The Apple iPhone 11, 11 Pro & 11 Pro Max Review: Performance, Battery, & Camera Elevated
by Andrei Frumusanu on October 16, 2019 8:30 AM ESTSystem & ML Performance
Having investigated the new A13’s CPU performance, it’s time to look at how it performs in some system-level tests. Unfortunately there’s still a frustrating lack of proper system tests for iOS, particularly when it comes to tests like PCMark that would more accurately represent application use-cases. In lieu of that, we have to fall back to browser-based benchmarks. Browser performance is still an important aspect of device performance, as it remains one of the main workloads that put large amounts of stress on the CPU while exhibiting performance characteristics such as performance latency (essentially, responsiveness).
As always, the following benchmarks aren’t just a representation of the hardware capabilities, but also the software optimizations of a phone. iOS13 has again increased browser-based benchmarks performance by roughly 10% in our testing. We’ve gone ahead and updated the performance figures of previous generation iPhones with new scores on iOS13 to have proper Apple-to-Apple comparisons for the new iPhone 11’s.
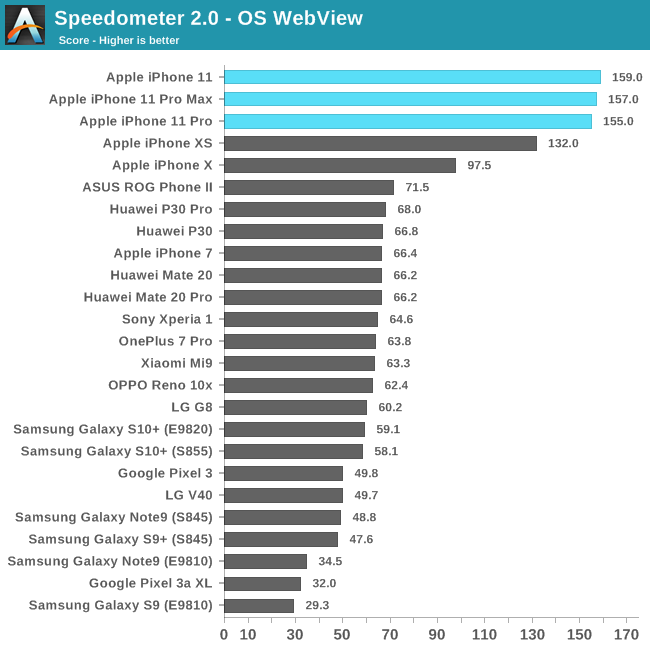
In Speedometer 2.0 we see the new A13 based phones exhibit a 19-20% performance increase compared to the previous generation iPhone XS and the A12. The increase is in-line with Apple’s performance claims. The increase this year is a bit smaller than what we saw last year with the A12, as it seems the main boost to the scores last year was the upgrade to a 128KB L1I cache.
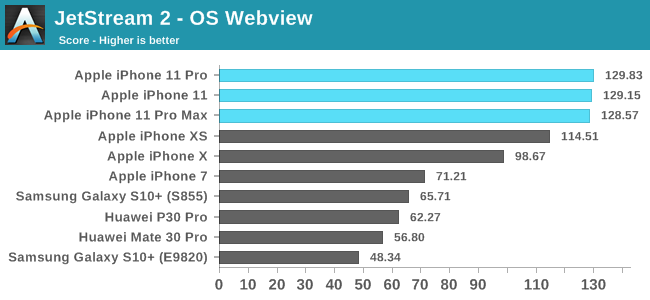
JetStream 2 is a newer browser benchmark that was released earlier this year. The test is longer and possibly more complex than Speedometer 2.0 – although we still have to do proper profiling of the workload. The A13’s increases here are about 13%. Apple’s chipsets, CPUs, and custom Javascript engine continue to dominate the mobile benchmarks, posting double the performance we see from the next-best competition.
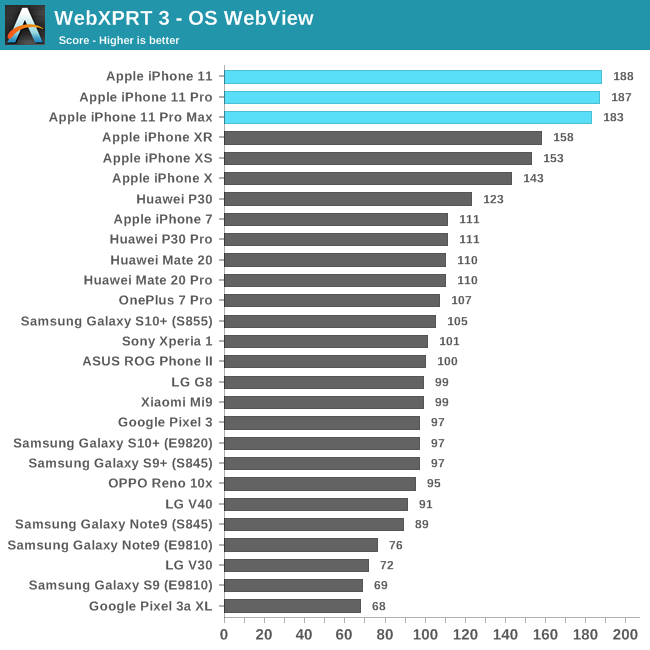
Finally WebXPRT represents more of a “scaling” workload that isn’t as steady-state as the previous benchmarks. Still, even here the new iPhones showcase a 18-19% performance increase.
