Arm Announces Neoverse V3 and N3 CPU Cores: Building Bigger and Moving Faster with CSS
by Ryan Smith on February 21, 2024 11:00 AM EST- Posted in
- SoCs
- Servers
- ARMv9
- Neoverse E2
- Neoverse V3
- Neoverse N3
- CMN-S3
A bit over 5 years ago, Arm announced their Neoverse initiative for server, cloud, and infrastructure CPU cores. Doubling-down on their efforts to break into the infrastructure CPU market in a big way, the company set about an ambitious multi-year plan to develop what would become a trio of CPU core lineups to address different segments of the market – ranging from the powerful V series to the petite E series core. And while things have gone a little differently than Arm initially projected, they’re hardly in a position to complain, as the Neoverse line of CPU cores has never been as successful as it is now. Custom CPU designs based on Neoverse cores are all the rage with cloud providers, and the broader infrastructure market has seen its own surge.
Now, as the company and its customers turn towards 2024 and a compute market that is in the throes of another transformative change due to insatiable demand for AI hardware, Arm is preparing to release its next generation of Neoverse CPU core designs to its customers. And in the process, the company is reaching the culmination of the original Neoverse roadmap.
This morning the company is taking the wraps off of the V3 CPU architecture (codename Poseidon) for high-performance systems, as well as the N3 CPU architecture (codename Hermes) for balanced systems. These designs are now ready for customers to begin integrating into their own chip designs, with both the individual CPU core designs as well as the larger Compute Subsystems (CSS) available. Between the various combinations of IP configurations, Arm is looking to offer something for everyone, and especially chip designers who are looking to integrate ready-made IP for a quick turnaround in developing their own chips.
With that said, it should be noted that today’s announcement is also a lighter one than what we’ve come to expect from previous Neoverse announcements. Arm isn’t releasing any of the deep architectural details on the new Neoverse platforms today, so while we have the high-level details on the hardware and some basic performance estimates, the underlying details on the CPU cores and their related plumbing is something Arm is keeping to themselves until a later time.
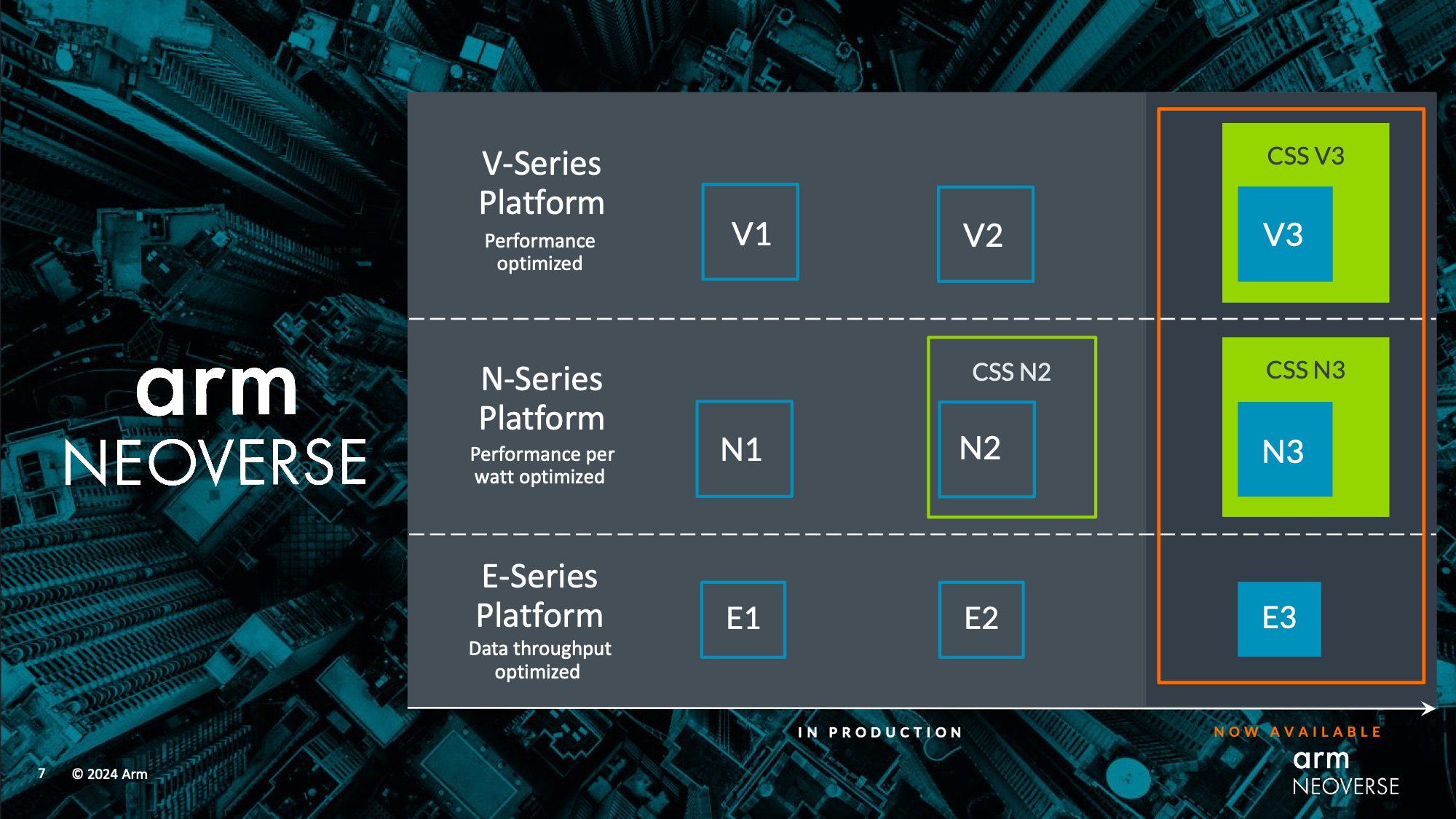
Neoverse V3: Up To 128 Cores, with CXL 3.0 and HBM3, Plus a CSS Design
Starting things off with the high-end architecture of the Neoverse platform, the V3 CPU core. Previously listed in Arm’s roadmaps as “V-Next” and under its codename of Poseidon, the Neoverse V3 is the final architecture design in Arm’s original Neoverse roadmap, with Arm set to finally deliver on what they envisioned so long ago.
