Intel 4 Process Node In Detail: 2x Density Scaling, 20% Improved Performance
by Ryan Smith on June 13, 2022 7:00 AM EST
Taking place this week is the IEEE’s annual VLSI Symposium, one of the industry’s major events for disclosing and discussing new chip manufacturing techniques. One of the most anticipated presentations scheduled this year is from Intel, who is at the show to outline the physical and performance characteristics of their upcoming Intel 4 process, which will be used for products set to be released in 2023. The development of the Intel 4 process represents a critical milestone for Intel, as it’s the first Intel process to incorporate EUV, and it’s the first process to move past their troubled 10nm node – making it Intel’s first chance to get back on track to re-attaining fab supremacy.
Intel’s scheduled to deliver their Intel 4 presentation on Tuesday, in a talk/paper entitled “Intel 4 CMOS Technology Featuring Advanced FinFET Transistors optimized for High Density and High-Performance Computing”. But this morning, ahead of the show, they re publishing the paper and all of its relevant figures, giving us our first look at what kind of geometries Intel is attaining, as well as some more information about the materials being used.
Previously known as Intel’s 7nm process, Intel 4 is Intel’s first time using EUV lithography for their chips. A long time coming, the use of EUV promises both to allow Intel to draw the kind of ever-smaller features needed for more advanced manufacturing nodes, while at the same time letting Intel cut down on the number of manufacturing steps required via today’s multi-patterning DUV techniques. Unusually, Intel finds itself as the final of the big three fabs to tap into EUV – the company passed on EUV for the 10nm generation as they didn’t feel it was ready, and then delays with 10nm and 7nm pushed back Intel’s EUV adoption point significantly. As a result, Intel will get to spring forward on the basis of EUV-driven gains, though they will still have to make up for lost time and TSMC’s experience advantage.
The development of Intel 4 is also a critical juncture for the company, as it finally allows them to move past their troubled 10nm process. While Intel has managed to make something suitable of their 10nm process nodes – especially with their most recent 10nm Enhanced SuperFin variant, which we better know as Intel 7 – it’s not been without entirely too much blood, sweat, and years. Intel believes they tried to do too much all at once with 10nm – both in regards to scaling and in too many new manufacturing techniques – which in turn set them back years as they untangled that mess to find and iterate on what went wrong. Unsurprisingly then, Intel is being a bit less aggressive with their first EUV node, and the company overall has taken a much more modular development approach going forward, allowing for new technologies to be implemented (and, if necessary, debugged) in steps.

Intel 4, in turn, will be first used for Intel’s forthcoming Meteor Lake client SoC, which is expected to be the basis of Intel’s 14th generation Core processor family. Though not shipping until 2023, Intel already has Meteor Lake up and running in their labs, as per the company’s typical bring-up process. Along with brining a significant bump in process technologies, Meteor Lake will also be Intel’s first tiled/chiplet-based client CPU, using a mix of tiles for I/O, CPU cores, and GPU cores.

Intel 4 Physical Parameters: 2x Density Over Intel 7, Cobalt Use Continues
Diving into the Intel 4 process, Intel has set out to tackle a few different things here. First and foremost is, of course, density. Intel is striving to keep Moore’s Law alive, and while the coinciding death of Dennard scaling means that it’s no longer a simple matter of lighting up twice as many transistors on every generation, a higher transistor density affords smaller chips at with the same hardware, or throwing in more cores (or other processing hardware) with newer desgins.
| Comparing Intel 4 to Intel 7 | |||
| Intel 4 | Intel 7 | Change | |
| Fin Pitch | 30 nm | 34 nm | 0.88 x |
| Contact Gate Poly Pitch | 50 nm | 54/60 nm | 0.83 x |
| Minimum Metal Pitch (M0) | 30 nm | 40 nm | 0.75 x |
| HP Library Height | 240h | 408h | 0.59 x |
| Area (Library Height x CPP) | 12K nm2 | 24.4K nm2 | 0.49 x |
Of the figures Intel is releasing in this week’s paper, the fin pitch on Intel 4 is down to 30nm, 0.88x the size of Intel 7’s 34nm pitch. Similarly, the pitch between contact gates is now 50nm, down from 60nm before. But most significantly, the minimum metal pitch for the lowest layer (M0) is also 30nm, 0.75x the size of the M0 pitch on Intel 7.
