Intel 11th Generation Core Tiger Lake-H Performance Review: Fast and Power Hungry
by Brett Howse & Andrei Frumusanu on May 17, 2021 9:00 AM EST- Posted in
- CPUs
- Intel
- 10nm
- Willow Cove
- SuperFin
- 11th Gen
- Tiger Lake-H
CPU Tests: Microbenchmarks
Core-to-Core Latency
As the core count of modern CPUs is growing, we are reaching a time when the time to access each core from a different core is no longer a constant. Even before the advent of heterogeneous SoC designs, processors built on large rings or meshes can have different latencies to access the nearest core compared to the furthest core. This rings true especially in multi-socket server environments.
But modern CPUs, even desktop and consumer CPUs, can have variable access latency to get to another core. For example, in the first generation Threadripper CPUs, we had four chips on the package, each with 8 threads, and each with a different core-to-core latency depending on if it was on-die or off-die. This gets more complex with products like Lakefield, which has two different communication buses depending on which core is talking to which.
If you are a regular reader of AnandTech’s CPU reviews, you will recognize our Core-to-Core latency test. It’s a great way to show exactly how groups of cores are laid out on the silicon. This is a custom in-house test built by Andrei, and we know there are competing tests out there, but we feel ours is the most accurate to how quick an access between two cores can happen.
In terms of the core-to-core tests on the Tiger Lake-H 11980HK, it’s best to actually compare results 1:1 alongside the 4-core Tiger Lake design such as the i7-1185G7:
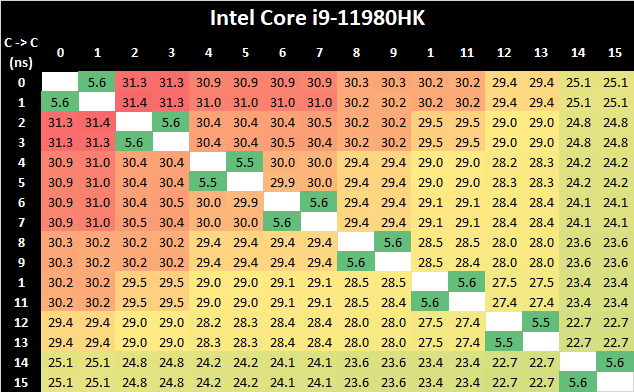

What’s very interesting in these results is that although the new 8-core design features double the cores, representing a larger ring-bus with more ring stops and cache slices, is that the core-to-core latencies are actually lower both in terms of best-case and worst-case results compared to the 4-core Tiger Lake chip.
This is generally a bit perplexing and confusing, generally the one thing to account for such a difference would be either faster CPU frequencies, or a faster clock of lower cycle latency of the L3 and the ring bus. Given that TGL-H comes 8 months after TGL-U, it is plausible that the newer chip has a more matured implementation and Intel would have been able to optimise access latencies.
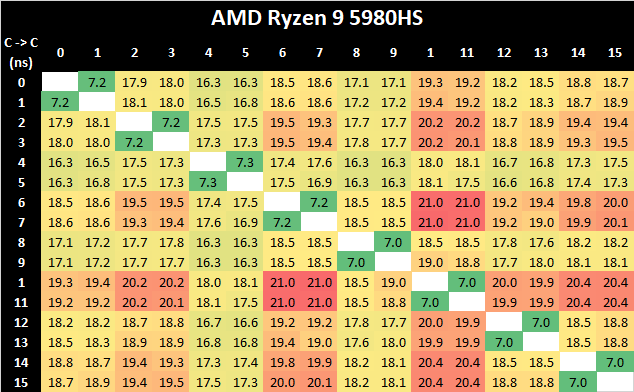
Due to AMD’s recent shift to a 8-core core complex, Intel no longer has an advantage in core-to-core latencies this generation, and AMD’s more hierarchical cache structure and interconnect fabric is able to showcase better performance.
Cache & DRAM Latency
This is another in-house test built by Andrei, which showcases the access latency at all the points in the cache hierarchy for a single core. We start at 2 KiB, and probe the latency all the way through to 256 MB, which for most CPUs sits inside the DRAM (before you start saying 64-core TR has 256 MB of L3, it’s only 16 MB per core, so at 20 MB you are in DRAM).
