ADATA XPG V1.0 Low Voltage Review: 2x8 GB at DDR3L-1600 9-11-9 1.35 V
by Ian Cutress on December 6, 2013 2:00 PM ESTCPU Compute
One side I like to exploit on CPUs is the ability to compute and whether a variety of mathematical loads can stress the system in a way that real-world usage might not. For these benchmarks we are ones developed for testing MP servers and workstation systems back in early 2013, such as grid solvers and Brownian motion code. Please head over to the first of such reviews where the mathematics and small snippets of code are available.
3D Movement Algorithm Test
The algorithms in 3DPM employ uniform random number generation or normal distribution random number generation, and vary in various amounts of trigonometric operations, conditional statements, generation and rejection, fused operations, etc. The benchmark runs through six algorithms for a specified number of particles and steps, and calculates the speed of each algorithm, then sums them all for a final score. This is an example of a real world situation that a computational scientist may find themselves in, rather than a pure synthetic benchmark. The benchmark is also parallel between particles simulated, and we test the single thread performance as well as the multi-threaded performance. Results are expressed in millions of particles moved per second, and a higher number is better.
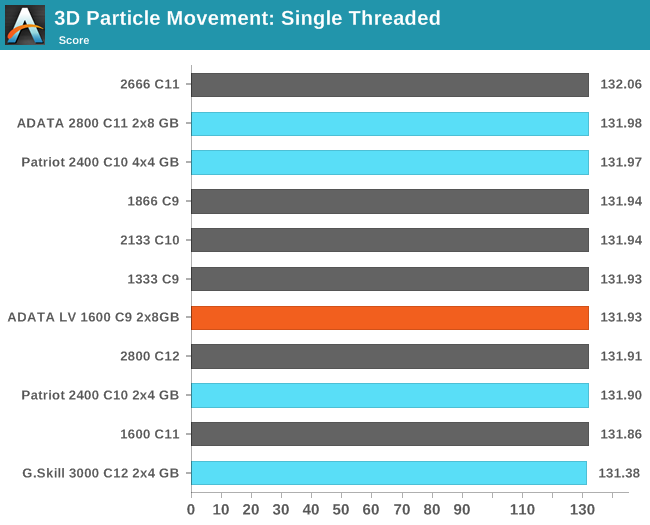
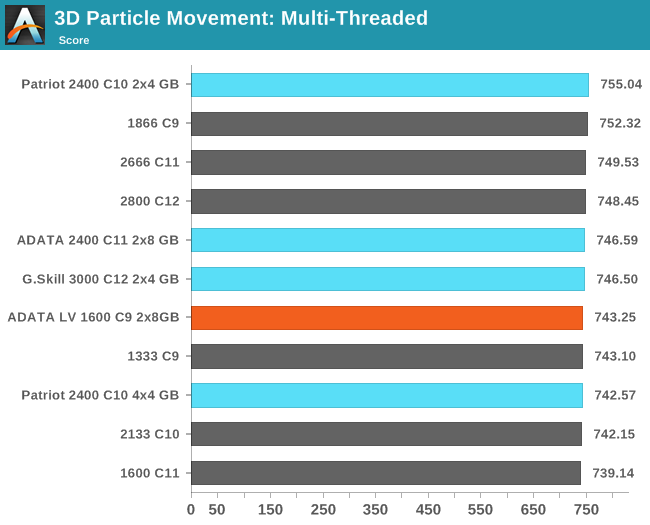
N-Body Simulation
When a series of heavy mass elements are in space, they interact with each other through the force of gravity. Thus when a star cluster forms, the interaction of every large mass with every other large mass defines the speed at which these elements approach each other. When dealing with millions and billions of stars on such a large scale, the movement of each of these stars can be simulated through the physical theorems that describe the interactions. The benchmark detects whether the processor is SSE2 or SSE4 capable, and implements the relative code. We run a simulation of 10240 particles of equal mass - the output for this code is in terms of GFLOPs, and the result recorded was the peak GFLOPs value.

