ISCA 2020: Evolution of the Samsung Exynos CPU Microarchitecture
by Andrei Frumusanu on June 3, 2020 8:00 AM EST
ISCA, the International Symposium for Computer Architecture is an IEEE conference that usually we don’t tend to hear from all that often in the public. The main reason for this is that most sessions and papers tend to be more academically oriented, and thus generally quite a bit further away from the practice of what we see in real products. This year, the conference has changed its format in adding an industry track of sessions, with presentations and papers from various companies in the industry, covering actual commercial products out there in the wild.
Amongst the sessions, Samsung’s SARC (Samsung Austin R&D Centre) CPU development team has presented a paper titled “Evolution of the Samsung Exynos CPU Architecture”, detailing the team’s efforts over its 8-year existence, and presented some key characteristics of its custom Arm CPU cores ranging from the Exynos M1, to the most recent Exynos M5 CPU as well as the unreleased M6 design.
As a bit of background, Samsung’s SARC CPU team was established in 2011 to develop custom CPU cores that Samsung LSI would then deploy in its Exynos SoCs, ranging from the first-generation Exynos 8890 released in 2015 in the Galaxy S7, up till the most recent Exynos 990 with its M5 cores in the Galaxy S20. SARC had completed the M6 microarchitecture before the CPU team had gotten news of it being disbanded in October of 2019, effective last December.
The ISCA paper is a result of Samsung’s willingness to publish some of the development team’s ideas that were considered worthy of preserving in the public, essentially representing a high-level burn-through of 8 years of development.
From M1 to M6: A continuously morphing CPU µarch
The paper presents a gross overview table of the microarchitectural differences between Samsung’s custom CPU cores:
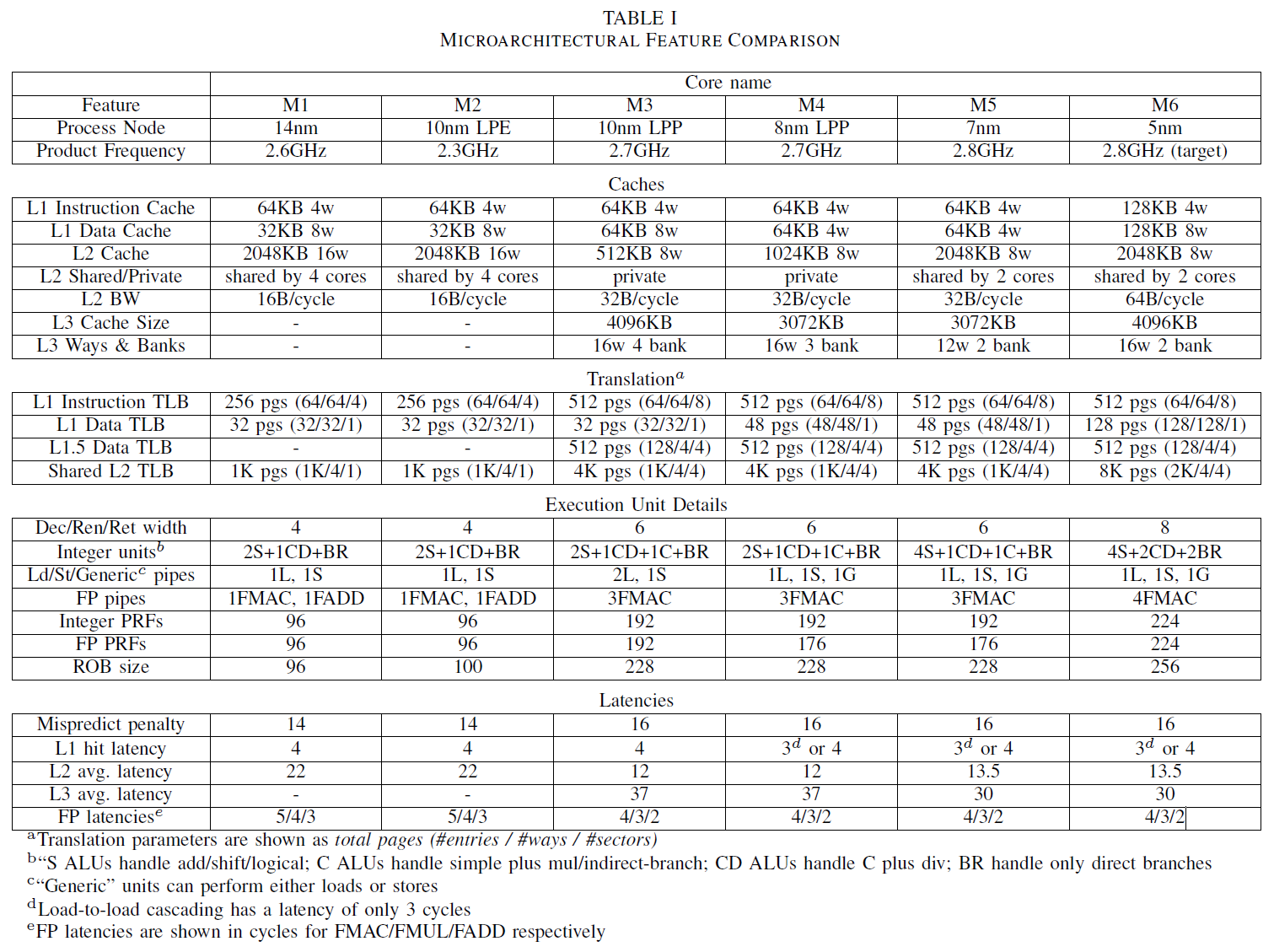
The disclosure covers some of the well-known characteristics of the design as had been disclosed by Samsung in its initial M1 CPU microarchitecture deep dive at HotChips 2016, to the more recent M3 deep dive at HotChips 2018. It gives us an insight into the new M4 and M5 microarchitectures that we had measured in our S10 and S20 reviews, as well as a glimpse of what the M6 would have been.
The one key characteristic of Samsung’s design was over the years, it was based off the same blueprint RTL that was started off with the M1 core in 2011, with continuous improvements of the functional blocks of the cores over the years. The M3 had been a big change in the design, widening the core substantially in several aspects, such as going from a 4-wide design to a 6-wide mid-core.