Part of this test helps us understand the range of latencies for accessing a given level of cache, but also the transition between the cache levels gives insight into how different parts of the cache microarchitecture work, such as TLBs. As CPU microarchitects look at interesting and novel ways to design caches upon caches inside caches, this basic test proves to be very valuable.
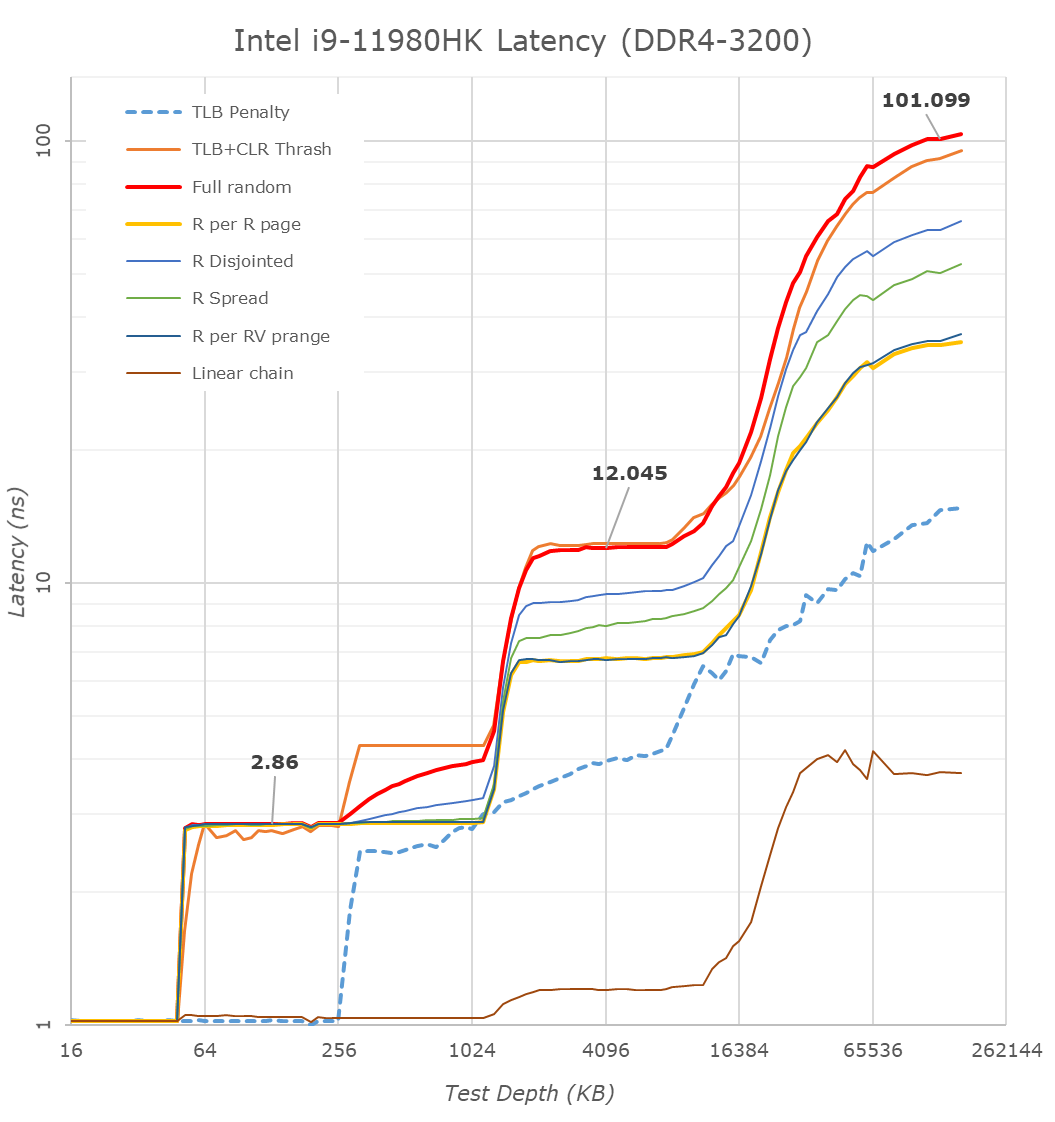
What’s of particular note for TGL-H is the fact that the new higher-end chip does not have support for LPDDR4, instead exclusively relying on DDR4-3200 as on this reference laptop configuration. This does favour the chip in terms of memory latency, which now falls in at a measured 101ns versus 108ns on the reference TGL-U platform we tested last year, but does come at a cost of memory bandwidth, which is now only reaching a theoretical peak of 51.2GB/s instead of 68.2GB/s – even with double the core count.