Neoverse V cores are traditionally derived from Cortex-X designs, and while Arm isn’t disclosing that level of detail today, there’s no reason to believe that’s changed. I suspect we’re looking at a CPU core design that borrows heavily from Cortex-X5 – Arm’s next-generation Cortex-X design – in keeping in line with the use of X1 and X3 for V1 and V2 respectively. But that is certainly a presumption on my part.
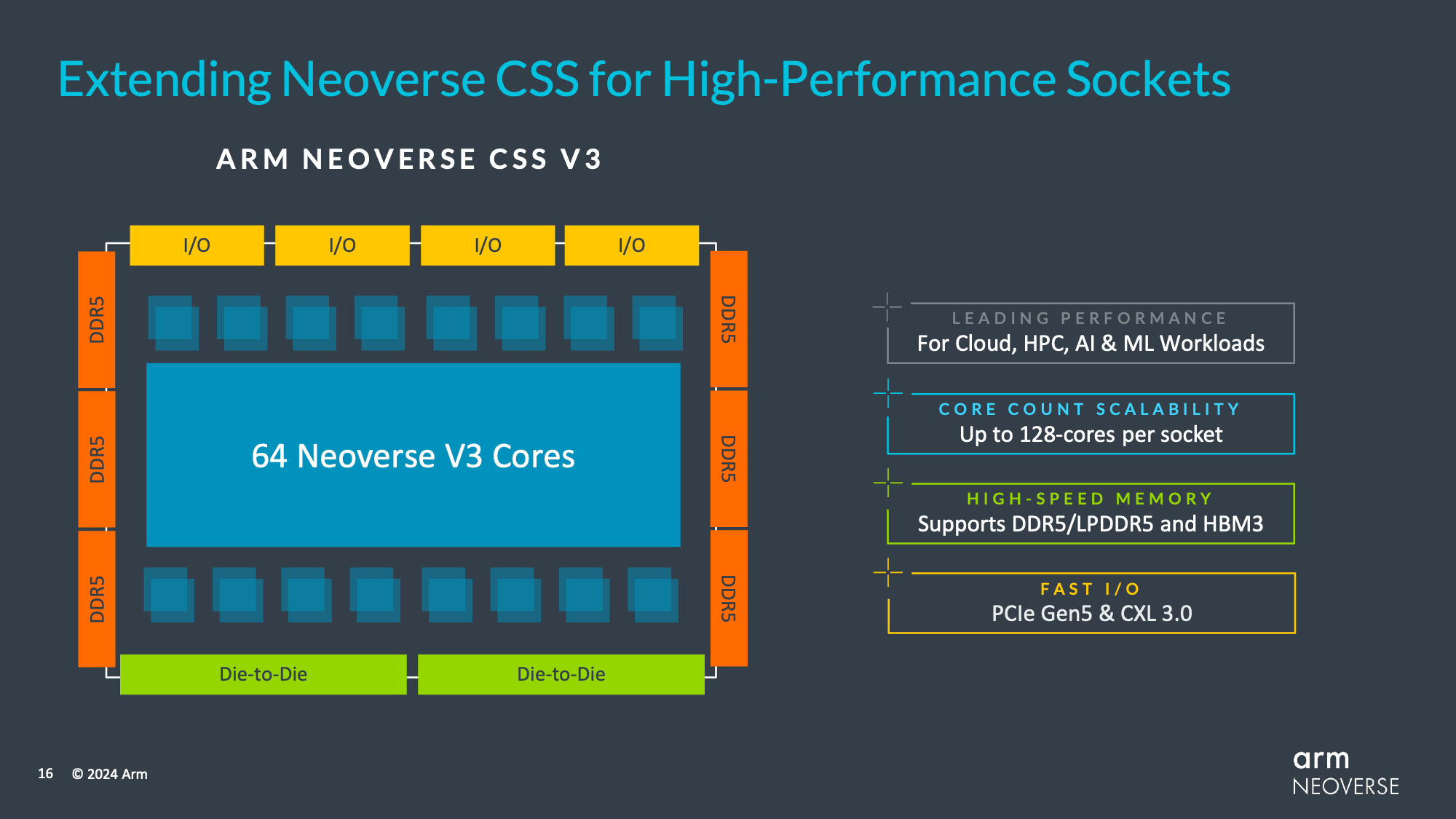
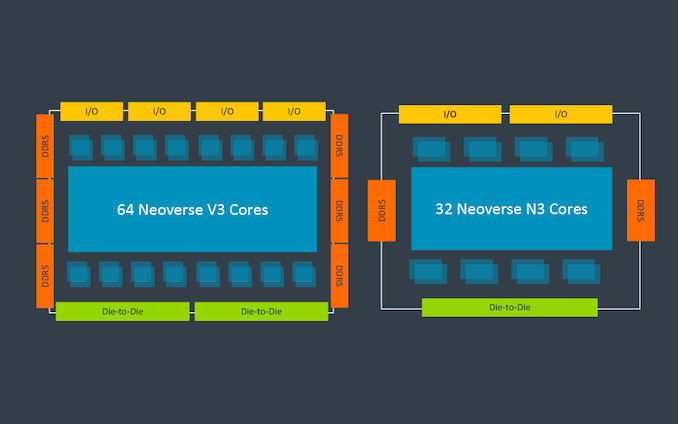
Regardless, like the previous V series CPU cores, the V3 is aimed at the highest-performance applications, delivering the highest single-threaded performance of any Arm Neoverse CPU core. And