The AMD Radeon R9 Fury X Review: Aiming For the Top
by Ryan Smith on July 2, 2015 11:15 AM ESTFiji’s Layout
So what did AMD put in 8.9 billion transistors filling out 596mm2? The answer as it turns out is quite a bit of hardware, though at the same time perhaps not as much (or at least not in the ratios) as everyone was initially hoping for.
The overall logical layout of Fiji is rather close to Hawaii after accounting for the differences in the number of resource blocks and the change in memory. Or perhaps Tonga (R9 285) is the more apt comparison, since that’s AMD’s other GCN 1.2 GPU.
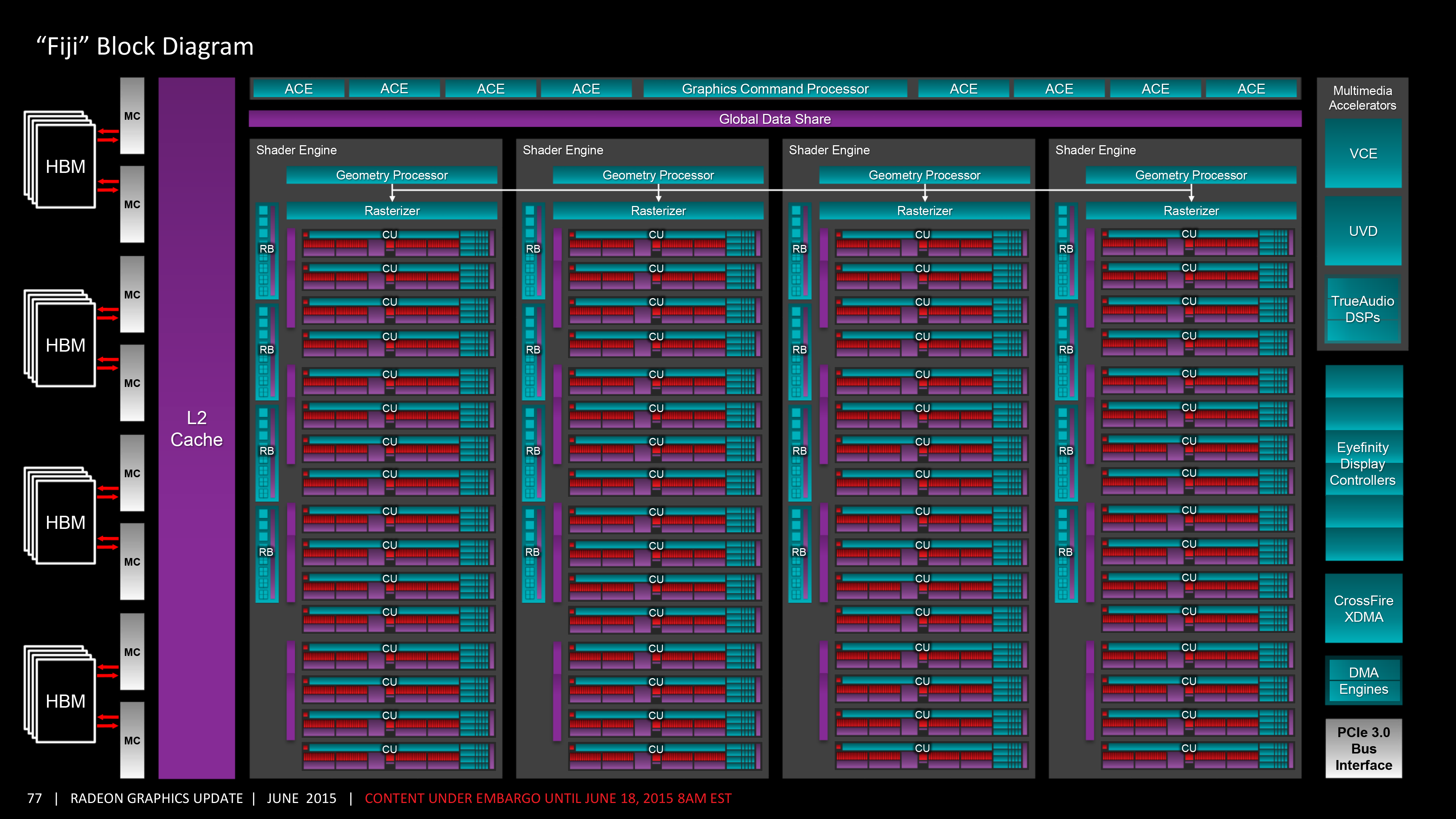
In either case the end result is quite a bit of shading power for Fiji. AMD has bumped up the CU count from 44 to 64, or to put this in terms of the number of ALUs/stream processors, it’s up from 2816 to a nice, round 4096 (2^12). As we discussed earlier FP64 performance has been significantly curtailed in the name of space efficiency, otherwise at Fury X’s stock clockspeed of 1050MHz, you’re looking at enough ALUs to push 8.6 TFLOPs of FP32 operations.