Intel’s library height has also been cut down as well. The cell height for the high-performance library on Intel 4 is 240nm, which is only 0.59 x the height of an HP cell on Intel 7.
As a result, Intel is claiming a 2x increase in density for Intel 4 versus Intel 7 – or more specifically, a halving of size for transistors – a traditional, full node’s improvement in transistor density.
Since chips are 2D constructs, the metric Intel uses for this is multiplying the HP cell height by the contacted poly pitch, which is essentially the width of a cell. In that case they get 24,408 nm2 for Intel 7, and a flat 12,000 nm2 for Intel 4, 0.49x the area of the Intel 7-based cell.
Of course, not every type of structure scales by the same factor with a new process node, and Intel 4 is no different. According to the company SRAM cells on Intel 4 are only around 0.77x the size of the same cells on Intel 7. So while standardized logic cells have doubled in density, SRAM density (for equivalent SRAM types) has only improved by 30% or so.
And, unfortunately, while Intel is talking about density with respect to standard cells, they aren’t officially disclosing actual transistor density figures. For now, what Intel is telling us is that the overall transistor density translates well with the 2x figure they’re currently providing. Which, based on what we know about Intel 7 and its 80 million transistors per mm2 density for HP libraries, would place Intel 4's HP libraries at around 160MTr/mm2.
Since these figures are for Intel's lower density high-performance libraries, the obvious follow-up question to that would be what the figures are for high density libraries – which traditionally squeeze things even more in exchange for reduced clockspeeds. However as it turns out, Intel won’t be developing high density libraries for Intel 4. Instead, Intel 4 will be a pure high-performance node, and high-density designs will come with the successive node, Intel 3.
This unusual development comes as a result of Intel’s modularization efforts for process node development. Intel has essentially adopted a tick tock-like strategy for node development over the next half decade or so, with Intel developing an initial node based on a new technology (e.g. EUV or High-NA machines), and then following that up with a more refined/optimized successor. In the case of Intel 4, while it’s doing important pioneering work for EUV within Intel’s fabs, the company’s bigger plans are for Intel 3 to be their long-term, long-lived EUV node.
All of which means that Intel has no need for high-density libraries with Intel 4, since it is slated to be replaced with the more fully-featured Intel 3 within a year or so. And since Intel 3 is design compatible with Intel 4, it’s clear to see how Intel is pushing its own design teams to use the latter process whenever timetables allow. Intel Foundry Services customers will also be a in a similar boat – they can use Intel 4, but IFS is more focused on supplying access to and design help with Intel 3.