with up to 64 cores on a single die – and two dies/128 cores on a single socket – V3 is intended to compete at the high-end just like V2 did before it.
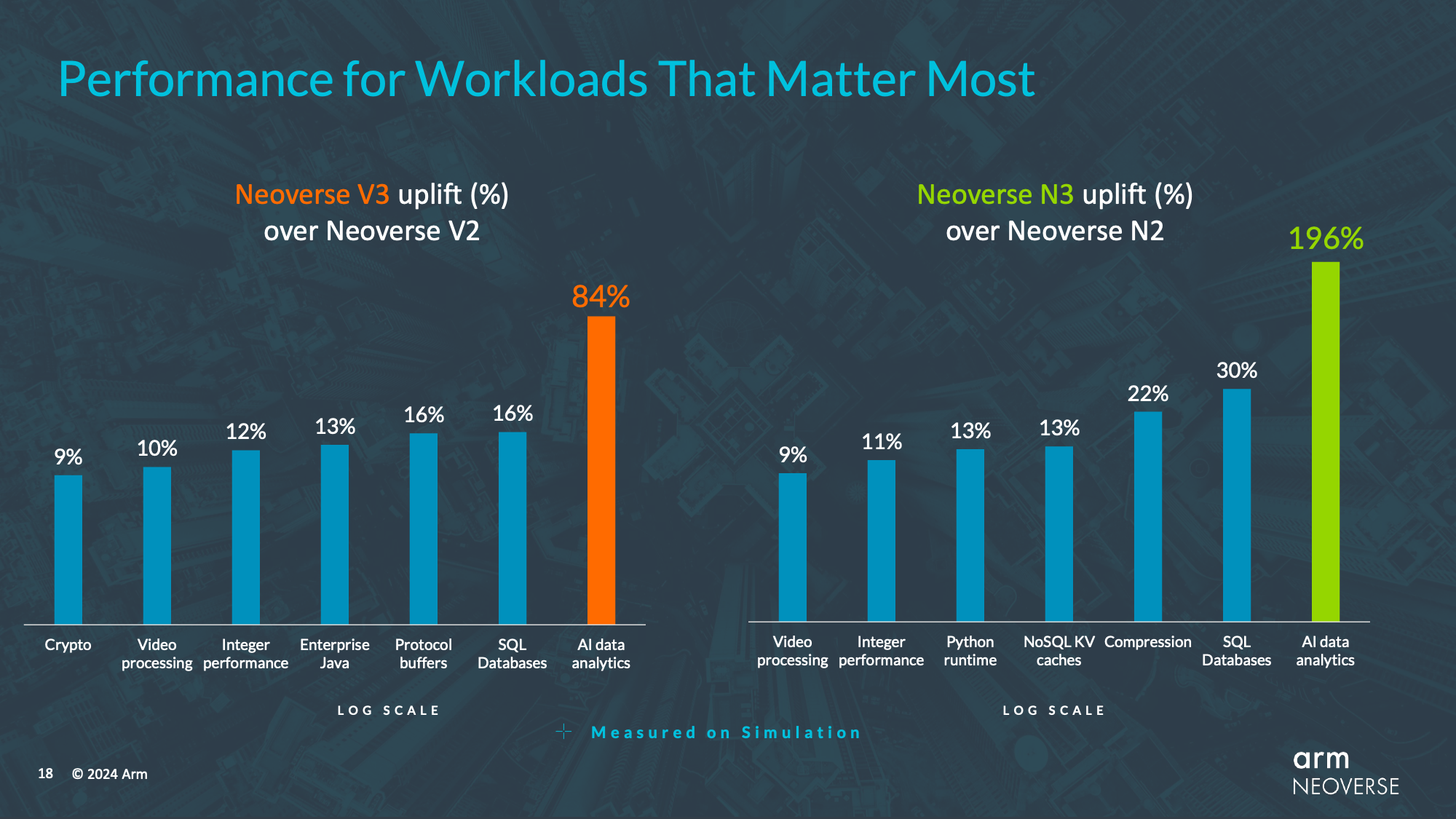
Arm has not provided a generalized performance estimate for the CPU core, but in simulations they’re seeing anywhere between 10% and 20% for most workloads, save the edge-case of AI data analytics (emphasis on the “analytics” and not the “AI”). Going back to Arm’s earliest roadmaps, this is lower than the 30% gen-on-gen improvements they were initially shooting for, but then again the V2 wasn’t even on those roadmaps at the time, so Arm’s steps have become smaller and a bit more frequent.
