AMD Discloses Bobcat & Bulldozer Architectures at Hot Chips 2010
by Anand Lal Shimpi on August 24, 2010 1:33 AM ESTPhysical Register Files to Save Power
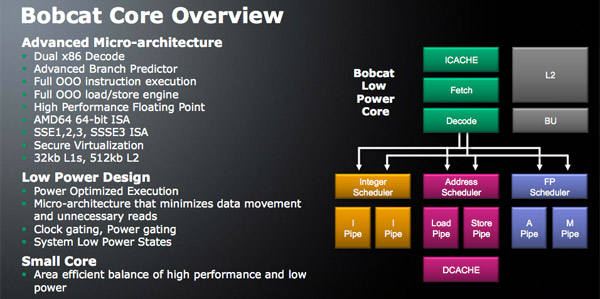
The original x86 instruction set has a very limited number of registers (8). In order to maintain backwards compatibility with legacy x86 code, the ISA and associated registers were preserved. To scale performance with wide out of order architectures however, we needed larger register files. The solution was to enable register renaming, where the hardware could have additional registers not defined in the x86 spec and rename them on the fly.
Register renaming is done in all modern day x86 processors. There are two approaches to register renaming. The current Phenom II/Opteron approach actually carries the data from renamed registers along with the instruction as it moves through queues before it gets executed. You effectively create very wide instructions, which is horribly power inefficient (moving data on a chip takes a lot of power) although it gets the job done from a performance standpoint.
The alternative is something that we don’t see used in any current generation microprocessors. Instead of carrying data along with the instructions, you simply carry pointers to the data with those instructions. There’s added management complexity but you don’t have to worry about moving lots of data around, and therefore avoid much of the power penalty.

Bobcat (as well as Bulldozer) uses physical register files to save power. Intel actually did this in the Pentium 4 but hasn’t used PRFs since. AMD argues that with power as a major driver of design, PRFs will be necessary in future architectures.
Bobcat’s Performance Expectations
With nearly the same pipeline depth as Atom (15 vs. 16 stages), nearly the same cache latencies, the same instruction issue width and presumably competitive clock speeds (~1.5GHz), Bobcat based microprocessors should inherently outperform Atom thanks to its out of order architecture.
Atom does hold an advantage in that each core is multithreaded, so heavily threaded apps may have an advantage on Intel’s architecture. That being said, by far the biggest issue we have with Atom based netbooks is their single threaded performance that contributes to an overall slow user experience. Bobcat should hopefully address that.
On the threaded side, AMD does have another solution. As I mentioned before, Bobcat won’t be used in a microprocessor by itself - Ontario will feature two of them. AMD said that future designs are expected to integrate 2 or 4 Bobcat cores, while there are no plans to produce a single core version it’s always possible.
I believe a dual core Ontario based on Bobcat, if clocked high enough, could deliver a good enough balance of single and multithreaded performance to really challenge Atom in the netbook space. The assumption is that graphics performance will be much better than Atom with Ontario integrating an AMD GPU.
AMD’s official line is that Ontario will be able to deliver 90% of the performance of a mainstream notebook in less than half the die area. AMD isn’t just looking to compete with Atom, but go after even the CULV market with Ontario. Only time will tell if the latter is over zealous.
Power Concerns
AMD calls Bobcat sub-1W capable, which seems to imply that short of a smartphone Bobcat could go anywhere Atom could go. Technically, if AMD wanted to, even getting one into a smartphone wouldn’t be impossible - it would just require a healthy investment in chipsets.

It remains to be seen how good TSMC’s 40nm process will be compared to Atom’s Intel-manufactured 45nm transistors in terms of power consumption. Presumably the out of order aspect of the design will guarantee higher power consumption than Atom, but for the netbook/CULV notebook market the added performance may be worth the added power consumption.