The new disclosures that weren’t public before regard the new M5 and M6 cores. For the M5, Samsung had made bigger changes to the cache hierarchy of the cores, such as replacing private L2 caches with a new bigger shared cache, as well as disclosing a change in the L3 structure from a 3-bank design to a 2-bank design with less latency.
The unreleased M6 core that had been in development was seemingly to be a bigger jump in terms of the microarchitecture. The SARC team here had prepared large improvements, such as doubling the L1 instruction and data caches from 64KB to 128KB – a design choice that’s currently only been implemented before by Apple’s CPU cores starting with the A12.
The L2 is said to have been doubled in its bandwidth capabilities to up to 64B/cycle, and also there would have been an increase in the L3 from 3 to 4MB.
The M6 would have been an 8-wide decode core, which as far as we know would have been the widest commercial microarchitecture that we know of – at least on the decode side of things.
Interestingly, even though the core would have been much wider, the integer execution units wouldn’t have changed all that much, just seeing one complex pipeline adding a second integer division capability, whilst the load/store pipelines would have remained the same as on the M5 with 1 load unit, 1 store unit, and one 1 load/store unit.
On the floating-point/SIMD pipelines we would have seen an additional fourth unit with FMAC capabilities.
The TLBs would have seen some large changes, such as the L1 DTLB being increased from 48 pages to 128 pages, and the main TLB doubling from 4K pages to 8K pages (32MB coverage).
The M6 would also have ben the first time since the M3 that the out-of-order window of the core would have been increased, with larger integer and floating-point physical register files, and an increase in the ROB (Reorder buffer) from 228 to 256.
One key weakness of the SARC cores seems to still have been present in the M5 and upcoming M6 core, and that’s its deeper pipelines stages resulting in a relatively expensive 16-cycle mispredict penalty, quite higher than Arm’s more recent designs which fall in at 11 cycles.
The paper goes into more depth into the branch predictor design, showcasing the core’s Scaled Hashed Perceptron based design. The design had been improved continuously over the years and implementations, improving the branch accuracy and thus reducing the MPKI (mis-predicts per kilo-instructions) continuously.