Last year Apple made big changes to the kernel scheduler in iOS12, and vastly shortened the ramp-up time of the CPU DVFS algorithm, decreasing the time the system takes to transition from lower idle frequencies and small cores idle to full performance of the large cores. This resulted in significantly improved device responsiveness across a wide range of past iPhone generations.
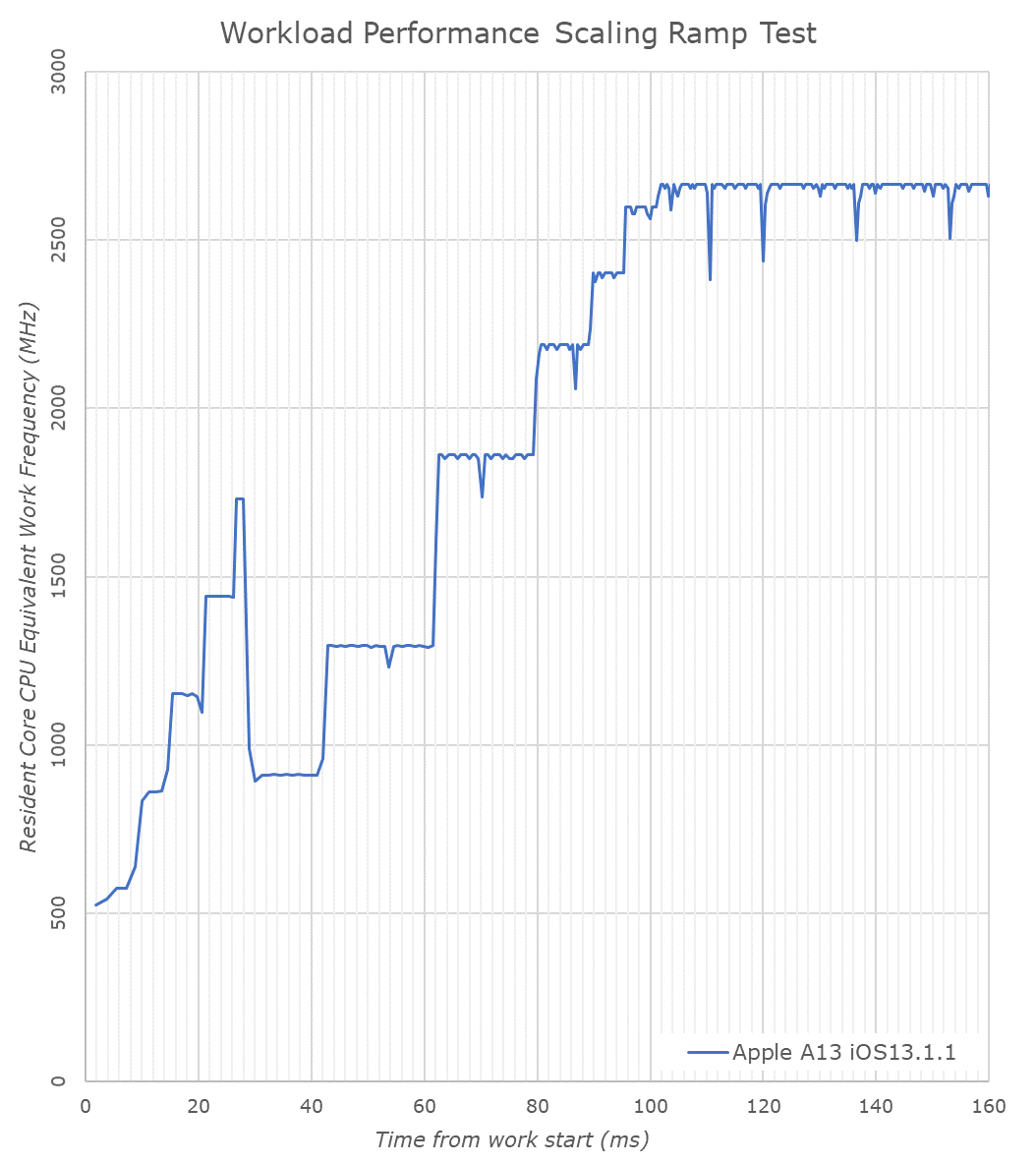
Compared to the A12, the A13 doesn’t change all that much in terms of the time it takes to reach the maximum clock-speed of the large Lightning cores, with the CPU core reaching its peak in a little over 100ms.
What does change a lot is the time the workload resides on the smaller Thunder efficiency cores. On the A13 the small cores are ramping up significantly faster than on the A12. There’s also a major change in the scheduler behavior and when the workload migrates from the small cores to the large cores. On the A13 this now happens after around 30ms, while on the A12 this would take up to 54ms. Due to the small cores no longer being able to request higher memory controller performance states on their own, it likely makes sense to migrate to the large cores sooner now in the case of a more demanding workload.
