Hot Chips 2020 Live Blog: Next Gen Intel Xeon, Ice Lake-SP (9:30am PT)
by Dr. Ian Cutress on August 17, 2020 11:15 AM EST- Posted in
- CPUs
- Intel
- Xeon
- Enterprise CPUs
- 10nm
- Live Blog
- Ice Lake
- Ice Lake-SP
- Hot Chips 32

12:09PM EDT - Our first talk of the day is from Intel, about its next-generation Ice Lake Xeon Scalable processor.
12:10PM EDT - We're 20 minutes from the Intel talk starting, but Hot Chips will commence with a 15-minute intro talk to the conference, which we'll cover here
12:10PM EDT - This is the first 'Virtual' Hot Chips, due to COVID. Last year's attendance was 1200-1400 or so (I'm still waiting on exact numbers)
12:10PM EDT - With the conference going virtual, they cut prices, which means there has been an uptick in signups I'm told
12:11PM EDT - Highest cost for the conference and tutorials was $160. Bargain
12:11PM EDT - Tutorials were yesterday, whereas the main conference starts today
12:12PM EDT - Today there's a lot of talks on CPU and GPU. Intel, IBM, AMD, more Intel, then NVIDIA A100, Intel Xe, and Xbox Series X to finish around 6pm PT
12:18PM EDT - And here we go with the intro to the conference


12:19PM EDT - Record registration numbers. 2100+ as of this morning, still growing

12:20PM EDT - Intel is the Rhodium sponsor
12:20PM EDT - That paid for some of the equipment for streaming, and provided the studio for the event
12:20PM EDT - Platinum sponsor is AMD
12:21PM EDT - Now going through some of the attendee info - links to help with logins and such
12:23PM EDT - Presentations and recordings are usually made public by end-of-year

12:29PM EDT - Two keynotes, one from Raja
12:32PM EDT - Questions through slack through the event

12:32PM EDT - And now the first session begins
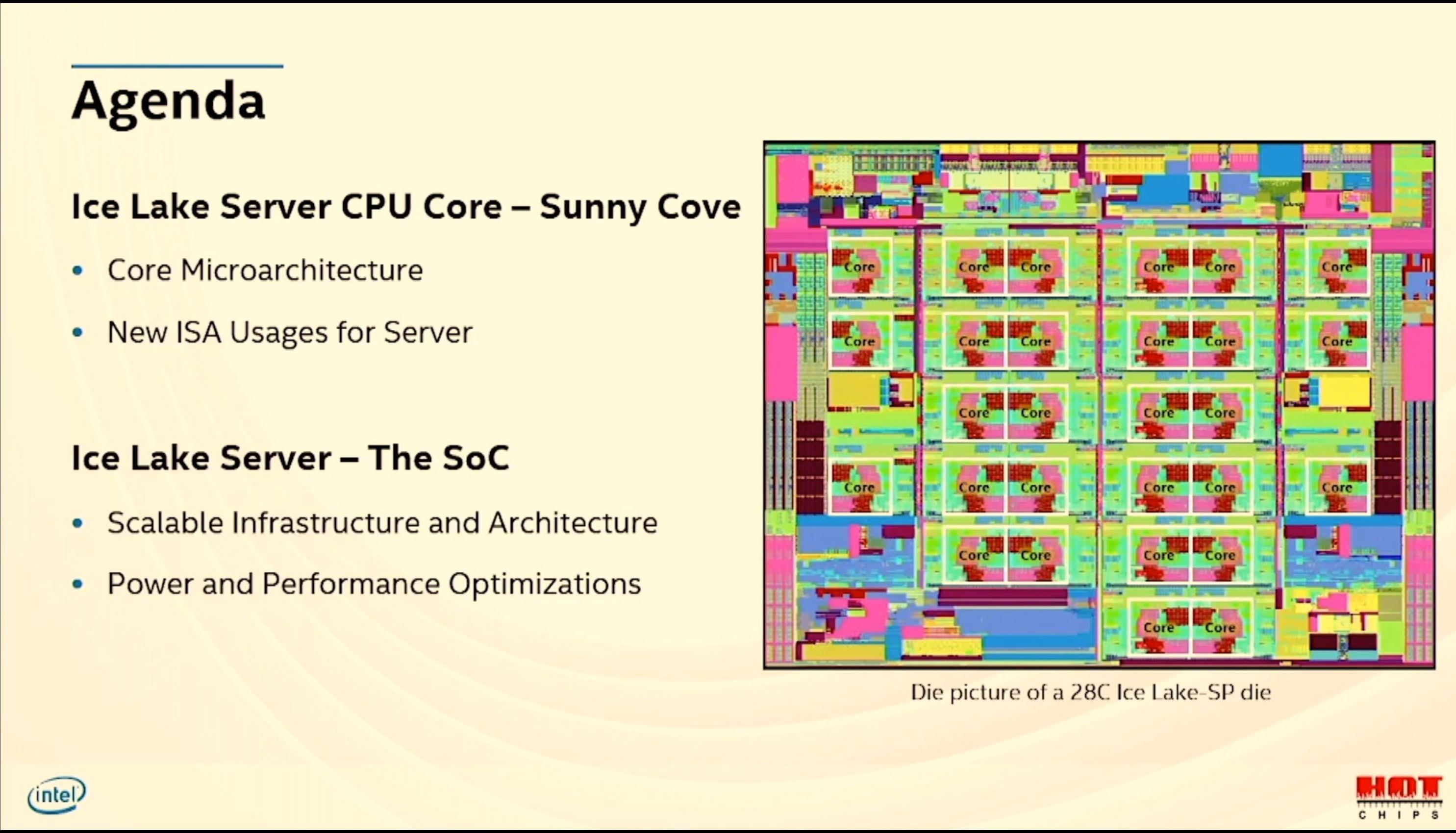
12:33PM EDT - First up is Intel Ice Lake Xeon
12:34PM EDT - Speaker was lead on Nehalem-EX, and featured in Sandy, Ice

