The Intel Xeon E5 v4 Review: Testing Broadwell-EP With Demanding Server Workloads
by Johan De Gelas on March 31, 2016 12:30 PM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise
- Enterprise CPUs
- Broadwell
Broadwell-EP: A 10,000 Foot View
What are the building blocks of a 22-core Xeon? The short answer: 24 cores, 2.5 MB L3-cache per core, 2 rings connected by 2 bridges (s-boxes) and several PCIe/QPI/home "agents".
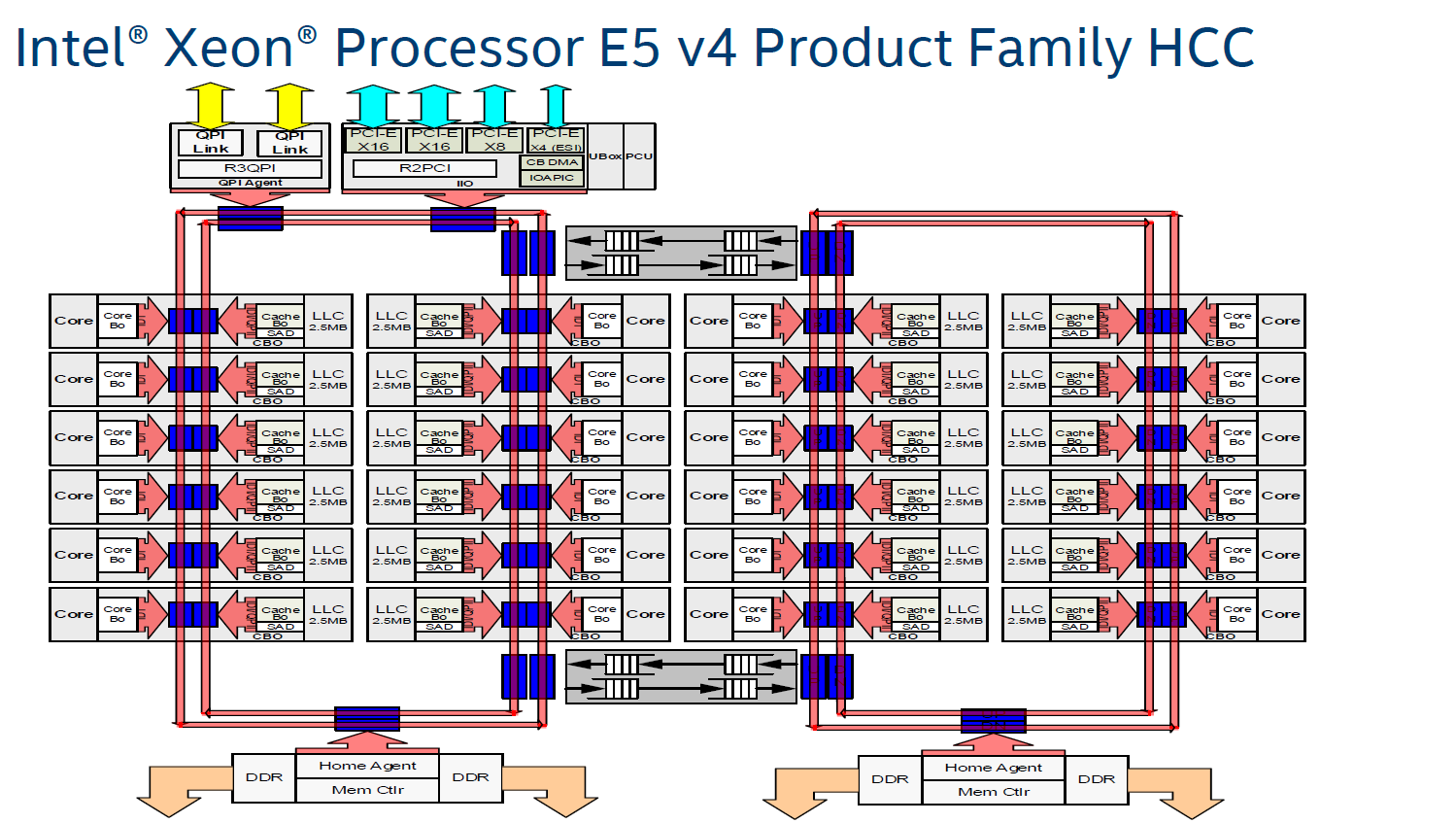
The fact that only 22 of those 24 cores are activated in the top Xeon E5 SKU is purely a product differentiation decision. The 18 core Xeon E5 v3 used exactly the same die as the Xeon E7, and this has not changed in the new "Broadwell" generation.