An interesting table that’s showcased is the amount of storage structures that the branch predictor takes up within the front-end, in KBytes:
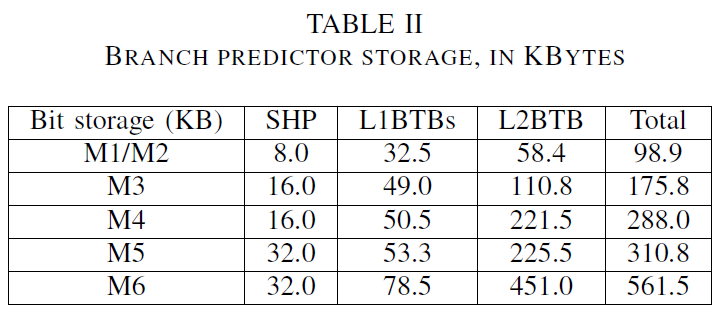
We’re not aware of any other vendor ever having disclosed such figures, so it’s interesting to put things into context of what a modern front-end has to house in terms of storage (and this is *just* the branch predictor).
The paper goes onto further detail onto the cores prefetching methodologies, covering the introduction of a µOP cache in the M5 generation, as well as the team’s efforts into hardening the core against security vulnerabilities such as Spectre.
Generational IPC Improvements - 20% per year - 2.71x in 6 years
The paper further describes efforts by the SARC team to improve memory latency over the generations. In the M4 core, the team had included a load-load cascade mechanism that reduced the effective L1 cycle latency from 4 cycles to 3 on subsequent loads. The M4 had also introduced a path bypass with a new interface from the CPU cores directly to the memory controllers, avoiding traffic through the interconnect, which explains some of the bigger latency improvements that we’ve seen in the Exynos 9820. The M5 had introduced speculative cache lookup bypasses, issuing a request to both the interconnect and the cache tags simultaneously, possibly saving on latency in case of a cache miss as the memory request is already underway. The average load latency had been continuously improved over the generations, from 14.9 cycles on the M1 down to 8.3 cycles on the M6.

In terms of IPC improvements, the SARC team had managed to get to an average of 20% annual improvements over the 8 years of development. The M3 had been in particular a big jump in IPC as seen in the graph. The M5 roughly correlates to what we’ve seen in our benchmarks, at around 15-17% improvement. IPC for the M6 is disclosed at having ended up at an average of 2.71 versus 1.06 for the M1, and the graph here generally seems to indicate a 20% improvement over the M5.
During the Q&A of the session, the paper’s presenter, Brian Grayson, had answered questions about the program’s cancellation. He had disclosed that the team had always been on-target and on-schedule with performance and efficiency improvements with each generation. It was stated that the team’s biggest difficulty was in terms of being extremely careful with future design changes, as the team never had the resources to completely start from scratch or completely rewrite a block. It was said that with hindsight, the team would have done different choices in the past with of some of the design directions. This serial design methodology comes in contrast to Arm’s position, having multiple leapfrogging design centres and CPU teams, allowing them to do things such as ground-up re-designs, such the Cortex-A76.
The team had plenty of ideas for improvements for upcoming cores such as the M7, but the decision to cancel the program was said to have come from very high up at Samsung. The SARC CPU cores were never really that competitive, suffering from diminished power efficiency, performance, and area usage compared to Arm’s designs. With Arm’s latest Cortex-X1 divulged last week going for all-out performance, it looks to me that SARC’s M6 design would have had issues competing against it.
The paper's authors are extremely thankful for Samsung’s graciousness in allowing the publication of the piece, and thank the SARC leadership for their management over the years on this “moonshot” CPU project. SARC currently still designs custom interconnects, memory controllers, as well as working on custom GPU architectures.