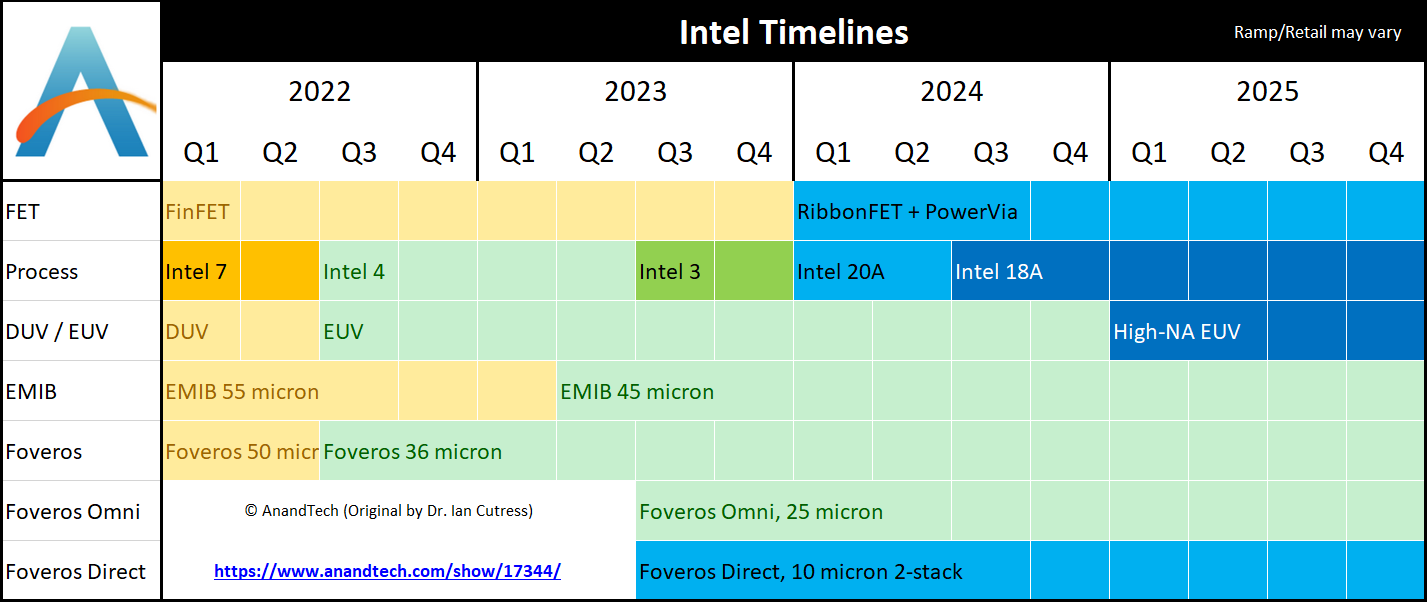
Getting back to Intel 4 itself, the new node comes with a significant change to the metal layers as compared to Intel’s 10nm processes. Intel famously replaced copper with cobalt at the lowest layers of its 10nm process, something that the company deemed necessary for transistor longevity (electromigration resistance) reasons. Unfortunately, cobalt isn’t as good from a performance (clockspeed) perspective, and it’s long been suspected that the switch to cobalt was one of the major stumbling blocks in 10nm development for Intel.
For Intel 4, in turn, Intel is taking half a step back. The company is still using cobalt in their processes, but now rather than pure cobalt they are using what they are calling Enhanced Copper (eCu), which is copper cladded with cobalt. The idea behind eCu is to have the best of both words, maintaining the performance of a doped copper metallization layer, while still getting the electromigration resistance benefits of cobalt.
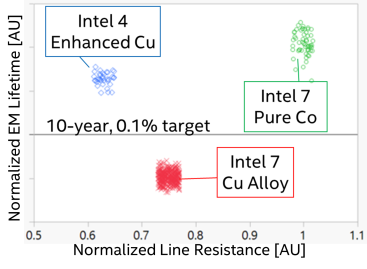
Electromigration lifetimes and line Resistance are compared for different metallurgy options.
And while Intel is no longer using pure cobalt, in some respects their use of cobalt is increasing overall. Whereas Intel’s 10nm processes only used cobalt for the contact gate and first two metal layers, Intel 4 is expanding the use of eCu to the first 5 metal layers. As a result, the lowest-third of the complete metal layer stack in a chip is using Intel’s cobalt-clad copper. Intel has, however, removed cobalt from the gate itself; that’s now pure tungsten, rather than a mix of tungsten and cobalt.
| Intel 4 Metal Stack | ||
| Layer | Metal | Pitch |
| Fin | - | 30 nm |
| Gate | Tungsten | 50 nm |
| Metal 0 | Copper w/Cobalt Cladding | 30 nm |
| Metal 1 | Copper w/Cobalt Cladding | 50 nm |
| Metal 2 | Copper w/Cobalt Cladding | 45 nm |
| Metal 3 | Copper w/Cobalt Cladding | 50 nm |
| Metal 4 | Copper w/Cobalt Cladding | 45 nm |
| Metal 5, 6 | Copper | 60 nm |
| Metal 7, 8 | Copper | 84 nm |
| Metal 9, 10 | Copper | 98 nm |
| Metal 11, 12 | Copper | 130 nm |
| Metal 13, 14 | Copper | 160 nm |
| Metal 15 | Copper | 280 nm |
| Giant Metal 0 | Copper | 1080 nm |
| Giant Metal 1 | Copper | 4000 nm |
All told, the number of metal layers for Intel 4 has increased versus Intel 7. Whereas the latter had 15 metal layers for logic, Intel 4 squeezes in a 16th layer. This is joined by the usual two layers for power routing, which Intel terms its giant layers due to their relatively massive pitches of 1080nm and 4000nm.