12:34PM EDT - 10+ process
12:34PM EDT - New 2-socket whitley
12:34PM EDT - Uses Sunny Cove
12:35PM EDT - New ISA
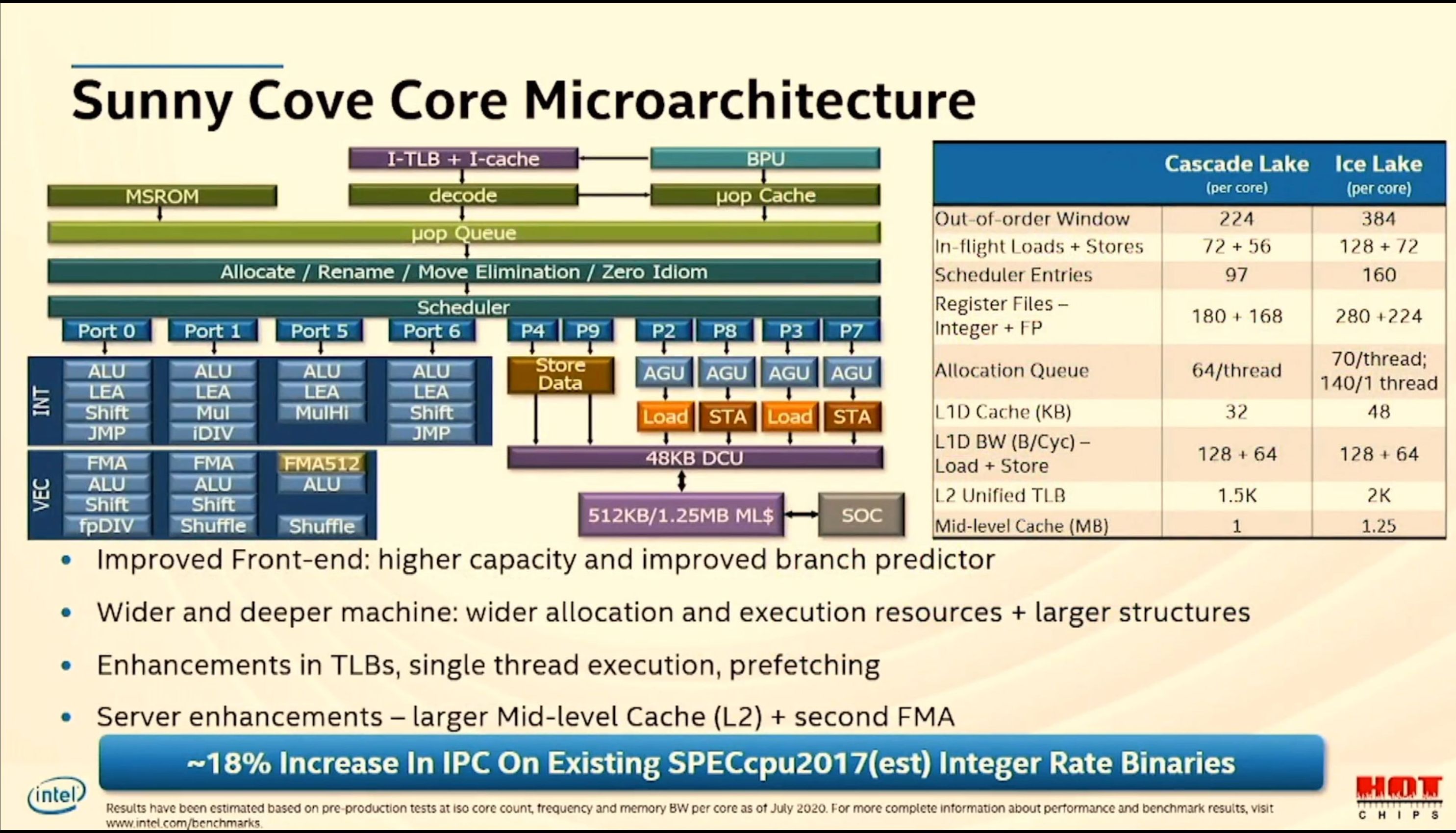
12:35PM EDT - 384 OoO window, 128+72 in flight loads/stores
12:35PM EDT - vs cascade
12:35PM EDT - 48 kB L1D
12:36PM EDT - 1.25 MB L2 cache
12:36PM EDT - ~18% IPC over Cascade
12:36PM EDT - second FMA

