The AMD Radeon R9 Fury X Review: Aiming For the Top
by Ryan Smith on July 2, 2015 11:15 AM ESTFiji’s Layout
So what did AMD put in 8.9 billion transistors filling out 596mm2? The answer as it turns out is quite a bit of hardware, though at the same time perhaps not as much (or at least not in the ratios) as everyone was initially hoping for.
The overall logical layout of Fiji is rather close to Hawaii after accounting for the differences in the number of resource blocks and the change in memory. Or perhaps Tonga (R9 285) is the more apt comparison, since that’s AMD’s other GCN 1.2 GPU.
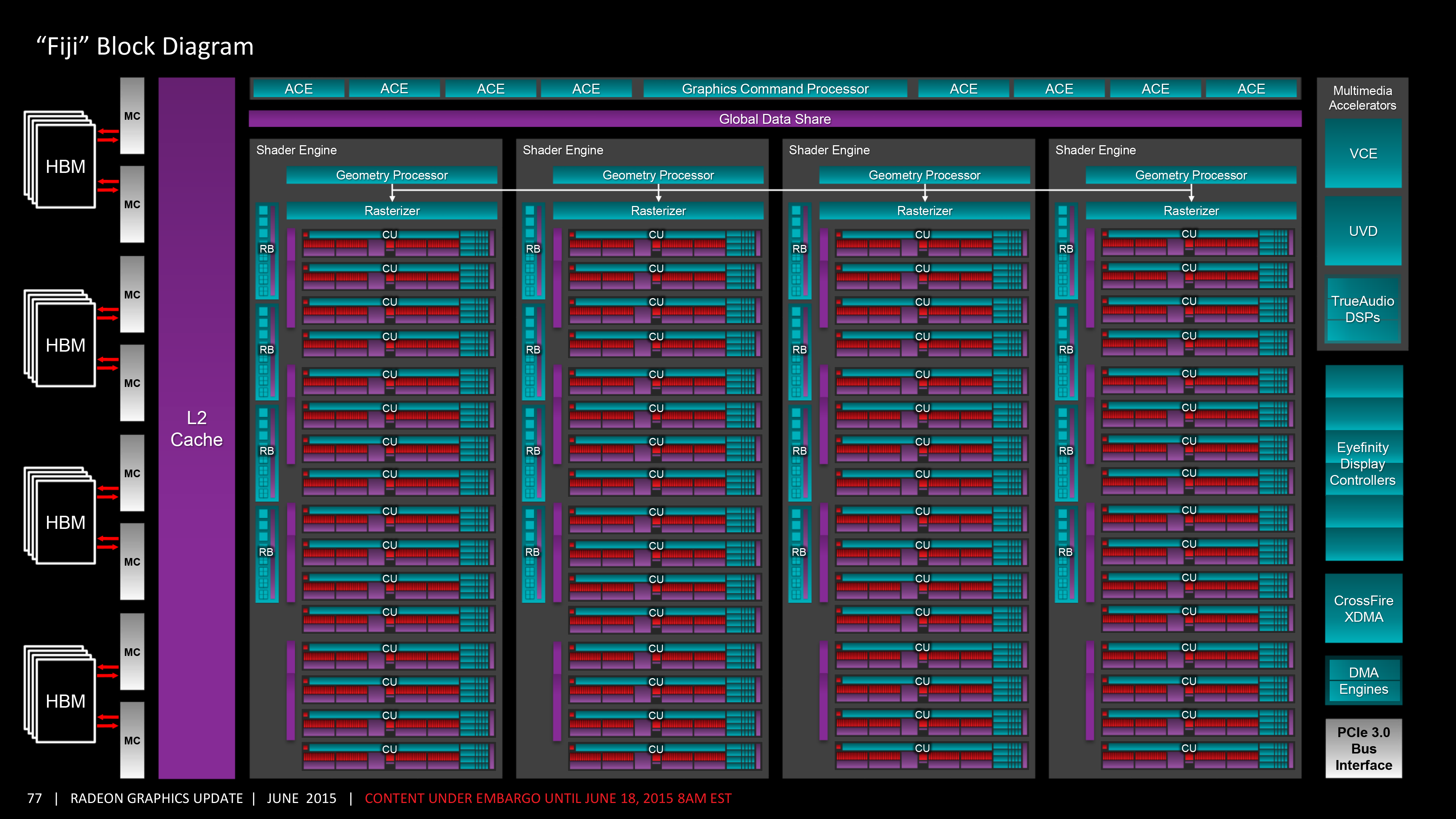
In either case the end result is quite a bit of shading power for Fiji. AMD has bumped up the CU count from 44 to 64, or to put this in terms of the number of ALUs/stream processors, it’s up from 2816 to a nice, round 4096 (2^12). As we discussed earlier FP64 performance has been significantly curtailed in the name of space efficiency, otherwise at Fury X’s stock clockspeed of 1050MHz, you’re looking at enough ALUs to push 8.6 TFLOPs of FP32 operations.