Alongside the tighter gate and metal layer pitches, another area where Intel is gaining density improvements from design rule changes for interconnects. With Intel 4, Intel has moved to what they’re calling a gridded interconnect design, which in short, only allows for vias going between metal layers to be placed per a pre-determined grid. Previously, vias could be placed anywhere, which allowed for some flexibility, but had other trade-offs.
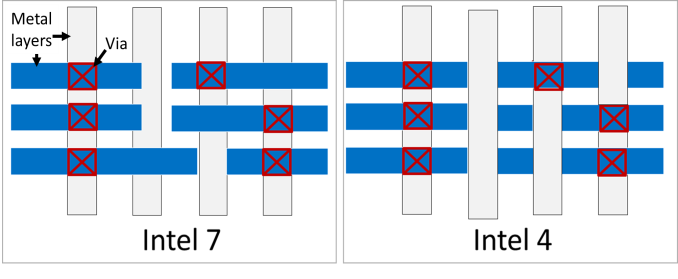
Design rules changed from traditional (left) to gridded (right) to improve yield and improve performance though capacitance reduction
According to Intel, the use of grids has improved both the yields of the process by reducing variability, as well as how they go about optimizing designs. The switch also has a side benefit of allowing Intel to avoid having to use complex, multi-patterned EUV for their interconnects.
Finally, as previously mentioned, the use of EUV is also allowing Intel to reduce the number of steps (and the number of masks) required to fab a chip. While the company isn’t offering absolute numbers, on a relative basis Intel 4 requires 20% fewer masks than Intel 7. Had Intel not done this, the number of masks required would have instead shot up by around 30% due to the number of multi-patterning steps required.
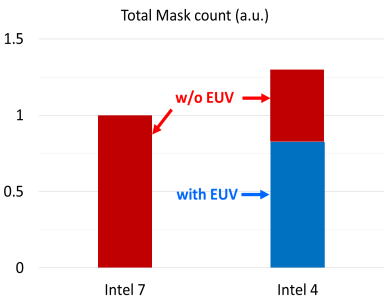
Extensive employment of EUV enables feature scaling and process simplification
The use of EUV is also having a positive impact on Intel’s yields. Though the company isn’t providing exact numbers, the reduction in the number of steps offers fewer opportunities for anything to go wrong that would introduce a defect on a wafer.
Intel 4 Performance: 21.5% More Perf at iso-power/40% Less Power at iso-frequency
Density improvements aside, what kind of performance improvements is Intel seeing for the Intel 4 process? In short, Intel is seeing above-average gains in both frequencies and power efficiency.
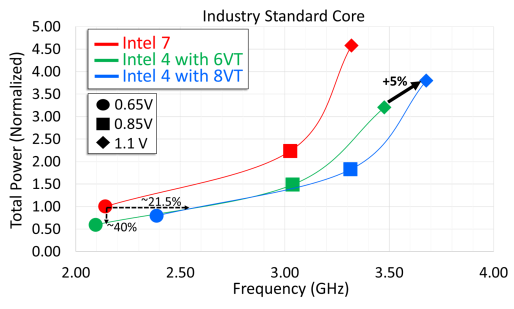
Circuit analysis of industry standard core shows 21.5% performance gain at matched power over Intel 7 at 0.65V. 8VT flow enables 5% performance gain over 6VT at high voltages.
At an iso-power of 0.65v, Intel is seeing a 21.5% increase in clockspeeds attainable versus Intel 7. With that said, 0.65v is at the low end of the curve, and Intel’s graph does show diminishing returns as you go farther up in voltage; at 0.85v and beyond the iso-power gains are closer to 10%. According to Intel, they can squeeze out another 5% or so by using cells designed for higher threshold voltages (8VT), which comes at a cost of higher total power consumption versus standard cells.