What’s in favour of the TGL-H system is the increased L3 cache from 12MB to 24MB – this is still 3MB per core slice as on TGL-U, so it does come with the newer L3 design which was introduced in TGL-U. Nevertheless, this fact, we do see some differences in the L3 behaviour; the TGL-H system has slightly higher access latencies at the same test depth than the TGL-U system, even accounting for the fact that the TGL-H CPUs are clocked slightly higher and have better L1 and L2 latencies. This is an interesting contradiction in context of the improved core-to-core latency results we just saw before, which means that for the latter Intel did make some changes to the fabric. Furthermore, we see flatter access latencies across the L3 depth, which isn’t quite how the TGL-U system behaved, meaning Intel definitely has made some changes as to how the L3 is accessed.








229 Comments
View All Comments
Yojimbo - Monday, May 17, 2021 - link
Should read "And frankly, I can't see a good reason for many consumers to be looking at the situation differently such that they would be concerned about the power draw of the laptop when plugged in."I'm not saying that plugged in power usage is useless to consider, just that it seems to me much less important, as far as power-usage is concerned (even for a desktop replacement) than battery-powered power usage and performance. Maybe others feel differently but I don't understand why. It's not like any laptop is a real power hog unlike some desktop systems can be. We're talking about, what, plus-or-minus 20 watts here? 30 watts? 30 watts plugged in means nothing to me. Does it mean a lot to most others, and if so why?
Bik - Monday, May 17, 2021 - link
It's the capability of the laptop to disperse heat. More watt = more heat. The heat is the issue (loud fan, cpu throttle).Yojimbo - Monday, May 17, 2021 - link
But that varies widely from laptop to laptop. And it's not just a function of the heat output, it's a function of the cooling system, which is related to both cost and weight. So you don't really get helpful information for noise or throttling just by looking at plugged-in power usage.vegemeister - Tuesday, May 18, 2021 - link
More power = more noise for the same cost and weight, or more cost and weight for the same noise.repoman27 - Monday, May 17, 2021 - link
Is there a reason why TGL-U is referred to (somewhat confusingly) in the article as just TGL? I know Intel (also somewhat confusingly) uses the TGL-U 4+2 LP die for three separate platforms (UP3, UP4, and H35), but they're all still considered TGL-U, aren't they? Whereas Tiger Lake is the codename for the whole range of processor families including UP3, UP4, H35, and H.Maybe TGL 4+2 and TGL 8+1 would be more succinct?
Andrei Frumusanu - Monday, May 17, 2021 - link
Fair, I'll change the terminology.bernstein - Monday, May 17, 2021 - link
@Andrei Frumusanu :how is it that the amd 5800x (and others) spec2017fp_r results differ by as much as 7 points while the spec2017int_r values are basically on point? (there seem to be minor differences for the 49/4800U in spec2017int_r values too. plus large diff for the i9-10900K).
comparing to : https://www.anandtech.com/show/16252/mac-mini-appl...
Andrei Frumusanu - Monday, May 17, 2021 - link
In that article we were using only the C/C++ sub-benchmarks due to not having a functioning Fortran compiler on the M1 at the time. So it's apples-and-oranges in terms of the scores between the articles. The integer suite only has 1 Fortran workload, the FP suite has much more.Since, I've rerun the M1 ST scores on a vanilla LLVM and Gfortran toolchain to get all workloads, and anyhow all articles except for that initial M1 piece have the full subset of workloads. The M1 MT scores are missing from this piece as I never ran that (brainfart) and no longer have an M1 system at hand.
bernstein - Monday, May 17, 2021 - link
thanks for clearing that up. great articles btw!also thx for anticipating (and answering) my next question!
Ppietra - Monday, May 17, 2021 - link
As far as I know the results in the Mac mini review aren’t the full SPEC 2017, because some tests require a Fortran compiler that didn’t exist for the M1.