Grid Solvers - Explicit Finite Difference
For any grid of regular nodes, the simplest way to calculate the next time step is to use the values of those around it. This makes for easy mathematics and parallel simulation, as each node calculated is only dependent on the previous time step, not the nodes around it on the current calculated time step. By choosing a regular grid, we reduce the levels of memory access required for irregular grids. We test both 2D and 3D explicit finite difference simulations with 2n nodes in each dimension, using OpenMP as the threading operator in single precision. The grid is isotropic and the boundary conditions are sinks. We iterate through a series of grid sizes, and results are shown in terms of ‘million nodes per second’ where the peak value is given in the results – higher is better.


Grid Solvers - Implicit Finite Difference + Alternating Direction Implicit Method
The implicit method takes a different approach to the explicit method – instead of considering one unknown in the new time step to be calculated from known elements in the previous time step, we consider that an old point can influence several new points by way of simultaneous equations. This adds to the complexity of the simulation – the grid of nodes is solved as a series of rows and columns rather than points, reducing the parallel nature of the simulation by a dimension and drastically increasing the memory requirements of each thread. The upside, as noted above, is the less stringent stability rules related to time steps and grid spacing. For this we simulate a 2D grid of 2n nodes in each dimension, using OpenMP in single precision. Again our grid is isotropic with the boundaries acting as sinks. We iterate through a series of grid sizes, and results are shown in terms of ‘million nodes per second’ where the peak value is given in the results – higher is better.









35 Comments
View All Comments
MelvisLives - Friday, December 6, 2013 - link
even for things like folding the T/S series make little senseI run my normal 84W haswell i5 at 2.6Ghz with a -0.26V offset to allow me to run it in my htpc case without a cpu fan, maths says its max tdp will be about 40W, with the added bonus I can increase it if i want or move case.
so i guess my point is, T series cant be made to hit the same levels as a standard i5 but a standard i5 will undervolt/underclock to T series level, and they cost exactly the same, making T series poor value.
popej - Friday, December 6, 2013 - link
I have recently flashed BIOS update, which included new microcode from Intel. As I understand this microcode update not only disabled any overclock for non-K Haswell (multicore enhancement) but also possibility to undervolt CPU. It is quite possible, that your i5 could be affected too.MelvisLives - Saturday, December 7, 2013 - link
thats sad to hear if its true, and does change things slightly, but it also means that intel are aware how poor value the T/S chips are and are trying to keep a market for them since a i5-4570 is the same price as an i5-4570S and 4570T.peterfares - Sunday, December 8, 2013 - link
But that raises the question: why bother? If they're the same chips sold at the same price, why artificially make three different models with different capabilities? It makes sense if they sell them for different prices (even if it is a douchy thing to do).ShieTar - Tuesday, December 10, 2013 - link
The non-T/S versions are usually better/more efficient than specified, so in most cases they will indeed perform the same as the T/S. But you could be unlucky and get a unusually inefficient normal chip, which really uses up its 84W TDP.purerice - Friday, December 6, 2013 - link
Thank you for your explanation. I actually had been tempted by the 4770S/4670T because I thought there was a bigger difference. I am still in the age where underclocking was done manually.As for this RAM, the article was very in depth and well-done but I am a little disappointed that the article didn't show any make or break situations. For example, all of the dGPU framerates were playable while none of the iGPU framerates were playable. The tests should have been done at resolutions that would have produced borderline playability to better see in which situations the there would be a noticeable difference.
MrSpadge - Sunday, December 8, 2013 - link
Agreed: regular CPUs with lowered voltage are far better value than S/T models. Or underclocked and undervolted, if necessary. This does involve manual testing, though.oranos - Friday, December 6, 2013 - link
what's the point of "low voltage" ram. I fail to see any real world difference between 1.35v and 1.5v standard.MrSpadge - Sunday, December 8, 2013 - link
You've got to run a lot of them, like in a server farm, for this to matter.shing3232 - Friday, December 6, 2013 - link
I would like to have this kind of ram at laptop