These 64 CUs in turn are laid out in a manner consistent with past GCN designs, with AMD retaining their overall Shader Engine organization. Sub-dividing the GPU into four parts, each shader engine possesses 1 geometry unit, 1 rasterizer unit, 4 render backends (for a total of 16 ROPs), and finally, one-quarter of the CUs, or 16 CUs per shader engine. The CUs in turn continue to be organized in groups of 4, with each group sharing a 16KB L1 scalar cache and 32KB L1 instruction cache. Meanwhile since Fiji’s CU count is once again a multiple of 16, this also does away with Hawaii’s oddball group of 3 CUs at the tail-end of each shader engine.
Looking at the broader picture, what AMD has done relative to Hawaii is to increase the number of CUs per shader engine, but not changing the number of shader engines themselves or the number of other resources available for each shader engine. At the time of the Hawaii launch AMD told us that the GCN 1.1 architecture had a maximum scalability of 4 shader engines, and Fiji’s implementation is consistent with that. While I don’t expect AMD will never go beyond 4 shader engines – there are always changes that can be made to increase scalability – given what we know of GCN 1.1’s limitations, it looks like AMD has not attempted to increase their limits with GCN 1.2. What this means is that Fiji is likely the largest possible implementation of GCN 1.2, with as many resources as the architecture can scale out to without more radical changes under the hood to support more scalability.
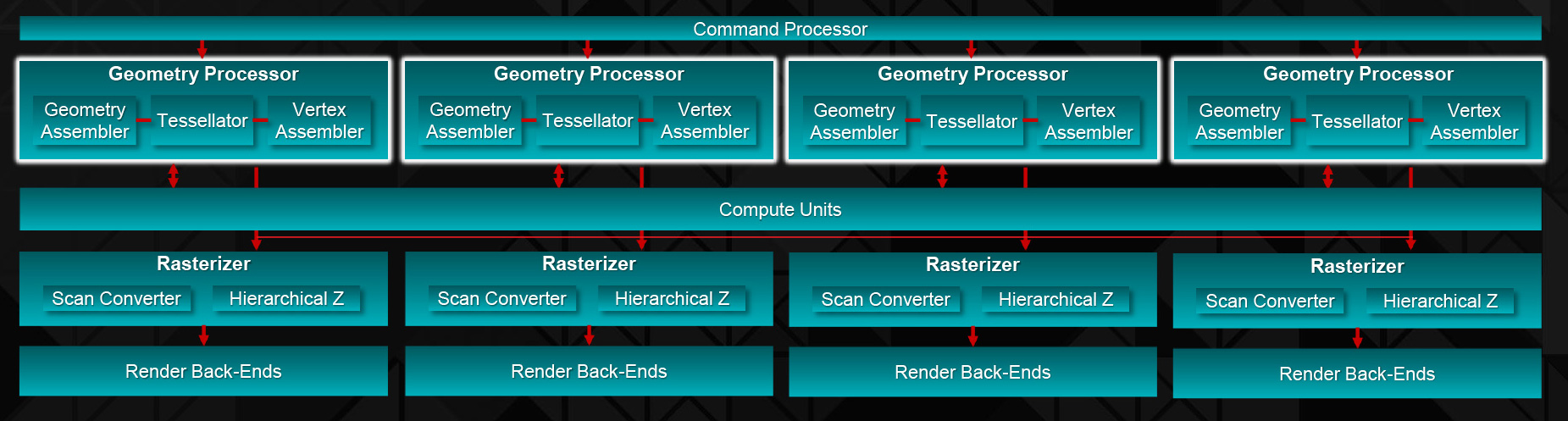
Along those lines, while shading performance is greatly increased over Hawaii, the rest of the front-end is very similar from a raw, theoretical point of view. The geometry processors, which as we mentioned before are organized to 1 per shader engine, just as was the case with Hawaii. With a 1 poly/clock limit here, Fiji has the same theoretical triangle throughput at Hawaii did, with real-world clockspeeds driving things up just a bit over the R9 290X. However as we discussed in our look at the GCN 1.2 architecture, AMD has made some significant under-the-hood changes to the geometry processor design for GCN 1.2/Fiji in order to boost their geometry efficiency, making Fiji’s geometry fornt-end faster and more efficient than Hawaii. As a result the theoretical performance may be unchanged, but in the real world Fiji is going to offer better geometry performance than Hawaii does.