Related Reading:
- Arm's New Cortex-A78 and Cortex-X1 Microarchitectures: An Efficiency and Performance Divergence
- The Samsung Galaxy S20+, S20 Ultra Exynos & Snapdragon Review: Megalomania Devices
- The Samsung Galaxy S10+ Snapdragon & Exynos Review: Almost Perfect, Yet So Flawed
- Hot Chips 2018: Samsung’s Exynos-M3 CPU Architecture Deep Dive
- Hot Chips 2016: Exynos M1 Architecture Disclosed
Source: ISCA 2020: Evolution of the Samsung Exynos CPU Microarchitecture








51 Comments
View All Comments
brucethemoose - Wednesday, June 3, 2020 - link
*bitten the bulletlmcd - Thursday, June 4, 2020 - link
It's worse than that, at least one year the revision of Mongoose core didn't align with the cores it was paired with. A few bugs arose due to inconsistent processing of instructions depending on which core a certain instruction ran on.FunBunny2 - Wednesday, June 3, 2020 - link
in due time, with any maths problem, there ends up being only one perfect solution. which is why all this hard ons with ever larger transistor budgets ends up, mostly, in various caches, not compute. has there been any fundamental change in ALU structure in decades?eastcoast_pete - Wednesday, June 3, 2020 - link
Question: how does the pipeline depth and prediction mistakes of the Mongoose cores compare with that of Apple's big cores? I'm asking as my impression of SARC's M designs was/is that they tried to repeat Apple's success in designing highly performant ARM design-based larger cores.anonomouse - Wednesday, June 3, 2020 - link
What's fascinating is how big M5's predictors and BTB's are when comparing to their direct competition. Cortex A77 cites a 8K entry BTB, 64-entry L1BTB, with undisclosed direction and indirect target predictor sizes, and yet M5 does worse on all of the branch heavy and large footprint workloads in SPEC (astar, bzip2, gcc, gobmk, sjeng) as well as all of the javascript benchmarks as well. I don't think Arm has said how any Kbits/Kbytes of storage are actually in their branch prediction structures, but at least in Neoverse N1 or Cortex-A76 the ICache SRAM blocks were clearly much larger in total area than all of the other SRAM in the front-end area of the core, which implies a total size not anywhere near 310KB like M5.Santoval - Thursday, June 4, 2020 - link
"The M6 would have been an 8-wide decode core, which as far as we know would have been the widest commercial microarchitecture that we know of – at least on the decode side of things."Nvidia's Carmel core (the core of their Xavier SoC) is 10-wide. However that's at the dispatch / retire stage and I'm not 100% certain if Carmel's decode width is also 10-wide (unless their dispatch block is not right after decode, which I doubt, it certainly should). Wikichip does not fully clarify but mentions that Carmel is "10-wide" and has a "wider dispatch (10, up from the 7 of Denver 2)" :
https://en.wikichip.org/wiki/nvidia/microarchitect...
Santoval - Thursday, June 4, 2020 - link
p.s. I am not sure if by the word "commercial" you have excluded SoCs for cars or not. If you mean retail / e-tail then someone who doesn't own or work for a car company probably cannot buy an Nvidia board with Xavier. It should be sold strictly B2B. Or not?mode_13h - Friday, June 5, 2020 - link
A Xavier NX kit can be yours for just $399:https://www.anandtech.com/show/15799/nvidia-announ...
Klais - Friday, November 6, 2020 - link
In the field of IT now there are many optimal business solutions, as well as software is constantly being created. Now it is not difficult to implement them, if you have a special team of developers with a professional approach and creative thinking. For example, I know that now there is a great team from Ukraine, which creates individual solutions of high quality that actually make the work process more pleasant and effective. I do <a href="https://hireukrainiandevelopers.com/hire-own-dedic... development team</a> that were able to quickly integrate these solutions into our work and make it much easier. And they did it for little money. I hope that it will be useful for many others, too, who want to optimize their business as much as possible.Klais - Friday, November 6, 2020 - link
In the field of IT now there are many optimal business solutions, as well as software is constantly being created. Now it is not difficult to implement them, if you have a special team of developers with a professional approach and creative thinking. For example, I know that now there is a great team from Ukraine, which creates individual solutions of high quality that actually make the work process more pleasant and effective. I do https://hireukrainiandevelopers.com/hire-own-dedic...">hire development team that were able to quickly integrate these solutions into our work and make it much easier. And they did it for little money. I hope that it will be useful for many others, too, who want to optimize their business as much as possible.