Again, we don’t have any deep-dive architectural details here, but we do have a few high-level details of the changes that come with V3. Arm has focused a good deal of their efforts on the mesh fabric at multiple points, for example. V3 itself has an improved how it connects to Arm’s mesh fabric in order to relieve pressure there. And the mesh fabric itself is new, replacing Arm’s tried-and-true CMN-700 with the new CMN-S3 – though we don’t have any further details on what the latter entails.
Otherwise, V3 and its CSS counterpart will come with support for all the latest I/O and memory formats. With I/O, CXL support has been bumped up from CXL 2.0 to CXL 3.0 – still sitting on top of PCIe 5.0. Meanwhile on the memory front, LPDDR5, DDR5, and HBM3 are all supported with Arm’s IP.
And for the first time for a V-series CPU core, Arm is offering an off-the-shelf CSS version of this IP for rapid integration into customer chip designs. Though the CSS initiative itself is still fairly new, Arm says that the strategy has proven very successful, with hungry, well-funded cloud service providers like Microsoft (Cobalt 100) rapidly adopting it in order to quickly get their own chip designs put together and hardware put into service. So Arm is looking to bring the same level of simplicity to high-performance customers, especially those who just need a proven CPU IP block to pair up with their custom accelerator designs – with Arm even providing a ready set of die-to-die connections to further streamline the process.
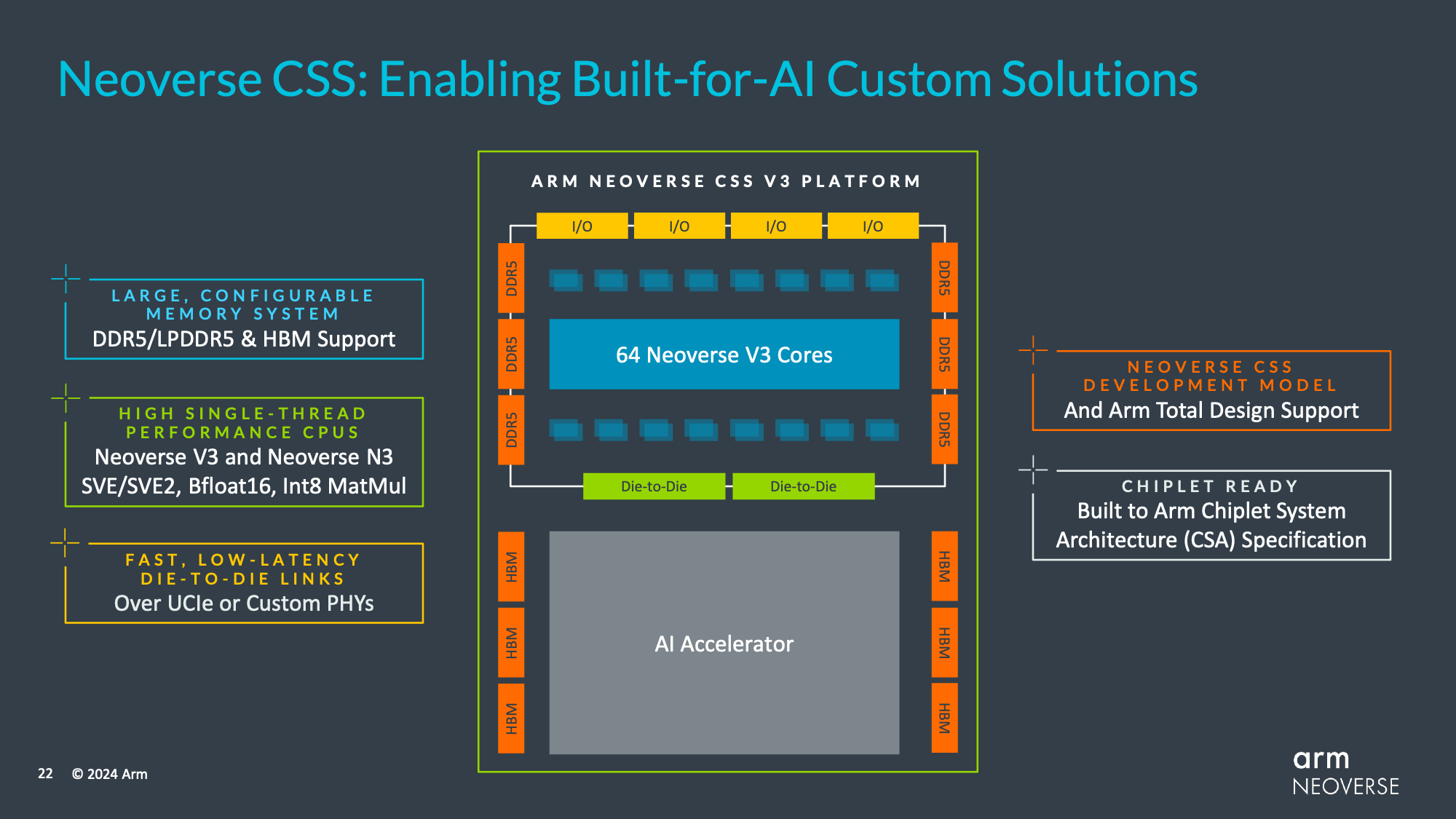
