up servers are generally preferred for business workloads (though there are exceptions)...."
Wtf? So you agree that there is a difference between scale-up and scale-out workloads? Do you also agree that a scale-out server can not replace a scale-up server?
.
"...Indeed you have. “The largest x86 servers are all 8 sockets, there are no larger servers for sale and have never been.” was said here http://anandtech.com/comments/9193/the-xeon-e78800... and now you’re claiming you’ve known about 16 socket x86 servers from Bull and earlier 32 socket x86 SGI servers. These statements made by you are clearly contradictory...."
As I explained, no one puts larger servers than 8-sockets in production, because they scale too bad (where are all benchmarks???). I also talked about business enterprise workloads. We all know that SGI has manufactured larger servers than 8-sockets, for decades, targeting HPC number crunching. This discussion is about monolithic business software with code branching all over the place - that is the reason syncing and locking is hard on larger servers. If you have many cpus, syncing will be a big problem. This problem rules out 256-socket servers for business workloads.
So again; no one use larger than 8-socket x86 servers for business enterprise systems, because x86 scale too bad. Where are all the customers doing that? Where are all benchmarks outclassing Unix high end servers?
.
"...At the launch HP’s x86 based SuperDome X included a customer name, Cerner. ( http://www8.hp.com/us/en/hp-news/press-release.htm... )
A quick bit of searching turned put that they used HPUX and Itanium systems before.
( http://www.cerner.com/About_Cerner/Partnerships/HP... )..."
And where does it say that Cerner used this 16-socket x86 server to replace a high end Unix server? Is it your own conclusion, or do you have links?
.
"...The key point, which you quote, is to maintain concurrency. Locking is just a means to achieve that goal but there are others. So instead of resorting to personal attacks as you have done, I’ll post some links to some non-locking concurrency techniques:..."
Wow! Excellent that you for once post RELEVANT links backing up your claims. We are not used to that as you frequently post claims that are never backed up ("show us x86 sap scores competing with high end Unix servers").
You show some links, but my point is that when you finally save the data, you need to use some synchronizing mechanism, some kind of lock. The links you show all delay the writing of data, but in the end, there is some kind of synchronizing mechanism.
This is not used in heavy transaction environments so it is not interesting.
http://en.wikipedia.org/wiki/Optimistic_concurrenc...
"...OCC is generally used in environments with low data contention....However, if contention for data resources is frequent, the cost of repeatedly restarting transactions hurts performance significantly..."
This has a lock deep down:
http://en.wikipedia.org/wiki/Timestamp-based_concu...
"....Even though this technique is a non-locking one,...the act of recording each timestamp against the Object requires an extremely short duration lock..."
This must also synchronize writes, so there is a mechanism to hinder writes, ie. lock
http://en.wikipedia.org/wiki/Multiversion_concurre...
"...Which is to say a write cannot complete if there are outstanding transactions with an earlier timestamp....Every object would also have a read timestamp, and if a transaction Ti wanted to write to object P, and the timestamp of that transaction is earlier than the object's read timestamp (TS(Ti) < RTS(P)), the transaction Ti is aborted and restarted..."
If you had been studying comp sci, you know that there is no way to guarantee data integrity without some kind of mechanism to stop multiple writes. You MUST synchronize multiple writes. There are ways to delay writes, but you must ultimately write all your edits - it must occur. Then you MUST stop things to write simultaneously. There is no way to get around the final writing down to disk. And that final writing can get messy unless you synchronize. So all methods have some kind of mechanism to avoid simultaneus writes. I dont even have to read the links, this is common comp sci knowledge. It can not be done.
.
ME:“So now you can read from SAP web site in your own link, that SAP Hana cluster which is in memory database is only used for data analytics read usage. And for the business suite, you need a scale-up server. So you are wrong again.”
YOU:"How so? The UV 300H works fine by your admission for the HANA business suite as it is a scale up server. We are in agreement on this!"
Let me explain again. SAP Hana in memory version can run on scale-out systems as it only does reads on data analytics, whereas business suite can only run on scale-up systems as it need to write data. This is what SAP says.