12:37PM EDT - New instructions
12:37PM EDT - AVX-512 IFMA, VPMADD52
12:37PM EDT - Vector AES, GFNI, SHA-NI
12:37PM EDT - VBMI, VPOPCNT*
12:38PM EDT - (not much more detail than what's on the slides)
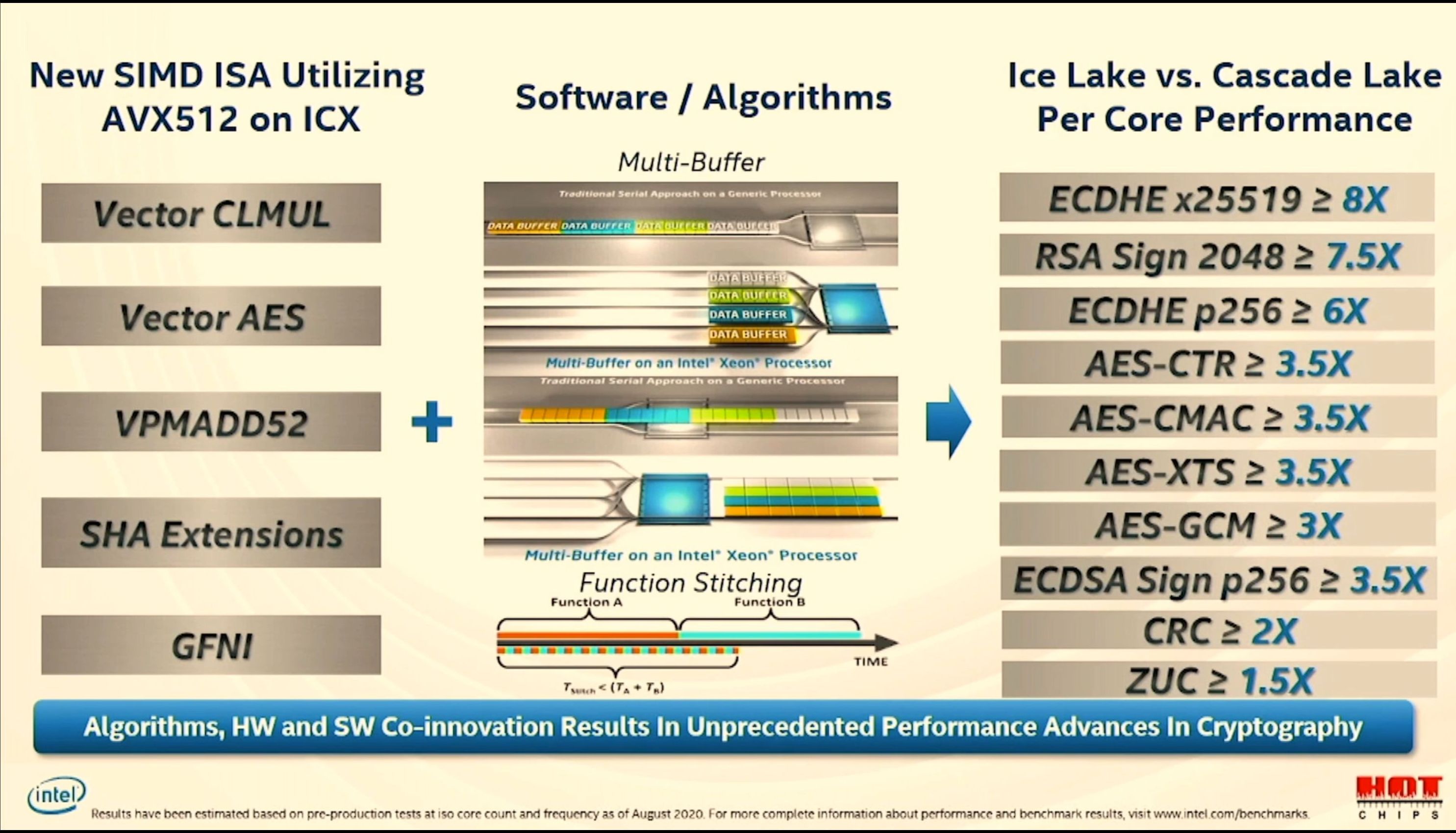
12:38PM EDT - Updating current software to boost perfomance
12:40PM EDT - New infrastructure architecture