And while this was technically announced earlier this month, the V3 CSS design goes hand-in-hand with Arm’s efforts to establish their own chiplet ecosystem, the Arm Chiplet System Architecture (CSA). The CSA initiative is intended to allow customers to more easily mix and match chiplets in their products, with CSA going above and beyond just protocol compatibility and addressing things such as system management, DMA, security, and software compatibility.

Finally, underscoring the quick turnaround times that Arm is envisioning with the V3 CSS IP, the company is already announcing a design win with Socionext, who is designing a 32 core V3 CSS chiplet to be fabbed at TSMC.
Arm Neoverse N3: 20% Better Perf-Per-Watt, For Up to 32 Cores
The other half of today’s Neoverse IP announcement is Neoverse N3 (codename Hermes), the latest in Arm’s line of balanced, power-efficient CPU cores for a wide variety of markets.

With an even greater focus on their CSS IP this time around, the N3 CSS design supports a range of CPU cores, from 8 up to 32. In the case of the latter, Arm says that their design can operate as low as 40W TDP, or a bit over 1 Watt per CPU core – though the company isn’t disclosing on what process node this is.
Altogether, Arm is touting an average 20% performance-per-watt improvement for the N3 CSS over the N2 CSS. The overall performance improvements typically range between 10% and 30% depending on the specific workload.
Like V3, Arm isn’t offering much in the way of architectural details here. But with N-series designs historically sharing a good deal of design elements with the Cortex-A7xx series, I won’t be surprised to eventually find out it’s the same for the N3.
Meanwhile, Arm is providing a brief glimpse under the hood of N3 CSS to explain their big performance jump in AI data analytics, which is based around the XGBoost library.
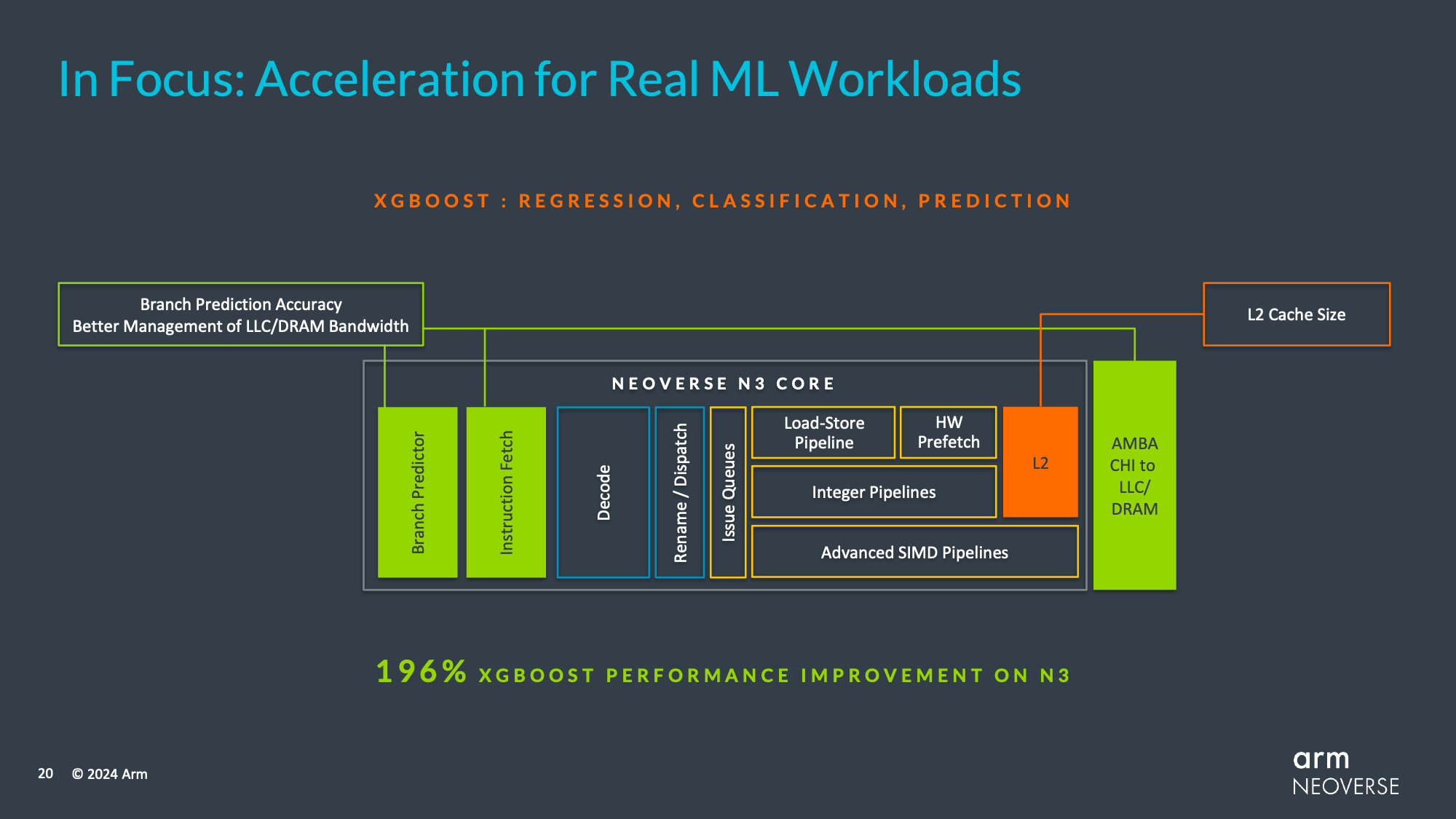