These 64 CUs in turn are laid out in a manner consistent with past GCN designs, with AMD retaining their overall Shader Engine organization. Sub-dividing the GPU into four parts, each shader engine possesses 1 geometry unit, 1 rasterizer unit, 4 render backends (for a total of 16 ROPs), and finally, one-quarter of the CUs, or 16 CUs per shader engine. The CUs in turn continue to be organized in groups of 4, with each group sharing a 16KB L1 scalar cache and 32KB L1 instruction cache. Meanwhile since Fiji’s CU count is once again a multiple of 16, this also does away with Hawaii’s oddball group of 3 CUs at the tail-end of each shader engine.
Looking at the broader picture, what AMD has done relative to Hawaii is to increase the number of CUs per shader engine, but not changing the number of shader engines themselves or the number of other resources available for each shader engine. At the time of the Hawaii launch AMD told us that the GCN 1.1 architecture had a maximum scalability of 4 shader engines, and Fiji’s implementation is consistent with that. While I don’t expect AMD will never go beyond 4 shader engines – there are always changes that can be made to increase scalability – given what we know of GCN 1.1’s limitations, it looks like AMD has not attempted to increase their limits with GCN 1.2. What this means is that Fiji is likely the largest possible implementation of GCN 1.2, with as many resources as the architecture can scale out to without more radical changes under the hood to support more scalability.
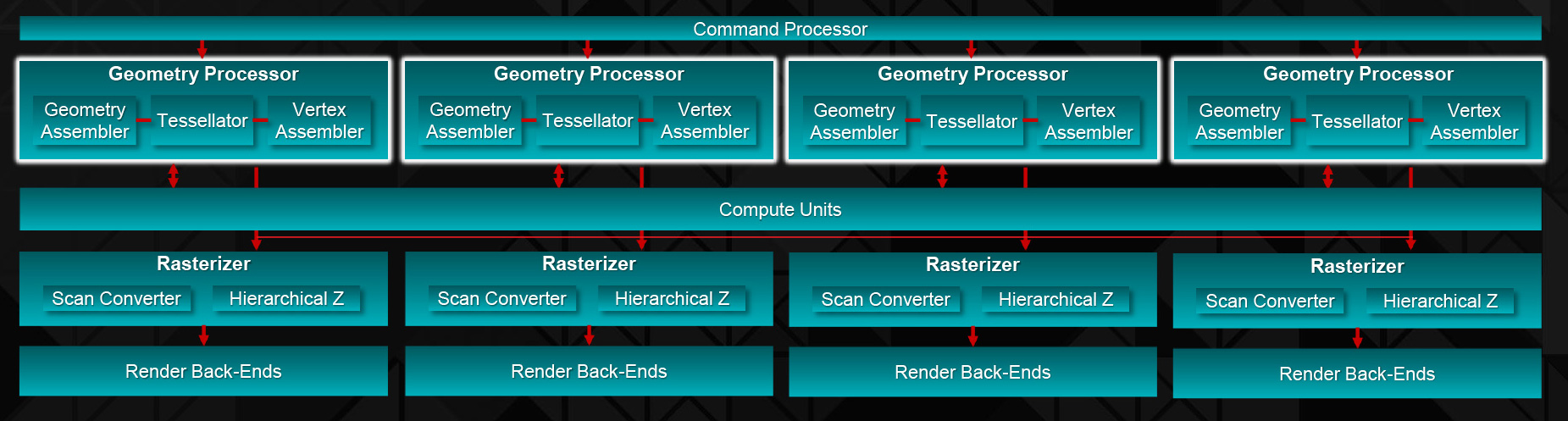
Along those lines, while shading performance is greatly increased over Hawaii, the rest of the front-end is very similar from a raw, theoretical point of view. The geometry processors, which as we mentioned before are organized to 1 per shader engine, just as was the case with Hawaii. With a 1 poly/clock limit here, Fiji has the same theoretical triangle throughput at Hawaii did, with real-world clockspeeds driving things up just a bit over the R9 290X. However as we discussed in our look at the GCN 1.2 architecture, AMD has made some significant under-the-hood changes to the geometry processor design for GCN 1.2/Fiji in order to boost their geometry efficiency, making Fiji’s geometry fornt-end faster and more efficient than Hawaii. As a result the theoretical performance may be unchanged, but in the real world Fiji is going to offer better geometry performance than Hawaii does.