The largest die (+/- 454 mm²), highest core (HCC) count SKUs still work with a two ring configuration connected by two bridges. The rings move data in opposite directions (clockwise/counter-clockwise) in order to reduce latency by allowing data to take the shortest path to the destination. The blue points indicate where data can jump onto the ring buses. Physical addresses are evenly distributed over the different cache slices (each 2.5 MB) to make sure that L3-cache accesses are also distributed, as a "hotspot" on one L3-cache slice would lower performance significantly. The L3-cache latency is rather variable: if the core is lucky enough to find the data in its own cache slice, only one extra cycle is needed (on top of the normal L1-L2-L3 latency). Getting a cacheline of another slice can cost up to 12 cycles, with an average cost of 6 cycles..
Meanwhile rings and other entities of the uncore work on a separate voltage plane and frequency. Power can be dynamically allocated to these entities, although the uncore parts are limited to 3 GHz.
Just like Haswell-EP, the Broadwell-EP Xeon E5 has three different die configurations. The second configuration supports 12 to 15 cores and is a smaller version (306mm²) of the third die configuration that we described above. These dies still have two memory controllers.
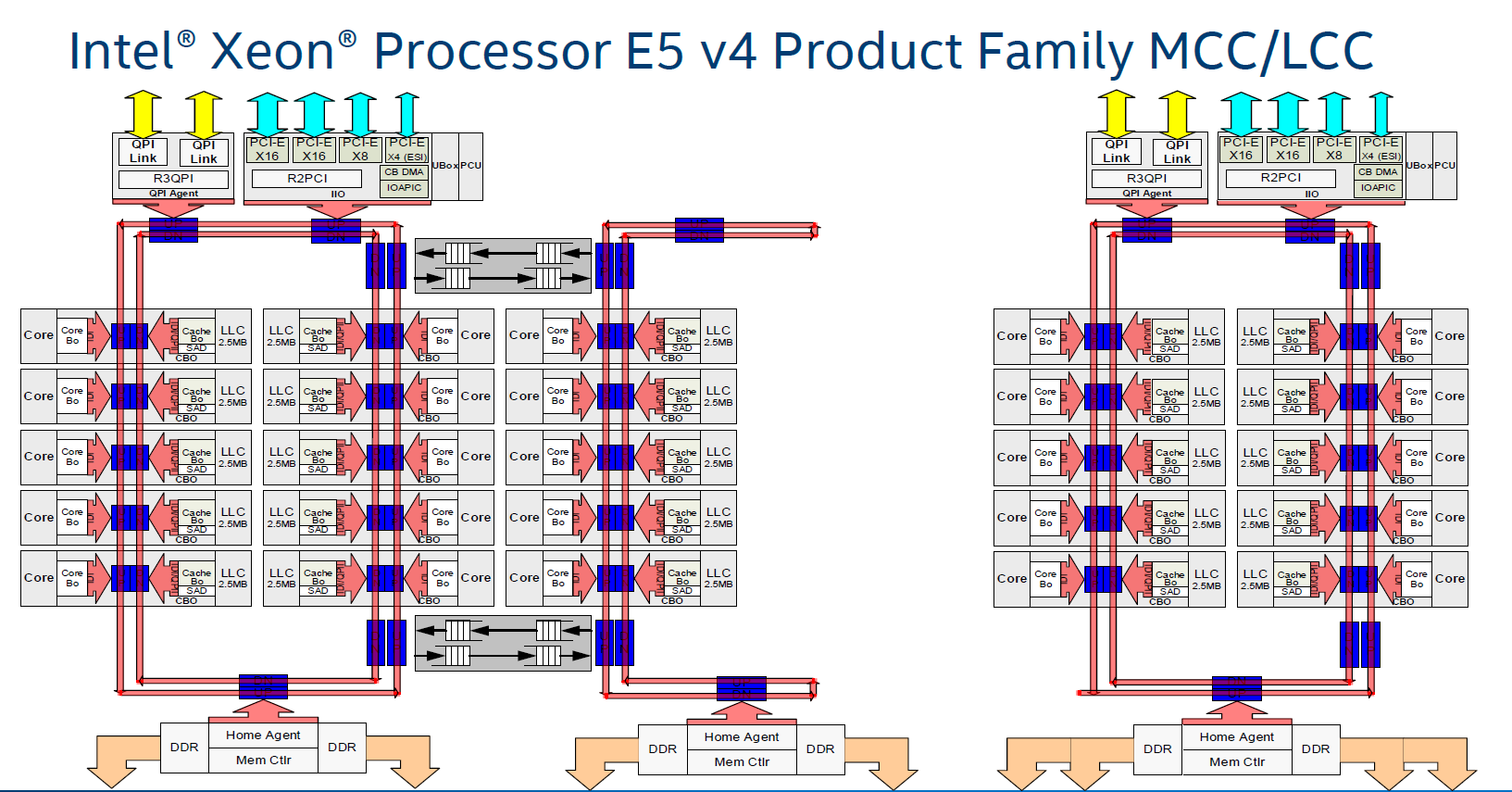
Otherwise the smallest 10 core die uses only one dual ring, two columns of cores, and only one memory controller. However, the memory controller drives 4 channels instead of 2, so there is a very small bandwidth penalty (5-10%) compared to the larger dies (HCC+MCC) with two memory controllers. The smaller die has a smaller L3-cache of course (25 MB max.). As the L3-cache gets smaller, latency is also a bit lower.