To start with, the L2 cache size for N3 CSS is now 2MB per core, up from 1MB for N2. In fact, Arm has also spent a fair bit of effort on their overall cache and memory subsystem, including making some undisclosed tweaks to their coherent host interface to better manage traffic and memory bandwidth between the CPU cores and last-level cache (and beyond). Though it is unclear of N3 is also using Arm’s new CMN-S3 mesh, or if that is limited to the V3. Meanwhile, on the front-end of the N3, the CPU core features an even more accurate branch prediction unit.
Altogether, these improvements and more are netting Arm a 196% improvement in XGBoost performance, and similarly the 84% performance improvement the V3 CPU core sees in the same workload. This makes data analytics/XGBoost an extreme outlier overall, but it does go to show where Arm has put some of their efforts with this upcoming generation of CPU architectures.
Outside of those core improvements, N3 also features many of the I/O and memory improvements that V3 also gets. Arm hasn’t provided an itemized list, but we’re told that it supports the latest PCIe and CXL standards – this presumably being PCIe 5.0 and CXL 3.0, respectively. Notably, Arm’s previous roadmap had this generation of hardware pegged to support PCIe 6.0, but with that not making it into the V3, it looks like Arm had to take a step back there.
Finally, like the V3 CSS, the N3 CSS also features a die-to-die interconnect. Though as with most other aspects of the N-series hardware, this has been scaled down to a single interconnect. So chip vendors can opt for integrating N3 directly into their die designs, or hooking it up to an external accelerator chiplet.
A Look Towards The Future: Adonis, Dionysus, and Lycius
Finally, as Arm has reached the end of their current Neoverse roadmap, the company is providing a roadmap for future CPU core releases.