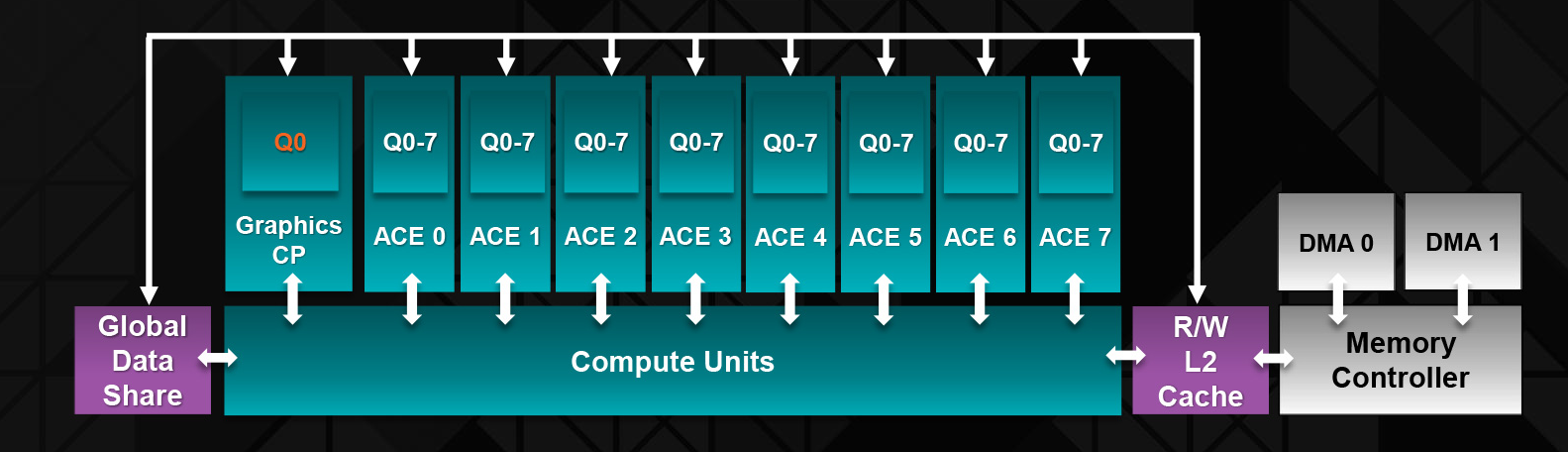
Meanwhile the command processor/ACE structure remains unchanged from Hawaii. We’re still looking at a single graphics command processor paired up with 8 Asynchronous Compute Engines here, and if AMD has made any changes to this beyond what is necessary to support the GCN 1.2 feature set (e.g. context switching, virtualization, and FP16), then they have not disclosed it. AMD is expecting asynchronous shading to be increasingly popular in the coming years, especially in the case of VR, so Fiji’s front-end is well-geared towards the future AMD is planning for.
Moving on, let’s switch gears and talk about the back-end of the processor. There are some significant changes here due to HBM, as to be expected, but there are also some other changes going on as well that are not related to HBM.
Starting with the ROPs, the ROP situation for Fiji remains more or less unchanged from Hawaii. Hawaii shipped with 64 ROPs grouped in to 16 Render Backends (RBs), which at the time AMD told us was the most a 4 shader engine GCN GPU could support. And I suspect that limit is still in play here, leading to Fiji continuing to pack 64 ROPs. Given that AMD just went from 32 to 64 a generation ago, another jump seemed unlikely anyhow (despite earlier rumors to the contrary), but in the end I suspect that AMD had to consider architectural limits just as much as they had to consider performance tradeoffs of more ROPs versus more shaders.
In any case, the real story here isn’t the number of ROPs, but their overall performance. Relative to Hawaii, Fiji’s ROP performance is getting turbocharged for two major reasons. The first is GCN 1.2’s delta color compression, which significantly reduces the amount of memory bandwidth the ROPs consume. Since the ROPs are always memory bandwidth bottlenecked – and this was even more true on Hawaii as the ROP/bandwidth ratio fell relative to Tahiti – anything that reduces memory bandwidth needs can boost performance. We’ve seen this first-hand on R9 285, which with its 256-bit memory bus had no problem keeping up with (and even squeaking past) the 384-bit bus of the R9 280.