And if we take things from the other end, Intel is reporting even larger gains on the power efficiency front with Intel 4. At iso-frequency – in this case around 2.1GHz – Intel is seeing 40% lower power consumption. There are again diminishing returns as frequencies increase (up until Intel 7 hits its practical limits), but it’s more consistent than the performance/frequency gains. This mirrors what we’ve seen with other process nodes – including Intel 7 at its launch – where newer nodes are reducing power consumption at a much greater rate than they’re enabling higher clockspeeds. A full CPU built on the Intel 4 process could conceivably save a great deal of power – so long as you don’t mind it not clocking any higher than before.
All told, the performance gains outlined in Intel’s paper mirror those that they have been claiming up until now, such as the 20% perf-per-watt gains for Intel 4 discussed at last summer’s process roadmap update. For the last year Intel has been approaching the finishing line for Intel 4 development, so as their paper outlines, they appear to be on-track for delivering on their performance gains.
Meanwhile, Intel is also reporting good developments in cost scaling from Intel 7 to Intel 4, though once again the company isn’t providing specific numbers. 1 EUV layer does end up being more expensive than 1 DUV layer, but because EUV eliminates a bunch of multi-patterning, it helps to bring down the total costs by reducing the total number of steps. The switch to EUV is also reducing a bit of the capital pressure on Intel, as Intel 4 doesn’t require quite as much clean room space (though it’s by no means a small amount overall).
Ultimately, as Intel looks to ship Meteor Lake and other first-generation Intel 4 products in 2023, what remains to be seen is how quickly Intel can get their new process node up and running to the standards of high-volume manufacturing. With Meteor Lake samples already in Intel’s labs, Intel is getting ever closer to finally entering the EUV age. But for Intel, hitting all of their goals getting there means not just scaling up production from their Hillsboro development fab, but also mastering the interesting task of replicating their process to Ireland and the other Intel fabs that will be used for Intel 4.








129 Comments
View All Comments
Zoolook - Wednesday, June 15, 2022 - link
They don't necessarily need all EUV scanners in place to start risk production only for full production speed.SiliconFly - Friday, June 24, 2022 - link
Intel 4 risk production in Q4 2022 & volume/ramp in Q2 2023. Products in market by late Q3 2023 or early Q4 2023.Sunrise089 - Monday, June 13, 2022 - link
Competition is good and certainly point taken that TSMC’s ‘5nm’ is no more accurate than Intel’s ‘4’ terminology, but the roadmap showing Intel going from 4 -> 3 -> 20a -> 18a in 5 quarters seems incredibly aggressive. I’d be willing to wager foolish sums that timeline won’t be met.techjunkie123 - Monday, June 13, 2022 - link
Almost like they're hoping investors will 5ake the bait.....tuxRoller - Monday, June 13, 2022 - link
Is this paper generally available?I visited the initial link for the presentation at the conference but couldn't find the pdf in question.
A Google search also turned up nothing.
Ryan Smith - Monday, June 13, 2022 - link
Even though Intel has distributed it to the press with no further embargo, it looks like they haven't posted it for download. As it's not clear that I have permission to distribute it, I've poked Intel to see what's up.Ryan Smith - Tuesday, June 14, 2022 - link
Intel is not releasing the paper at this time. I may be publicly available on June 17th, which is when VLSI Symposium's content is released more widely.mode_13h - Wednesday, June 15, 2022 - link
Thanks for the follow up!Anymoore - Monday, June 13, 2022 - link
Strange that so much is being discussed about this paper (not just at this site) even before Intel presented it - what happened to the usual embargo?Anyway, it's already mentioned at two other sites that the 30 nm minimum pitch is not done by EUV but by self-aligned quadruple patterning (as before).
Ryan Smith - Tuesday, June 14, 2022 - link
"Strange that so much is being discussed about this paper (not just at this site) even before Intel presented it - what happened to the usual embargo?"Intel gave the press a preview of the paper ahead of the Tuesday embargo. So our embargo has already passed.