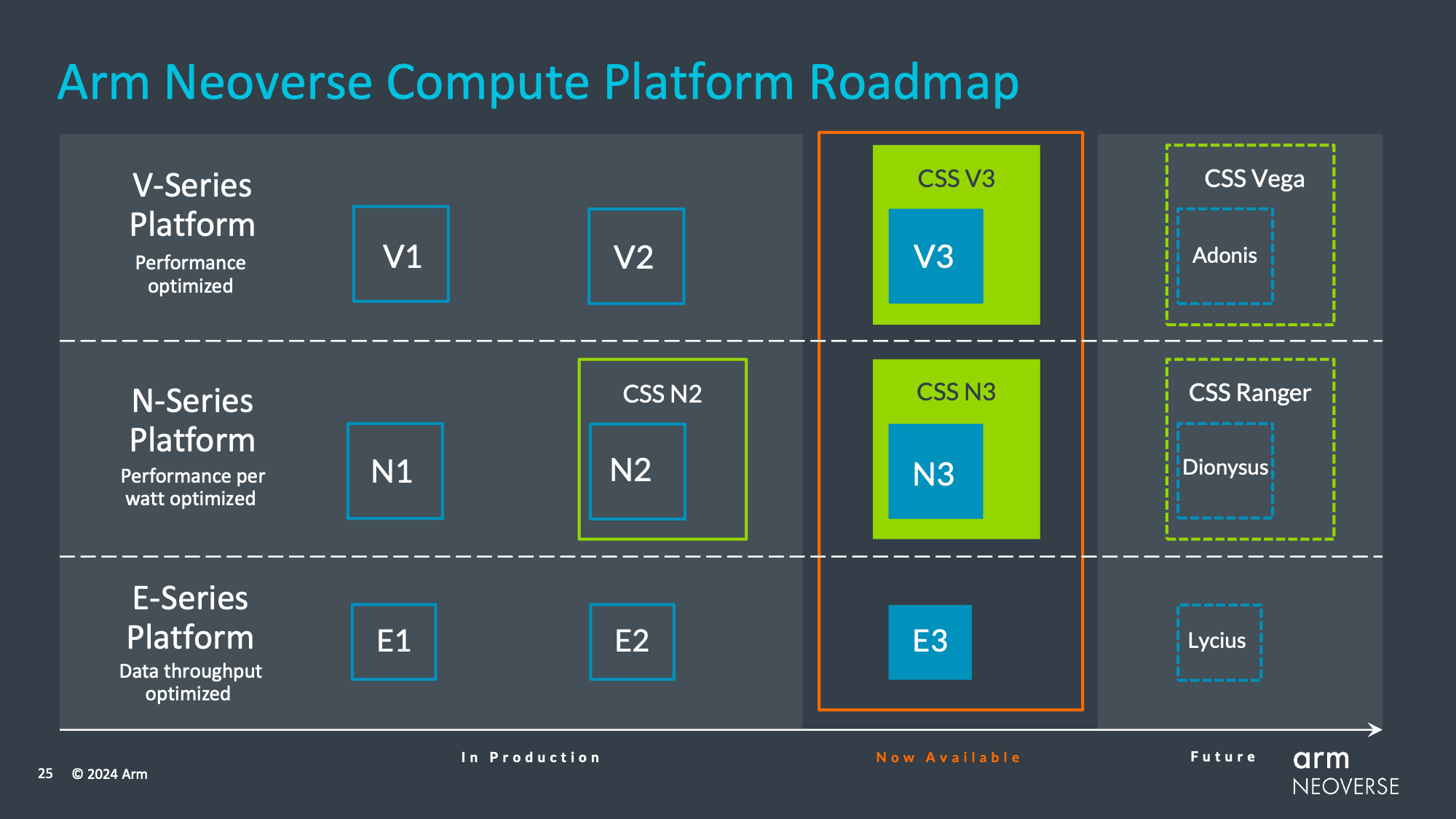
Notably here, this is a less detailed roadmap than Arm’s V2/N2-era roadmap, which included some high-level notes on what technologies were expected to be present. Instead, this roadmap provides codenames and little else.
Confirming that Arm is working on fourth-generation versions of the E, N, and V CPU cores, we have several new codenames overall. Lycius will be the next Neoverse E-series core (E4?), while Dionysus will be the next N-series core, and Adonis is the next V-series core. Meanwhile their respect compute subsystems are also getting codenames, with CSS Ranger and CSS Vega for the N-series CSS and V-series CSS respectively.
At this time Arm is not providing any guidance on when these designs will be ready for their customers. But with V3/N3 IP just going out the door to customers now, fouth generation Neoverse IP is likely a couple of years out.














{kind=link}
26 Comments
View All Comments
Dante Verizon - Thursday, February 22, 2024 - link
You keep talking to a troll as if he were a normal, educated person backed by arguments. ReplySarahKerrigan - Thursday, February 22, 2024 - link
I seriously doubt AMD will have their own ARM cores. I expect the forthcoming PC chip to be Cortex-X. Replymode_13h - Monday, February 26, 2024 - link
Why is it so hard to believe that AMD made their own ARM cores? Didn't you hear about the (now-canceled) K12?Furthermore, what would be the point of them just using a Cortex-X core? Just so they could ship it with a RDNA4 iGPU and XDNA NPU? That doesn't sound worthwhile. Reply
SarahKerrigan - Thursday, February 29, 2024 - link
I don't doubt AMD's capability to design ARM cores. I doubt the inclination of their leadership to throw large sums of money at the R&D associated with designing custom ARM cores for the potato-scale WoA market.We'll see in a year, I guess. Reply
mode_13h - Friday, March 1, 2024 - link
What if AMD has its eye on the server market, also? Or primarily? ReplyKangal - Sunday, March 3, 2024 - link
I'm with Sarah on this one.Nvidia did design their own ARM core architecture. Sometimes it paid off, other times not really. And from what it seems, AMD has more talent on their team. So I don't think they can't design and build a competitive solution, one that is cooked custom made.
However, there is very little reason for AMD to do so. For something worthwhile to come, it takes years. Qualcomm was on to something special with their Kryo-100 architecture, but they fired their whole division and went with Stock ARM cores. Or mildly tuned. Samsung tried to follow Apple and do something ambitious with their Mongoose cores, but weren't as talented, and by the time it was paying off they were at a big lithographic disadvantage.