The other factor turbocharging Fiji’s ROPs is of course the HBM. In case GCN 1.2’s bandwidth savings were not enough, Fiji also just flat-out has quite a bit more memory bandwidth to play with. The R9 290X and its 5Gbps, 512-bit memory bus offered 320GB/sec, a value that for a GDDR5-based system has only just been overshadowed by the R9 390X. But with Fiji, the HBM configuration as implemented on the R9 Fury X gives AMD 512GB/sec, an increase of 192GB/sec, or 60%.
Now AMD did not just add 60% more memory bandwidth because they felt like it, but because they’re putting that memory bandwidth to good use. The ROPs would still gladly consume it all, and this doesn’t include all of the memory bandwidth consumed by the shaders, the geometry engines, and the other components of the GPU. GPU performance has long outpaced memory bandwidth improvements, and while HBM doesn’t erase any kind of conceptual deficit, it certainly eats into it. With such a significant increase in memory bandwidth and combined with GCN 1.2’s color compression technology, AMD’s effective memory bandwidth to their ROPs has more than doubled from Hawaii to Fiji, which will go a long way towards increasing ROP efficiency and real-world performance. And even if a task doesn’t compress well (e.g. compute) then there’s still 60% more memory bandwidth to work with. Half of a terabyte-per-second of memory bandwidth is simply an incredible amount to have for such a large pool of VRAM, since prior to this only GPU caches operated that quickly.
Speaking of caches, Fiji’s L2 cache has been upgraded as well. With Hawaii AMD shipped a 1MB cache, and now with Fiji that cache has been upgraded again to 2MB. Even with the increase in memory bandwidth, going to VRAM is still a relatively expensive operation, so trying to stay on-cache is beneficial up to a point, which is why AMD spent the additional transistors here to double the L2 cache. Both AMD and NVIDIA have gone with relatively large L2 caches in this latest round, and with their latest generation color compression technologies it makes a lot of sense; since the L2 cache can store color-compressed tiles, all of a sudden L2 caches are a good deal more useful and worth the space they consume.
Finally, we’ll get to HBM in a more detail in a bit, but let’s take a quick look at the HBM controller layout. With Fiji there are 8 HBM memory controllers, and each HBM controller in turn drives one-half of an HBM stack, meaning 2 controllers are necessary to drive a full stack. And while AMD’s logical diagram doesn’t illustrate it, Fiji is almost certainly wired such that each HBM memory controller is tightly coupled with 8 ROPs and 256KB of L2 cache. AMD has not announced any future Fiji products with less than 4GB of VRAM, so we’re not expecting any parts with disabled ROPs, but if they did that would give you an idea of how things would be disabled.








458 Comments
View All Comments
D. Lister - Friday, July 3, 2015 - link
Ryan, to us, the readers, AT is just one of several sources of information, and to us, the result of your review sample is just one of the results of many other review samples. As a journalist, one would expect you to have done at least some investigation regarding the "overclockers' dream" claim, posted your numbers and left the conclusion making to those whose own money is actually going to be spent on this product - us, the customers.I totally understand if you couldn't because of ill health, but, with all due respect, saying that you couldn't review a review sample because there weren't enough review samples to find some scientifically accurate mean performance number, at least to me appears as a reason with less than stellar validity.
silverblue - Friday, July 3, 2015 - link
I can understand some of the criticisms posted here, but let's remember that this is a free site. Additionally, I doubt there were many Fury X samples sent out. KitGuru certainly didn't get one (*titter*). Finally, we've already established that Fury X has practically sold out everywhere, so AT would have needed to purchase a Fury X AFTER release and BEFORE they went out of stock in order to satisfy the questions about sample quality and pump whine.nagi603 - Thursday, July 2, 2015 - link
"if you absolutely must have the lowest load noise possible from a reference card, the R9 Fury X should easily impress you."Or, you know, mod the hell out of your card. I have a 290X in a very quiet room, and can't hear it, thanks to the Accelero Xtreme IV I bolted onto it. It does look monstrously big, but still, not even the Fury X can touch that lack of system noise.
looncraz - Thursday, July 2, 2015 - link
The 5870 was the fastest GPU when it was released and the the 290X was the fastest GPU when it was released. This article makes it sound like AMD has been unable to keep up at all, but they've been trading blows. nVidia simply has had the means to counter effectively.The 290X beat nVidia's $1,000 Titan. nVidia had to quickly respond with a 780Ti which undercut their top dog. nVidia had to release the 780Ti at a seriously low price in order to compete with the, then unreleased, Fury X and had to give the GPU 95% of the performance of their $1,000 Titan X.
nVidia is barely keeping ahead of AMD in performance, but was well ahead in efficiency. AMD just about brought that to parity with THEIR HBM tech, which nVidia will also be using.