12:40PM EDT - New control structure
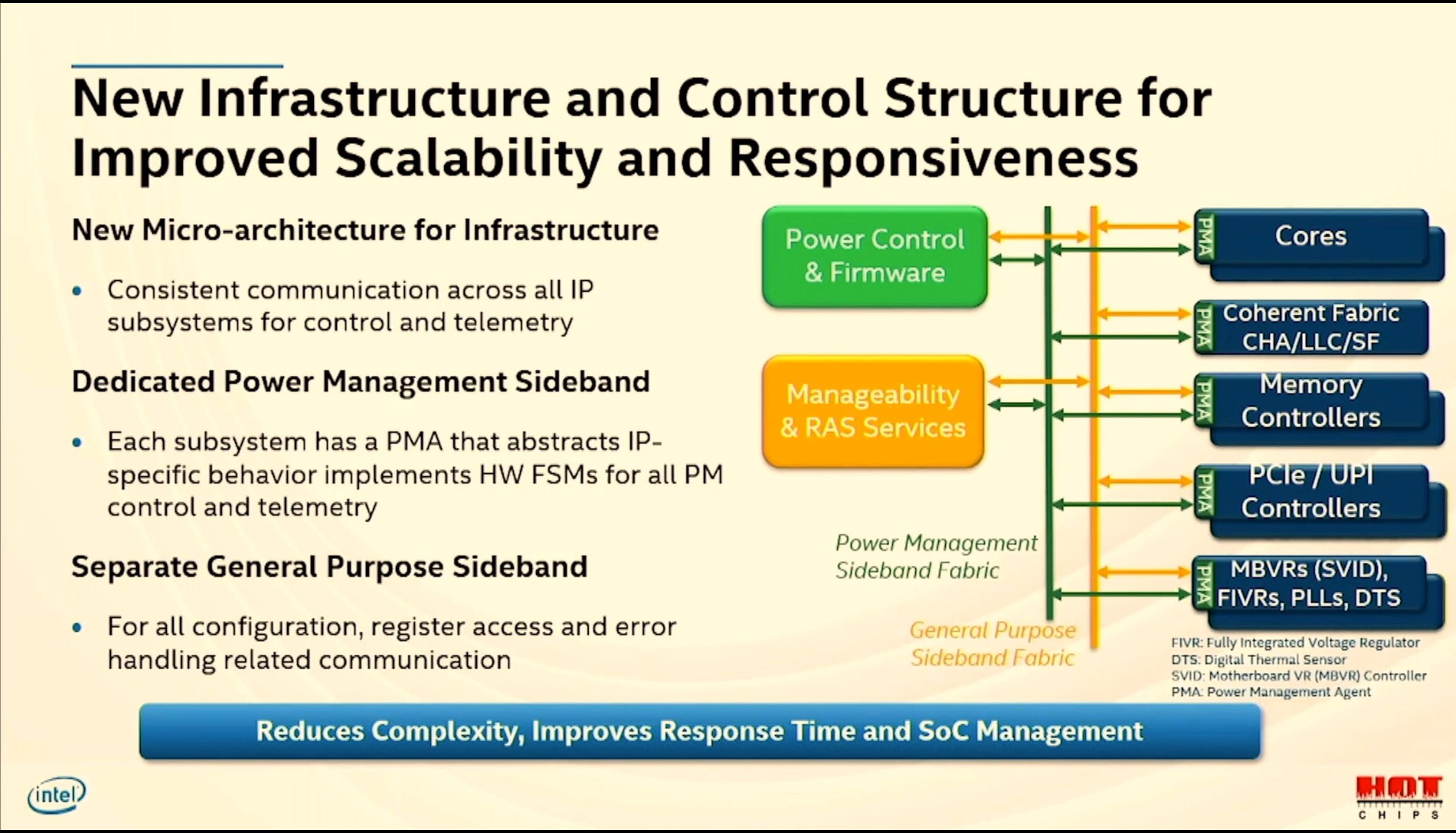
12:40PM EDT - Distributed control and telemetry fabric
12:41PM EDT - One new fabric dedicated for power, one for other
12:41PM EDT - P-Unit for power
12:41PM EDT - Communication streamlined
12:42PM EDT - Control is IP independent