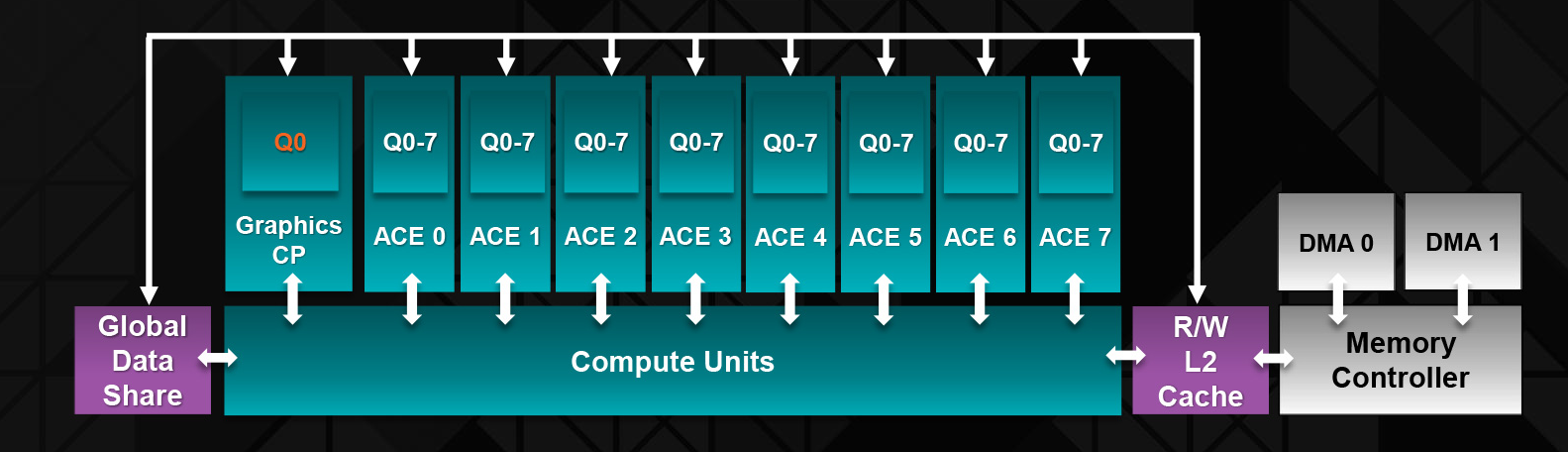
Meanwhile the command processor/ACE structure remains unchanged from Hawaii. We’re still looking at a single graphics command processor paired up with 8 Asynchronous Compute Engines here, and if AMD has made any changes to this beyond what is necessary to support the GCN 1.2 feature set (e.g. context switching, virtualization, and FP16), then they have not disclosed it. AMD is expecting asynchronous shading to be increasingly popular in the coming years, especially in the case of VR, so Fiji’s front-end is well-geared towards the future AMD is planning for.
Moving on, let’s switch gears and talk about the back-end of the processor. There are some significant changes here due to HBM, as to be expected, but there are also some other changes going on as well that are not related to HBM.
Starting with the ROPs, the ROP situation for Fiji remains more or less unchanged from Hawaii. Hawaii shipped with 64 ROPs grouped in to 16 Render Backends (RBs), which at the time AMD told us was the most a 4 shader engine GCN GPU could support. And I suspect that limit is still in play here, leading to Fiji continuing to pack 64 ROPs. Given that AMD just went from 32 to 64 a generation ago, another jump seemed unlikely anyhow (despite earlier rumors to the contrary), but in the end I suspect that AMD had to consider architectural limits just as much as they had to consider performance tradeoffs of more ROPs versus more shaders.