.
ME:“Show us one single customer that has replaced a single Unix high end server with a SGI scale-out server, such as UV2000 or Altix or ScaleMP or whatever. Just one single link.”
YOU: "...The Institute of Statistical Mathematics in Japan replaced their Fujitsu M9000 ..."
Jesus. This whole discussion has been about whether scale-out systems can replace scale-up systems. You know that. Of course you can replace a SPARC M9000 (once held world record on floating point calculation) used for HPC workloads, with a scale-out server. That has never been the question whether a scale-out server can replace scale-up doing HPC computations.
The question is, show us a single link where some customer replaced Unix high end server running scale-up business enterprise software (SAP, databases,etc) with a SGI UV2000 server. You can not.
I dont know how many times I have asked this? And you have never posted any such links. Of course you have googled like mad, but never found any such links. Have you ever thought about why there are no such links out there on the whole internet? Maybe SGI UV2000 is not suitable for scale-up workloads? You even post links saying exactly this:
http://www.theplatform.net/2015/05/01/sgi-awaits-u...
"....This UV 300 does not have some of the issues that SGI’s larger-scale NUMA UV 2000 machines have, which make them difficult to program even if they do scale further....This is not the first time that SGI, in several of its incarnations, has tried to move from HPC into the enterprise space....Now you understand why SGI is so focused on SAP HANA for its UV 300 systems."
Why does not SGI move into the lucrative enterprise space with UV2000???? Why must SGI manufacture 16-socket UV300H instead of 256-socket UV2000? Why?
Brutalizer - Monday, May 25, 2015 - link
(PS. I just emailed SGI sales rep for more information/links on how to replace high end 32-socket Unix servers with the 256-socket SGI UV2000 server on enterprise business workloads such as SAP and oracle databases. I hope they will get in touch soon and I will repost all information/links here. Maybe you could do the same if you dont trust my replies: ask for links on how to replace Unix servers with UV2000 - I suspect SGI will say it can not be done. :)Kevin G - Monday, May 25, 2015 - link
@FBrutalizer“And how do you know that x86 requires fewer sockets than SPARC?”
Even with diminishing returns, there are still returns. In other benchmarks regarding 16 socket x86 systems, performance isn’t double that of an 8 socket system but it still a very respectable gain. Going to 32 sockets with the recent Xeon E7v3 chips should be able to capture the top spot.
“If you spread pure disinformation (all your false statements) you are FUDing. So, I expect you to either confess that you FUD and stop spreading disinformation, or backup all your claims.”
How about a change of pace and you start backing up your claims?
“Look. I asked you why companies pay $35 millions for a high end Unix IBM P595 with 32-sockets, when they can get a cheap 256-socket SGI server for much less money. To that you answered "because IBM P595 has better RAS”
I’ve stated that you chose the best tool for the job. Some workloads you can scale out where a cluster of systems would be most appropriate. Some workloads it is best scale up. If it can only scale up, you want to get a reliable system, especially for critical systems that cannot have any down time.
You should also stop bringing up the P595 for this comparison: it hasn’t been sold by IBM for years now.
“It seems that you claim that vendor lockin causes companies to continue buy expensive Unix servers, instead of choosing cheap Linux servers. Well, I got news for you, mr FUDer: if you have Unix code, then you can very easy recompile it for Linux on x86. So there is no vendor lockin, you are not forced to continue buying expensive Unix servers because you can not migrate off to Linux.”
Unix systems do offer proprietary libraries and features that Linux does not offer. If a developer’s code sticks to POSIX and ANSI C, then it is very portable but the more you dig into the unique features of a particular flavor of Unix, the harder it is to switch to another. Certainly there is overlap between Unix and Linux but there is plenty unique to each OS.