Cache Coherency
As the core count goes up, it gets increasingly complex to keep cache coherency. Intel uses the MESIF (Modified, Exclusive, shared, Invalid and Forward) protocol for cache coherency. The Home Agents inside the memory controller and the caching agents inside the L3-cache slice implement the cache coherency. To maintain consistency, a snoop mechanism is necessary. There are now no less than 4 different snoop methods.
The first, Early Snoop, was available starting with Sandy Bridge-EP models. With early snoop, caching agents broadcast snoop requests in the event of an L3-cache miss. Early snoop mode offers low latency, but it generates massive broadcasting traffic. As a result, it is not a good match for high core count dies running bandwidth intensive applications.
The second mode, Home Snoop, was introduced with Ivy Bridge. Cache line requests are no longer broadcasted but forwarded to the home agent in the home node. This adds a bit of latency, but significantly reduces the amount of cache coherency traffic.
Haswell-EP added a third mode, Cluster on Die (CoD). Each home agent has 14 KB directory cache. This directory cache keeps track of the contested cache lines to lower cache-to-cache transfer latencies. In the event of a request, it is checked first, and the directory cache returns a hit, snoops are only sent to indicated (by the directory cache) agents.
On Broadwell-EP, the dice are indeed split along the rings: all cores on one ring are one NUMA node, all other cores on the other ring make the second NUMA node. On Haswell-EP, the split was weirder, with one core of the second ring being a member of the first cluster. On top of that, CoD splits the processor in two NUMA nodes, more or less one node per ring.
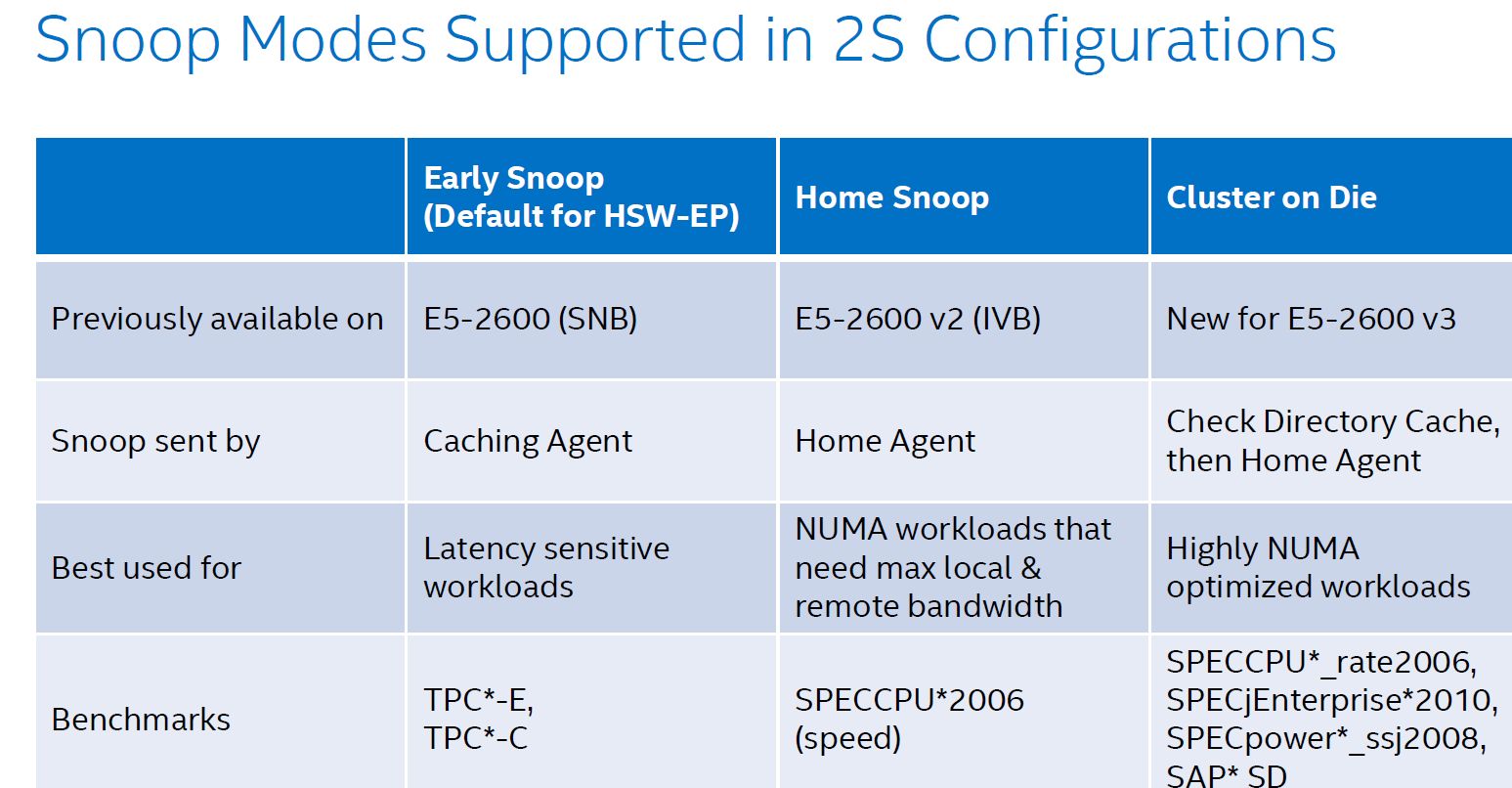
The fourth mode, introduced with Broadwell EP, is the "home snoop" method, but improved with the use of the directory cache and yet another refinement called opportunistic snoop broadcast. This mode already starts snoops to