76 Comments
View All Comments
Mr Perfect - Wednesday, August 25, 2010 - link
It sounds like AMD will be selling by the integer core though, not by module. There's this from Page 4:"Processors may implement anywhere from one to four Bulldozer modules and will be referred to as 2 to 8 core CPUs."
So they will be referring to four module APUs as having eight cores, rather then a quad core with HyperThreading.
silverblue - Wednesday, August 25, 2010 - link
Sorry, I did mean to tackle the part of your thread dealing with different versions of Bulldozer. Valencia is a server version of Zambezi, i.e. 4 modules/8 threads. Interlagos is 8 modules/16 threads.From AMD's own figures, each module is 1.8 times the speed of a current K10.5 core at the same clock speed. It is a little unfair to compare "core" to core due to the way they're designed and implemented. Considering each K10.5 core has three ALUs and Bulldozer has two per integer core, 90% of that integer performance is very good - for a quad core CPU in the current sense, Bulldozer would theoretically outpace Phenom II by 80% in integer work by only having 33% more integer resources, assuming the chip is well fed. If the rumours about a quad-channel memory bus are correct, you'd hope it would be.
jeremyshaw - Wednesday, August 25, 2010 - link
I believe Intel also delegated some Atom production to TSMC, unless if I am wrong?Penti - Thursday, August 26, 2010 - link
TSMC also does manufacture VIAs / Centaur Tech x86 processor.Probably a few others too. There's some x86 SoCs for embedded stuff from other vendors.
Perisphetic - Wednesday, August 25, 2010 - link
It's time to kick ass and chew bubble gum... and AMD is all outta gum.NaN42 - Wednesday, August 25, 2010 - link
At first: I think AMD made a huge progress with Bulldozer.But I'm wondering how the FPU will work exactly. A look at the latencies (especially of fma-instructions) would be interesting too. Another question is, if it is possible to start one independent multiply and one addition at the same time in a FMAC-unit. Furthermore the throughput is of interest. Is it one mul and add instruction per cycle? Is there any advantage to use 256 bit AVX-instructions, besides shorter code?
I appreciate that AMD will drop most 3Dnow-instructions because these are just outdated. Perhaps they could also drop MMX instructions but maintain x87-instructions because these are sometimes useful and needed.
I expect the decoder besides the FPU (compared to Sandy Bridge) to be another bottleneck because the 4-wide decoder has to feed two nearly independent cores and todays 3-wide decoders (except those in Nehalem/Westmere) are sometimes a bottleneck in a single core design.
@Ontario: I expect this platform to be much more powerful than the Atom platforms. Perhaps it will even be much more efficient than Atom. A direct comparison between Ontario and VIA Nano 3000 might be interesting especially when VIA releases dual core chips.
GourdFreeMan - Thursday, August 26, 2010 - link
It seems that AMD is ceding the traditional laptop and desktop market to Intel and chasing the server market and Atom/ARM's market with Bulldozer and Bobcat respectively. Lower theoretical peak IPC and greater parallelism target well the high level of data and transaction level parallelism in the server market, but existing consumer software excepting video encoding and a handful of games still tend to favor single threaded performance over parallelism. I suppose we should wait for benchmarks in actual applications to see how well architectural improvements have impacted the performance of AMD's new designs, but I imagine some people are already disappointed. Too bad the resources in both integer cores in a module can't work on a single thread, otherwise we could have had a very serious contender on the desktop...silverblue - Thursday, August 26, 2010 - link
He sure seemed confusing on the comments page of his blog a few weeks back. Understandably evasive considering he's a server tech guy, not consumer tech, plus AMD were yet to reveal these details, but he was comparing 16 Bulldozer cores to 12 Magny Cours cores, which is technically incorrect as they're not comparable UNLESS you're talking about integer cores. At least, that's my interpretation.AMD will probably market Zambezi as an 8-core CPU in order to woo the more-is-better crowd, but regardless of how it handles multi-threading, I still view a module as an actual core virtue of the fact that the "cores" are not independant of the module they belong to. I know I'm wrong and that's fine, but it helps in understanding the technology better - eight cores that exist in pairs and share additional resources might serve to confuse.
gruffi - Thursday, August 26, 2010 - link
A 12-core Magny-Cours has 12 "integer cores" and 12 128-bit FPUs. A 16-core Interlagos has 16 "integer cores" and 16 128-bit FMACs. Why is it technically not comparable? At least you know you are wrong. ;)silverblue - Friday, August 27, 2010 - link
The implementation is very different to what AMD have done before, that's what I'm trying to get at. Everyone knew that despite Intel and AMD having different types of quad core processor prior to Nehalem, they were still classed the same so I suppose it doesn't matter in the grand scheme of things. There's nothing to stop AMD from releasing a 24-"core" Bulldozer; it shouldn't be any larger than Magny-Cours - perhaps slightly smaller in the end - yet its integer performance would be through the roof.However, people are bemoaning the fact that for 33% more "cores", AMD are only getting 50% extra performance - it's worth bearing in mind that AMD does this with 4 less, albeit better utilised ALUs than Magny-Cours (32 compared to 36). Make no mistake, Bulldozer is far more efficient and capable in this scenario, but I can't help wondering how strong Phenom II may have been if it'd had a slightly more elegant design.