“I also showed you that the same 3.7GHz SPARC cpu on the same server, achieves higher saps with 32-sockets, and achieves lower saps with 40-sockets. This was an effort to explain to you that as you add more sockets, SAP performance drops off sharply. The 40-socket benchmark uses the 12c latest version of the database vs 11g, which is marginally faster, but still performance dropped”
No, you didn’t even notice the clock speed differences and thought that they were the same as per your flawed analysis on the matter. It is a pretty big factor for performance and you seemingly have overlooked it. Thus your entire analysis on how those SPARC systems scaled with additional sockets is inherently flawed.
>>“…Citation please where I stated that performance scales linearly.”
“So, why do believe that 32-socket x86 would easily be faster than Unix servers?”
That is not a citation. Another failed claim on your part.
“Oh, so the UV300 is the same as a smaller UV2000? Do you have links confirming this or did you just made it up?”
No, in fact I pointed out that the UV 300 uses NUMALink7 interconnect where as the UV 2000 uses NUMALink6 ( http://anandtech.com/comments/9193/the-xeon-e78800... ). I also provided some links regarding this which you apparently did not read but I’ll repost anyway:
http://www.theplatform.net/2015/05/01/sgi-awaits-u...
http://www.enterprisetech.com/2014/03/12/sgi-revea...
"SGI does not say UV2000 is a scale up server.”
You apparently did not watch this where they explain it is a giant SMP machine that goes up to 256 sockets: https://www.youtube.com/watch?v=KI1hU5g0KRo
“It is totally irrelevant if it runs a single instance of Linux. As I have explained earlier, ScaleMP also runs a single instance of Linux.”
Except that ScaleMP is not used by the UV2000 so discussing it here is irrelevant as I’ve pointed out before.
“Que? I have talked all the time about how SGI says that UV2000 is only used for HPC number crunching work loads, an never business workloads!”
That’s nice. HPC workloads can still be performed on large scale-up system just fine. So what specifically in the design of the UV 2000 makes it scale out as you claim? Just because you say so doesn’t make it true. Give me something about its actual design that counters SGI own documentation about it being one large SMP device. Actually back up this claim.
Also you haven’t posted a link quoting SGI that the UV 2000 is only good for HPC. In fact, the link you continually post about this is a decade old and in the context of older cluster offers SGI promoted, long before SGI introduced the UV 2000.
“But this is wrong again, SAP explicitly says 32-sockets is the limit.”
SAP doesn’t actually say that 32 sockets is a hard limit. Rather it is the most number of sockets for a system that will be validated (and it is SAP here that is expecting the 32 socket UV 300 to be validated). Please in the link below quote where SAP say that HANA strictly cannot go past 32 sockets:
https://blogs.saphana.com/2014/12/10/sap-hana-scal...
“The main difference seems to be they used older NUMAlink3(?), and today it is NUMAlink6.”
Again, the UV 2000 is using the NUMALink6 as many of my links have pointed out. The UV 300 is using NUMALink7 which use the same topology but increase bandwidth slightly while cutting latency.
>>”This is again a shifting of the goal posts as initially you wanted to see an x86 system that simply could compete. So initially I provided a link to the Fujitsu system in the top 10. I would consider an 8 socket x86 system in the top 10 out of 789 systems that ran that benchmark as competitive. If wanted to, there are x86 systems that scale up further for additional performance."
“No, this is wrong again. I wanted you to post x86 sap benchmarks with high scores that could compete at the very top.”
And I did, a score in the top 10. I did not misquote you and I provided exactly what you initially asked for. Now you continue to attempt to shift the goal posts.
“Why are you not giving satisfactory answers to my questions?”
Because when I answer them you shift the goal posts and resort to some personal attacks.
“It says, just like SAP says, that UV2000 is not suitable for SAP workloads. How can you keep on claiming that UV2000 is suitable for SAP workloads, when SGI and SAP says the opposite?”
That quote indicates that it does scale further. The difficulty being mentioned is a point that been brought up before: the additional latencies due to more interconnections as the system scales up.
>>"...So using the Bixby interconnect to 32 socket is not a cluster but then scaling to 96 sockets with Bixby is a cluster?"