In any case, the real story here isn’t the number of ROPs, but their overall performance. Relative to Hawaii, Fiji’s ROP performance is getting turbocharged for two major reasons. The first is GCN 1.2’s delta color compression, which significantly reduces the amount of memory bandwidth the ROPs consume. Since the ROPs are always memory bandwidth bottlenecked – and this was even more true on Hawaii as the ROP/bandwidth ratio fell relative to Tahiti – anything that reduces memory bandwidth needs can boost performance. We’ve seen this first-hand on R9 285, which with its 256-bit memory bus had no problem keeping up with (and even squeaking past) the 384-bit bus of the R9 280.

The other factor turbocharging Fiji’s ROPs is of course the HBM. In case GCN 1.2’s bandwidth savings were not enough, Fiji also just flat-out has quite a bit more memory bandwidth to play with. The R9 290X and its 5Gbps, 512-bit memory bus offered 320GB/sec, a value that for a GDDR5-based system has only just been overshadowed by the R9 390X. But with Fiji, the HBM configuration as implemented on the R9 Fury X gives AMD 512GB/sec, an increase of 192GB/sec, or 60%.
Now AMD did not just add 60% more memory bandwidth because they felt like it, but because they’re putting that memory bandwidth to good use. The ROPs would still gladly consume it all, and this doesn’t include all of the memory bandwidth consumed by the shaders, the geometry engines, and the other components of the GPU. GPU performance has long outpaced memory bandwidth improvements, and while HBM doesn’t erase any kind of conceptual deficit, it certainly eats into it. With such a significant increase in memory bandwidth and combined with GCN 1.2’s color compression technology, AMD’s effective memory bandwidth to their ROPs has more than doubled from Hawaii to Fiji, which will go a long way towards increasing ROP efficiency and real-world performance. And even if a task doesn’t compress well (e.g. compute) then there’s still 60% more memory bandwidth to work with. Half of a terabyte-per-second of memory bandwidth is simply an incredible amount to have for such a large pool of VRAM, since prior to this only GPU caches operated that quickly.
Speaking of caches, Fiji’s L2 cache has been upgraded as well. With Hawaii AMD shipped a 1MB cache, and now with Fiji that cache has been upgraded again to 2MB. Even with the increase in memory bandwidth, going to VRAM is still a relatively expensive operation, so trying to stay on-cache is beneficial up to a point, which is why AMD spent the additional transistors here to double the L2 cache. Both AMD and NVIDIA have gone with relatively large L2 caches in this latest round, and with their latest generation color compression technologies it makes a lot of sense; since the L2 cache can store color-compressed tiles, all of a sudden L2 caches are a good deal more useful and worth the space they consume.
Finally, we’ll get to HBM in a more detail in a bit, but let’s take a quick look at the HBM controller layout. With Fiji there are 8 HBM memory controllers, and each HBM controller in turn drives one-half of an HBM stack, meaning 2 controllers are necessary to drive a full stack. And while AMD’s logical diagram doesn’t illustrate it, Fiji is almost certainly wired such that each HBM memory controller is tightly coupled with 8 ROPs and 256KB of L2 cache. AMD has not announced any future Fiji products with less than 4GB of VRAM, so we’re not expecting any parts with disabled ROPs, but if they did that would give you an idea of how things would be disabled.








458 Comments
View All Comments
chizow - Friday, July 3, 2015 - link
No silverblue, you contributed just as much to the unrealistic expectations during the Rebrandeon run-up along with unrealistic expectations for HBM and Fury X. But in the end it doesn't really matter, AMD failed to meet their goal even though Nvidia handed it to them on a silver platter by launching the 980Ti 3 weeks ahead of AMD.And spate of returns for the 970 memory fiasco? Have any proof of that? Because I have plenty of proof that shows Nvidia rode the strength of the 970 to record revenues, near-record market share, and a 3:1 ownership ratio on Steam compared to the entire R9 200 series.