12:42PM EDT - Building new SoCs becomes easier
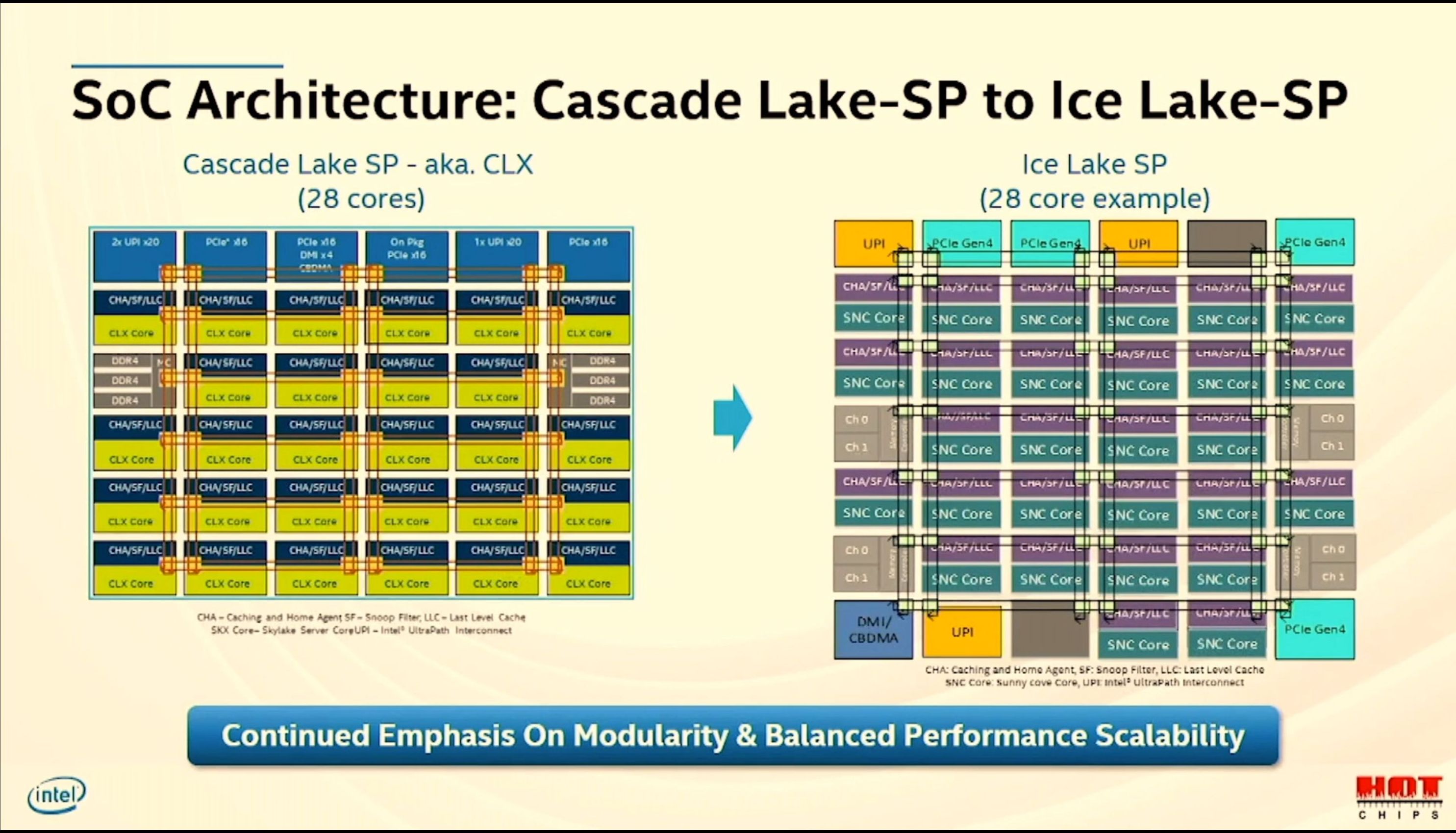
12:43PM EDT - Migration from Cascade to Ice
12:43PM EDT - 28 core to 28 core
12:43PM EDT - Move from 6x3 ring to 7x3 ring
12:43PM EDT - Memory is now 2 channels per segment, not 3
12:43PM EDT - So 8 memory channels total
12:44PM EDT - IOs on north and south of die