“Of course a 32-socket Unix server is a NUMA server, they all are! The difference is that if you have very few memory hops between far away nodes as Bixby has, it can run scale-up workloads fine. But if you have too many hops between far away nodes as scale-out clusters have, performance will suck and you can not run scale-up workloads. Oracle can scale Bixby much higher I guess, but performance would be bad and no one would use it to run scale-up workloads.”
Except you are not answering the question I asked. Simply put, what actually would make the 96 socket version a cluster where as the 32 socket version is not? The answer is that they are both scale up and not clusters. The idea that performance would suck wouldn’t inherently change it from a scale-up system to a cluster as you’re alluding to. It would still be a scale up system, just like how the UV 2000 would be a scale up system.
>>”…Indeed you have. “The largest x86 servers are all 8 sockets, there are no larger servers for sale and have never been.” was said here http://anandtech.com/comments/9193/the-xeon-e78800... and now you’re claiming you’ve known about 16 socket x86 servers from Bull and earlier 32 socket x86 SGI servers. These statements made by you are clearly contradictory...."
“As I explained, no one puts larger servers than 8-sockets in production, because they scale too bad (where are all benchmarks???). I also talked about business enterprise workloads.”
And this does not explain the contradiction in your statements. Rather this is more goal post shifting.
"And where does it say that Cerner used this 16-socket x86 server to replace a high end Unix server? Is it your own conclusion, or do you have links?”
Yes as I’ve stated, it wouldn’t make sense to use anything less than the 16 socket version. They could have purchased an 8 socket server from various other vendors like IBM/Lenovo or HP’s own DL980. Regardless of socket count, it is replacing a Unix system as HPUX is being phased out. If you doubt it, I’d just email the gentlemen that HP quoted and ask.
“You show some links, but my point is that when you finally save the data, you need to use some synchronizing mechanism, some kind of lock. The links you show all delay the writing of data, but in the end, there is some kind of synchronizing mechanism.”
Congratulations on actually reading my links! This must be the first time. However, it matters not as the actual point has been lost entirely again. There indeed has to be a mechanism in place for concurrency but I’ll repeat that my point is that it does not have to be a lock as there are alternatives. Even after reading my links on the subject, you simply just don’t get it that there are alternatives to locking.
“If you had been studying comp sci, you know that there is no way to guarantee data integrity without some kind of mechanism to stop multiple writes. You MUST synchronize multiple writes. There are ways to delay writes, but you must ultimately write all your edits - it must occur. Then you MUST stop things to write simultaneously. There is no way to get around the final writing down to disk. And that final writing can get messy unless you synchronize. So all methods have some kind of mechanism to avoid simultaneus writes. I dont even have to read the links, this is common comp sci knowledge. It can not be done.”
Apparently it does work and it is used in production enterprise databases as I’ve given examples of it with appropriate links. If you claim other wise, how about a formal proof as to why it cannot as you claim? How about backing one of your claims up for once?
"Jesus. This whole discussion has been about whether scale-out systems can replace scale-up systems. You know that. Of course you can replace a SPARC M9000 (once held world record on floating point calculation) used for HPC workloads, with a scale-out server. That has never been the question whether a scale-out server can replace scale-up doing HPC computations.”
Actually I’ve been trying to get you to realize that the UV 2000 is a scale up SMP system. Just like you’ve been missing my main point, you have overlook where the institute was using it was a scale up system due the need for a large shared memory space for their workloads. It was replaced by a UV 2000 due to its large memory capacity as a scale up server. Again, this answer fit your requirements of “Show us one single customer that has replaced a single Unix high end server with a SGI scale-out server, such as UV2000 or Altix or ScaleMP or whatever.” and again you are shifting the goal posts.
And as a bonus, I posted a second set of links which you’ve ignored so I’ll repost them. Hamilton Sundstrand did their migration in two steps. The first was to migrate from Unix to Linux ( http://www.prnewswire.com/news-releases/hamilton-s... and then later migrated to a UV 1000 system ( http://pages.mscsoftware.com/rs/mscsoftware/images... )