If Fury X is an experiment as you claim, it was certainly a bigger failure than what was documented here at a time AMD could least afford it, being the only new GPU they will be launching in 2015 to combat Nvidia's onslaught of Maxwell chips.
mapesdhs - Friday, July 3, 2015 - link
A lot of the 970 hate reminded me of the way some people carried on dumping on OCZ long after any trace of their old issues were remotely relevant. Sites did say that the 970 RAM issue made no difference to how it behaved in games, but of course people choose to believe what suits them; I even read comments from some saying they wanted it to be all deliberate as that would more closely match their existing biased opinions of NVIDIA.I would have loved to have seen the Fury X be a proper rival to the 980 Ti, the market needs the competition, but AMD has goofed on this one. It's not as big a fiasco as BD, but it's bad enough given the end goal is to make money and further the tech.
Fan boys will buy the card of course, but they'll never post honestly about CF issues, build issues, VRAM limits, etc.
It's not as if AMD didn't know NV could chuck out a 6GB card, remember NV was originally going to do that with the 780 Ti but didn't bother in the end because they didn't have to. Releasing the 980 Ti before the Fury X was very clever, it completely took the the wind out of AMD's sails. I was expecting it to be at least level with a 980 Ti if it didn't have a price advantage, but it loses on all counts (for all the 4K hype, 1440 is far more relevant atm).
silverblue - Friday, July 3, 2015 - link
How about you present proof of such indescretions? I believe my words contained a heavy dose of IF and WAIT AND SEE. Speculation instead of presenting facts when none existed at the time. Didn't you say Tahiti was going to be a part of the 300 series when in fact it never was? I also don't recall saying Fury X would do this or do that, so the burden of proof is indeed upon you.Returns?
http://www.techpowerup.com/209409/perfectly-functi...
http://www.kitguru.net/components/graphic-cards/an...
http://www.guru3d.com/news-story/return-rates-less...
I can provide more if you like. The number of returns wasn't exactly a big issue for NVIDIA, but it still happened. A minor factor which may have resulted in a low number of returns was the readiness for firms such as Amazon and NewEgg to offer 20-30% rebates, though I imagine that wasn't a common occurrence.
Fury X isn't a failure as an experiment, the idea was to integrate a brand new memory architecture into a GPU and that worked, thus paving the way for more cards to incorporate it or something similar in the near future (and showing NVIDIA that they can go ahead with their plans to do the exact same thing). The only failure is marketing it as a 4K card when it clearly isn't. An 8GB card would've been ideal and I'd imagine that the next flagship will correct that, but once the cost drops, throwing 2GB HBM at a mid-range card or an APU could be feasible.
chizow - Sunday, July 5, 2015 - link
I've already posted the links and you clearly state you don't think AMD would Rebrandeon their entire 300 desktop retail series when they clearly did. I'm sure I didn't say anything about Tahiti being rebranded either, since it was obvious Tonga was being rebranded and basically the same thing as Tahiti, but you were clearly skeptical the x90 part would just be a Hawaii rebrand when indeed that became the case.And lmao at your links, you do realize that just corroborates my point the "spate of 970 returns" you claimed was a non-issue right? 5% is within range of typical RMA rates so to claim Nvidia experienced higher than normal return rates due to the 3.5GB memory fiasco is nonsense plain and simple.
And how isn't Fury X a failed experiment when AMD clearly had to make a number of concessions to accommodate HBM, which ultimately led to 4GB limitations on their flagship part that is meant to go up against 6GB and 12GB and even falls short of its own 8GB rebranded siblings?
silverblue - Monday, July 6, 2015 - link
No, this is what was said in the comments for http://www.anandtech.com/comments/9241/amd-announc...You: "And what if the desktop line-up follows suit? We can ignore all of them too? No, not a fanboy at all, defend/deflect at all costs!"
Myself: "What if?
Nobody knows yet. Patience, grasshopper."
Dated 15th May. You'll note that this was a month prior to the launch date of the 300 series. Now, unless you had insider information, there wasn't actually any proof of what the 300 series was at that time. You'll also note the "Nobody knows yet." in my post in response to yours. That is an accurate reflection of the situation at that time. I think you're going to need to point out the exact statement that I made. I did say that I expected the 380 to be the 290, which was indeed incorrect, but again without inside information, and without me stating that these would indeed be the retail products, there was no instance of me stating my opinions as fact. I think that should be clear.