With all that in mind, it's highly unlikely AMD even dips their toes into the ARM environment. And if they did, they will definitely go Stock. And would be leaning on Samsung for expertise, like with the Exynos 2400 or Tensor S3 systems.
What I'm hoping for, is that AMD is able to "marry" x86 and ARM together physically on the same chipset. Use an over-engineered Ryzen CPU to act like an Accelerator to process x86 specific strings, whilst, the bulk of the mundane threads are handled by the ARM cores. That could save a lot on heat and energy, and could build the next-gen Handhelds, Tablets and Laptops. And maybe spill-over into building more efficient/performant chips for Desktop and Cloud as well. But these are longterm visions, perhaps they have already had these in the lab for years, and they might surprise us in the near future. They have managed to surprise us with Zen, x3D, and AM5 platform, so they might be cooking. Otherwise, don't hold your breath. Even Qualcomm took ages to move 2019 Nuvia into a 2025 Oryon, which is ages in the fast-paced Tech Industry.
Reply
mode_13h - Sunday, March 3, 2024 - link
> Nvidia did design their own ARM coreAFAIK, those were weird VLIW cores with JIT translation. Makes sense for some embedded applications, but I think had no real mainstream potential.
> However, there is very little reason for AMD to do so.
If we assume that ARM has an inherent efficiency advantage, then AMD should struggle to compete (via x86) in the two most important markets for them: laptops and cloud CPUs. That's the upside of them doing a custom ARM core.
> Qualcomm was on to something special with their Kryo-100 architecture,
IIRC, they didn't perform much better than ARM's own IP. Considering the expense of doing in-house designs, I don't really blame Qualcomm for pulling the plug on that effort.
> it's highly unlikely AMD even dips their toes into the ARM environment.
> And if they did, they will definitely go Stock.
And what's the point of that? What would their competitive advantage be vs. Mediatek or the hyperscalers with their own ARM CPUs containing ARM IP?
> What I'm hoping for, is that AMD is able to "marry"
> x86 and ARM together physically on the same chipset.
Won't happen. The ARM and x86 system architectures are too different for them to play nicely in the same machine and within the same kernel.
> Even Qualcomm took ages to move 2019 Nuvia into a 2025 Oryon,
They were starting from scratch, other than the knowledge in their heads. Also, I think they missed more than one process window and had to then port their design to a new node, which also takes time.
In AMD's case, Jim Keller said the K12 was basically a project to replace Zen's frontend with ARMv8-A. If that's the approach they're taking, and if he believed it was feasible even with the resources they had 10 years ago, then I'm sure they could make a go of it now! Reply
Kangal - Sunday, March 10, 2024 - link
I don't think you comprehend the situation.Sure, a corporation like AMD has a huge advantage over a company like Google AND Microsoft combined. When we are talking about taking Stock ARM technology and adapting it into new architecture.
But AMD does NOT have that advantage over the market, where other players have a lot more heritage. The K12 was nothing special. That's a fact. If it was special, the technology would have been sold or licensed out, or better yet released for sale. Besides, the market has moved long since then, first with the big leap in 2016 with 16nm/Cortex-A73 then incremental big leaps to 2020 8nm/Cortex-A78, and then 2023/4nm/Cortex-X3. That was in a fairly small space of time, which is important context to explain the Apple/Nuvia/Qualcomm/Oryon situation. In that same timeframe we saw Intel struggle from 15nm 4core Skylake, to faster Skylake with 8core, then Intel 12th-gen and now the refrwsh Intel If you think AMD can enter the Server Space with ARM technology, you must appreciate that nothing is stopping the likes of Apple, Samsung, Qualcomm, Nvidia, MediaTek, or other players. Heck Amazon. These guys can potentially enter the market with better product than AMD and compete or dominate.
Where AMD actually has an advantage is with x86 and the legacy code it supports. That's what is keep them competitive. And with the limited budget and R&D they have, they are making the right calls this decade. Reply
Kangal - Sunday, March 10, 2024 - link
The most sense that makes for AMD is to:- out-compete Intel (main rival)
- keep pushing x86 forward (ergo, trucks vs cars)
- look into new ways of innovating hardware/software
...and if they want to incorporate ARM technology, do so by trying to adopt that into their systems. Just because it is difficult, does not mean it is impossible. There are niche systems out there with ARM cores and with RISC-V cores. My idea makes the most sense, to use the ARM cores that are more efficient for most tasks, and using their Zen cores for the odd thread. It's like going back to the 80s where we had devices with more freedom in their designs. Modern systems stick to fairly understood setups.
So yah, AMD will either steer clear of ARM technology, or they will innovate with it, and incorporate it. They won't try to compete with the established ARM Players on their turf, as that is not a wise business decision. Even if they MIGHT have a chance, it's a high risk/low reward scenario. Bad use good money, chasing bad money.
Reply
Findecanor - Thursday, February 22, 2024 - link
This must be the least comprehensible article I've seen on this web site yet. Reply