The A13’s Lightning cores are start off at a base frequency of around 910MHz, which is a bit lower than the A12 and its base frequency of 1180MHz. What this means is that Apple has extended the dynamic range of the large cores in the A13 both towards higher performance as well as towards the lower, more efficient frequencies.
Machine Learning Inference Performance
Apple has also claimed to have increased the performance of their neural processor IP block in the A13. To use this unit, you have to make use of the CoreML framework. Unfortunately we don’t have a custom tool for testing this as of yet, so we have to fall back to one of the rare external applications out there which does provide a benchmark for this, and that’s Master Lu’s AIMark.
Like the web-browser workloads, iOS13 has brought performance improvements for past devices, so we’ve rerun the iPhone X and XS scores for proper comparisons to the new iPhone 11.
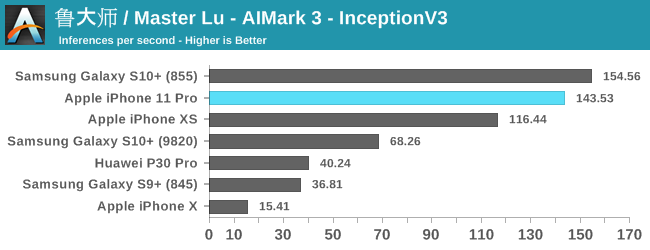
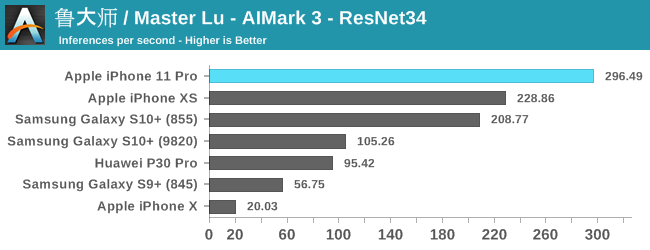
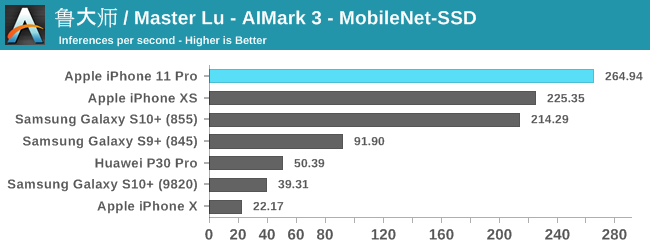
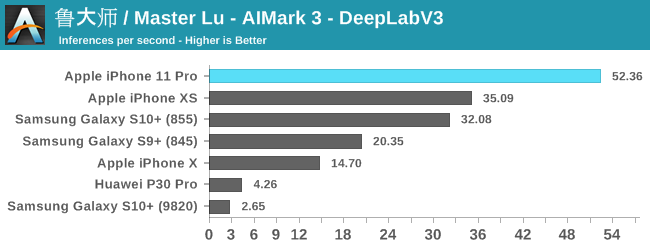
The improvements for the iPhone 11 and the new A13 vary depending on the model and workload. For the classical models such as InceptionV3 and ResNet34, we’re seeing 23-29% improvements in the inference rate. MobileNet-SSD sees are more limited 17% increase, while DeepLabV3 sees a major increase of 48%.
Generally, the issue of running machine learning benchmarks is that it’s running through an abstraction layer, in this case which is CoreML. We don’t have guarantees on how much of the model is actually being run on the NPU versus the CPU and GPU, as things can differ a lot depending on the ML drivers of the device.
Nevertheless, the A13 and iPhone 11 here are very competitive and provide good iterative performance boosts for this generation.
Performance Conclusion
Overall, performance on the iPhone 11s is excellent, as we've come to expect time and time again from Apple. With that said, however, I can’t really say that I notice too much of a difference to the iPhone XS in daily usage. So while the A13 delivers class leading performance, it's probably not going to be very compelling for users coming from last year's A12 devices; the bigger impact will be felt coming from older devices. Otherwise, with this much horsepower I feel like the user experience would benefit significantly more from an option to accelerate application and system animations, or rather even just turn them off completely, in order to really feel the proper snappiness of the hardware.








{kind=link}
242 Comments
View All Comments
zhuzhengchao - Wednesday, November 4, 2020 - link
When looking into the floorplan, there is likely a coprocessor in the top design of GPU (except for the bus interface with LLC), which is shared with the 4 cores.Am I right? and who have idea about it.
Anyway, it is so big one.
MaxShen - Wednesday, November 18, 2020 - link
Hi Anandtech,How to bind software thread to the thunder (small core,such as Core 1) of Apple-A13?
Because I want to test the thunder (small core,such as Core 1) performance.
So far, I'm out of jail and can run software threads from the apple A13 command line.
Thanks!
Best Wishes
MaxShen