RMA return rates: https://www.pugetsystems.com/labs/articles/Video-C...
Fury X may or may not seem like a failed experiment to you - I'm unsure as to what classifies as such in your eyes - but even with the extra RAM on its competitors, the gap between them and Fury X at 4K isn't exactly large, so... does Titan X need 12GB? I doubt it very much, and in my opinion it wouldn't have the horsepower to drive playable performance at that level.
chizow - Monday, July 6, 2015 - link
There's plenty of other posts from you stating similar Silverblue, hinting at tweaks to silicon and GCN level when none of that actually happened. And there was actually plenty of additional proof besides what AMD already provided with their OEM and mobile rebrand stacks. The driver INFs I mentioned have always been a solid indicator of upcoming GPUs and they clearly pointed to a full stack of R300 Rebrandeons.As for RMA rates lol yep, 5% is well within expected RMA return rates, so spate is not only overstated, its inaccurate characterization when most 970 users would not notice or not care to return a card that still functions without issue to this day.
And how do you know the gap between them isn't large? We've already seen numerous reports of lower min FPS, massive frame drops/stutters, and hitching on Fury X as it hits its VRAM limit. Its a gap that will only grow in newer games that use more VRAM or in multi-GPU solutions that haven't been tested yet that allow the end-user to crank up settings even higher. How do you know 12GB is or isn't needed if you haven't tested the hardware yourself? While 1xTitan X isn't enough to drive the settings that will exceed 6GB, 2x in SLI certainly is and already I've seen a number of games such as AC: Unity, GTA5, and SoM use more than 6GB at just 1440p. I fully expect "next-gen" games to pressure VRAM even further.
5150Joker - Thursday, July 2, 2015 - link
If you visit the Anandtech forums, there's still a few AMD hardcore fanboys like Silverforce and RussianSensation making up excuses for Fury X and AMD. Those guys live in a fantasy land and honestly, the impact of Fury X's failure wouldn't have been as significant if stupid fanboys like the two I mentioned hadn't hyped Fury X so much.To AMD's credit, they did force NVIDIA to price 980 Ti at $650 and release it earlier, I guess that means something to those that wanted Titan X performance for $350 less. Unfortunately for them, their fanboys are more of a cancer than help.
chizow - Friday, July 3, 2015 - link
Hahah yeah I don't visit the forums much anymore, mods tried getting all heavy-handed in moderation a few years back with some of the mods being the biggest AMD fanboys/trolls around. They also allowed daily random new accounts to accuse people like myself of shilling and when I retaliated, they again threatened action so yeah, simpler this way. :)I've seen some of RS's postings in the article comments sections though, he used to be a lot more even keeled back then but yeah at some point his mindset turned into best bang for the buck (basically devolving into 2-gen old FS/FT prices) trumping anything new without considering the reality, what he advocates just isn't fast enough for those looking for an UPGRADE. I also got a big chuckle out of his claims 7970 is some kind of god card when it was literally the worst price:perfomance increase in the history of GPUs, causing this entire 28nm price escalation to begin with.
But yeah, can't say I remember Silverforce, not surprising though they overhyped Fury X and the benefits of HBM to the moon, there's a handful of those out there and then they wonder why everyone is down on AMD after none of what they hoped/hyped for actually happens.
mapesdhs - Friday, July 3, 2015 - link
I eventually obtained a couple of 7970s to bench; sure it was quick, but I was shocked how loud the cards were (despite having big aftermarket coolers, really no better than the equivalent 3GB 580s), and the CF issues were a nightmare.D. Lister - Thursday, July 2, 2015 - link
@chizowPersonally I think the reason behind the current FX shortages is that Fury X was originally meant to be air-cooled, trouncing 980 by 5-10 % and priced at $650 - but then NV rather sneakily launched the Ti, a much more potent gpu compared to an air-cooled FX, at the same price, screwing up AMD's plan to launch at Computex. So to reach some performance parity at the given price point, AMD had to hurriedly put CLCs on some of the FXs and then OC the heck out of them (that's why the original "overclockers' dream" is now an OC nightmare - no more headroom left) and push their launch to E3.
So I guess once AMD finish respecing their original air-cooled stock, supplies would gradually improve.