Oh, anyone know the last time nVidia actually innovated with their GPUs? GSync doesn't count, that is an ages-old idea they simply had enough clout to see implemented, and PhysX doesn't count, since they simply purchased the company who created it.
tviceman - Thursday, July 2, 2015 - link
The 5870 was the fastest for 7 months, but it wasn't because it beat Nvidia's competition against it. Nvidia's competition against it was many months late, and when it finally came out was clearly faster. The 7970 was the fastest for 10 weeks, then was either slower or traded blows with the GTX 680. The 290x traded blows with Titan but was not clearly faster and was then eclipsed by the 780 TI 5 days later.All in all, since GTX 480 came out in March of 2010, Nvidia has solidly held the single GPU performance crown. Sometimes by a small margin (GTX 680 launch vs. HD 7970), sometimes by a massive margin (GTX Titan vs. 7970Ghz), but besides a 10 week stint, Nvidia has been in the lead for over the past 5 years.
kn00tcn - Thursday, July 2, 2015 - link
check reviews with newer drivers, 7970 has increased more than 680, sometimes similar with 290x vs 780/780ti depending on game (it's a mess to dig up info, some of it is coming from kepler complaints)speaking of drivers, 390x using a different set than 290x in reviews, that sure makes launch reviews pointless...
chizow - Thursday, July 2, 2015 - link
I see AMD fanboys/proponents say this often, so I'll ask you.Is performance at the time you purchase and in the near future more important to you? Or are you buying for unrealized potential that may only be unlocked when you are ready to upgrade those cards again?
But I guess that is a fundamental difference and one of the main reasons I prefer Nvidia. I'd much rather buy something knowing I'm going to get Day 1 drivers, timely updates, feature support as advertised when I buy, over the constant promise and long delays between significant updates and feature gaps.
silverblue - Friday, July 3, 2015 - link
Good point, however NVIDIA has made large gains in drivers in the past, so there is definitely performance left on the table for them as well. I think the issue here is that NVIDIA has seemed - to the casual observer - to be less interested in delivering performance improvements for anything prior to Maxwell, perhaps as a method of pushing people to buy their new products. Of course, this wouldn't cause you any issues considering you're already on Maxwell 2.0, but what about the guy who bought a 680 which hasn't aged so well? Not everybody can afford a new card every generation, let alone two top end cards.chizow - Sunday, July 5, 2015 - link
Again, it fundamentally speaks to Nvidia designing hardware and using their transistor budget to meet the demands of games that will be relevant during the course of that card's useful life.Meanwhile, AMD may focus on archs that provide greater longevity, but really, who cares if it was always running a deficit for most of its useful life just to catch up and take the lead when you're running settings in new games that are borderline unplayable to begin with?
Some examples for GCN vs. Kepler would be AMD's focus on compute, where they always had a lead over Nvidia in games like Dirt that started using Global Illumination, while Kepler focused on geometry and tessellation, which allowed it to beat AMD in most relevant games of the DX9 to DX11 transition era.
Now, Nvidia presses its advantage as its compute has caught up and exceeded GCN with Kepler, while maintaining their advantage with geometry and tesseletion, so we see in these games, GCN and Kepler both fall behind. That's just called progress. The guy who thinks his 680 should still keep pace with a new gen architecture meant to take advantage of features in new gen games probably just needs to look back at history to understand, new gen archs are always going to run new gen games better than older archs.
chizow - Thursday, July 2, 2015 - link
+1, exactly, except for a few momentary anomalies, Nvidia has held the single GPU performance crown and won every generation since G80. They did their best with the small die strategy for as long as they could, but they quickly learned they'd never get there against Nvidia's monster 500+mm^2 chips, so they went big die as well. Fiji was a good effort, but as we can see, it fell short and may be the last grand effort we see from AMD.