the remote socket early and does the read of the memory directory in parallel instead of waiting for the latter to be done. This is the default snoop method on Broadwell EP.
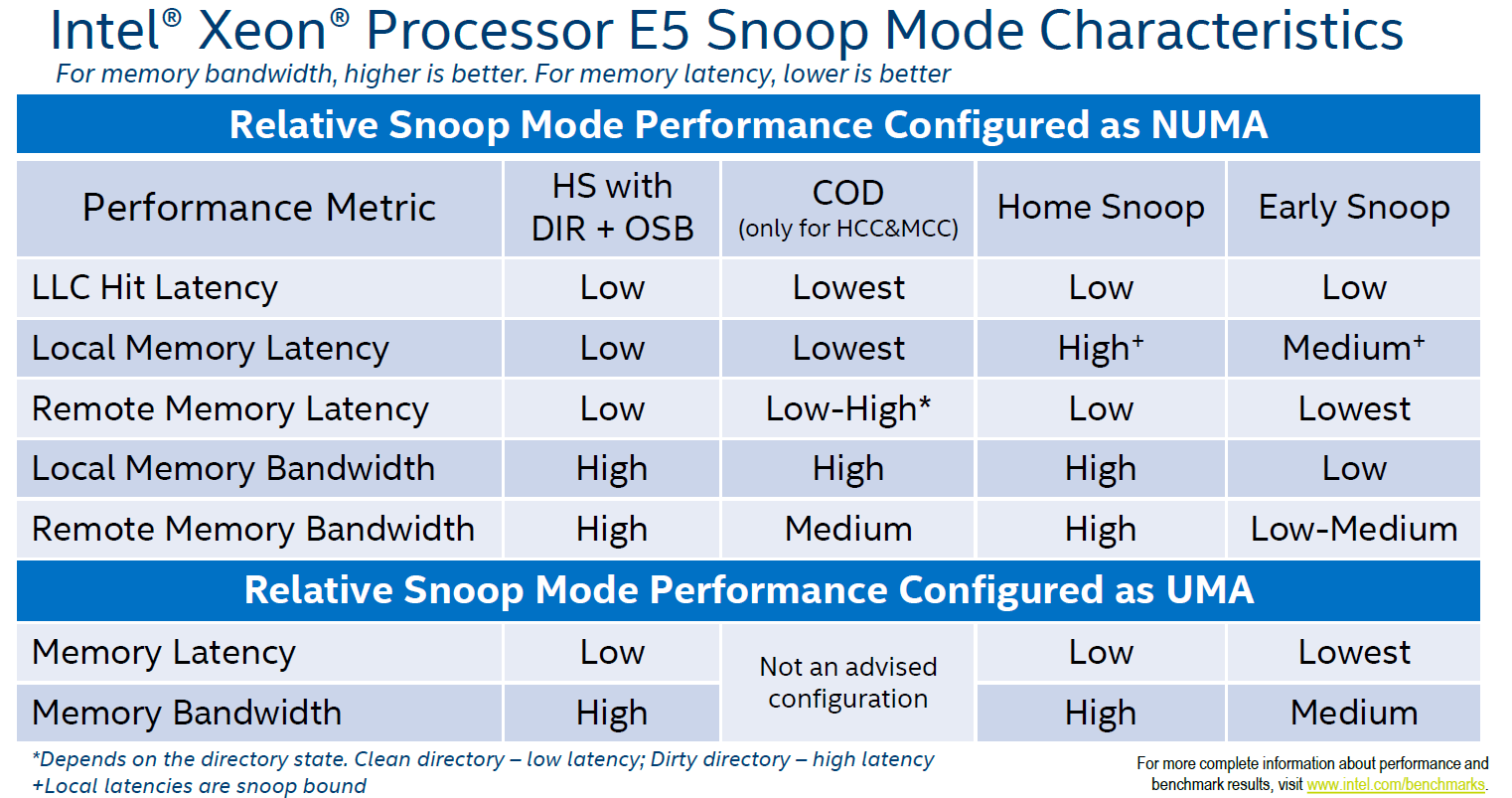
This opportunistic snooping lowers the latency to remote memory.
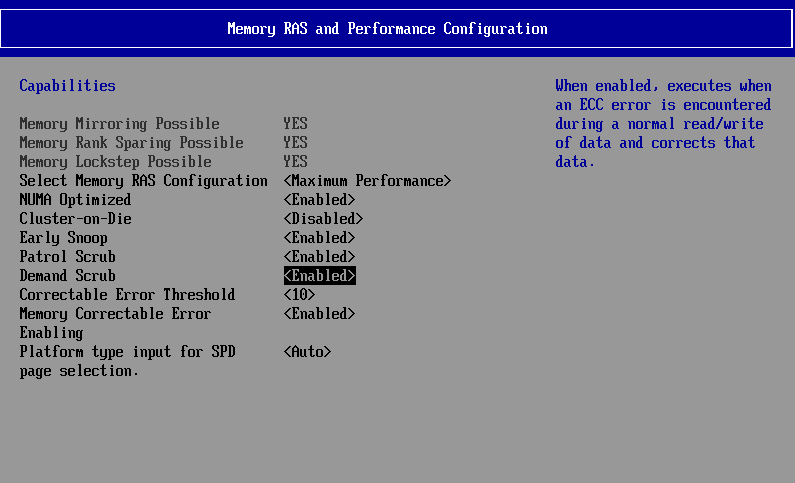
These snoop modes can be set in the BIOS as you can see above.








112 Comments
View All Comments
xrror - Tuesday, April 5, 2016 - link
Even at 3.3Ghz though, they shouldn't be that slow. I'm taking a guess - if this was a student lab, and they bothered to specifically order xeon (or opteron back in the day) workstations - I'm guessing this was a CAD/CAM lab or something running a boatload of expensive licenced software (like, autodesk, solidworks, etc) and some of that stuff is horrible at thrashing on the hard drive, constantly.And I doubt your school could spring the cash for SSD drives in them (because Workstation SKU == you pay dearly OEM workstation 'certified' drive cost).
This is all guesses though. And not trying to defend - it does suck when you have what should be a sweet machine choking for whatever reason, and you're there trying to get your assignments done and you just want to smash the screen cause it just chhhuuuuuuggggsss... ;p
SkipPerk - Friday, April 8, 2016 - link
I have seen this many times, even in the for-profit sector. I once saw a compute cluster that was choking on server with slow storage. They had a 10 gb network and fast Xeon machines running on flash, but the primary storage was too slow. When they get a proper SAN it was an order of magnitude improvement.Back in the day storage was often the bottleneck, but it still comes up today.
someonesomewherelse - Thursday, September 1, 2016 - link
We ran everything in virtual machines with the actual disk images not stored locally.... and the lans in the classrooms were 100mbit, idk about the connection from the classroom to the server with the image. How's that for slow?I would have loved it if our stuff was as 'slow' as yours. The wifi in the classrooms was very fast too..... especially since I doubt anyone bothered with turning of their torrents (well I mean it's completely understandable, you are going to watch the new episode of your favorite show once you are back home and not everyone had (well has, but most people can get it now) fth with at least 100Mbit line (ideally symmetrical, but some isps are too gready with ul speeds so 300/50 is cheaper than 100/100...... and good luck getting 1000/1000 on a residential package (the hw isn't the problem since you can get 1000/1000 with a commercial (aka over priced) package..... using the same hw... basically I would just need to sign a new contract, send it back, and enjoy the faster line in 1 business day or less)...well at least there are no bw caps (if I didn't read foreign boards bw caps on non mobile connections would be something I'd think no isp could do and not lose all customers) and there's we have no dmca (or something similar) and afaik no plans for one either (if they tried to pass such a law I can imagine that you'd have enough support for a referendum which you would win with a huge mayority), even better, the methods used to catch people downloading torrents are illegal anyway so any evidence obtained with them or derived from them is inadmissible anyway and just by presenting it you have admitted to several crimes which the police and prosecution are obliged to investigate/prosecute.... copyright infringment however is a civil matter).
donwilde1 - Tuesday, April 5, 2016 - link
One of the more interesting Intel features, in my opinion, is that Broadwell carries an on-board encryption engine with its own interpreter similar to a small-memory, embedded JVM. This enables full Trusted Boot capability, which I view as a necessity in today's hackable world. Would you consider a follow-on article on this? The project was a clean-room development called BeiHai, done in China.JamesAnthony - Wednesday, April 6, 2016 - link
From what I can tell in looking over the benchmarks, there is not much of an increase in performance at all in core vs core performance speeds going from the V1 CPUs to the V4 CPUsAs if you look at the benchmarks, and calculate that you are comparing 16 cores to 44 cores, the 44 core setup is not 2.75x faster.
So while your overall speed goes up, your work accomplished per core is not increasing at the same rate.
Why does this matter? Well thanks to software licensing costs, as you add cores it gets very expensive quickly. So if your software costs (which can easily exceed the hardware costs very quickly) go up with each core you add, but the work done does not, you quickly wind up in a negative cost / performance ratio.
For quite a few people the E5-2667 v2 CPU with 8 cores at 3.5 GHz (Turbo 4) comes out around the best value for the software licensing cost.
So while Intel puts out processors that overall can do more work than the previous ones, the move to per core software licensing is making it a negative value proposition. This is why people keep wanting higher clock speed lower core count processors, but we seem stuck around 3.5 GHz for many years.
SkipPerk - Friday, April 8, 2016 - link
Although you are right for workstations, so much demand is for generic virtualized machines. Many buyers are fine with 2 ghz with as many cores as they can get. They load as little RAM as the spec requires and throw out the cheapest single core, dual thread 2 GB RAM VM they can. This is how call centers work, not to mention many low-level office jobs. They do not care about performance because this is more than enough.I have had specialty applications where prosumer 6-core or 8-core CPUs were the better deal (usually liquid cooled and overclocked), but not many buyers are licensing insanely expensive analytical software by the core.
SeanJ76 - Sunday, April 10, 2016 - link
@Xeon chips!! TOTAL GARBAGE!legolasyiu - Wednesday, April 20, 2016 - link
The ASUS Workstation/Server board with V4 boards are very stable and they have 10% OC. I am very interested how the processor with those boards.Bulat Ziganshin - Saturday, May 7, 2016 - link
>This increases AES (symmetric) encryption performance by 20-25%PCLMULQDQ implements part of Galois Field multiplication and bdw actually improved only GCM part of AES-GCM algo. neither AES nor other popular symmetric encryption algos became faster
oceanwave1000 - Monday, May 9, 2016 - link
This article mentioned that the Broadwell EP e5-v4 family has 3 die configurations. I got the 306mm2 and 454mm2. Did anyone catch the third one?Thanks.