12:44PM EDT - PCIe Gen 4 (x64?)
12:45PM EDT - New IO virtualization implementation, up to 3x bw scaling
12:45PM EDT - larger TLBs and large page sizes
12:45PM EDT - 3 UPI links, independently clocked
12:45PM EDT - Doesn't say if 10.2 GT/s
12:46PM EDT - Each UPI agent has its own fabric stop for better comms to other sockets
12:46PM EDT - New memory controller design with optimizations - built from ground up, built with efficiency in mind
12:47PM EDT - Best efficiency across all frequencies. Supports top DDR4 speeds (3200 at 2DPC?)
12:47PM EDT - TME using AES-XTS 128-bit, enabled by BIOS
12:47PM EDT - When enabled, entire memory is encrypted. Key is not accessible from BIOS or software. HW generated key
12:47PM EDT - Overhead is a few percent perf impact
12:48PM EDT - Support for Optane-200 DCPMM
12:48PM EDT - At top DDR4 speed? DDR4-3200? I thought 200 was 2666 only

12:48PM EDT - New mechnaisms for latency and coherence
12:49PM EDT - Dynamic prefetch throttling - modulates prefetching under memory bandwidth to enable faster speeds rather than overloading the prefetchers
12:50PM EDT - Non-Temporal Write optimization helps low core count writes by not waiting for snoop responses - pull data from core early
12:52PM EDT - OSB - opportunitistic snoop broadcast updated, support for new opcodes to reduce latency for socket cache-to-cache by ~70ns
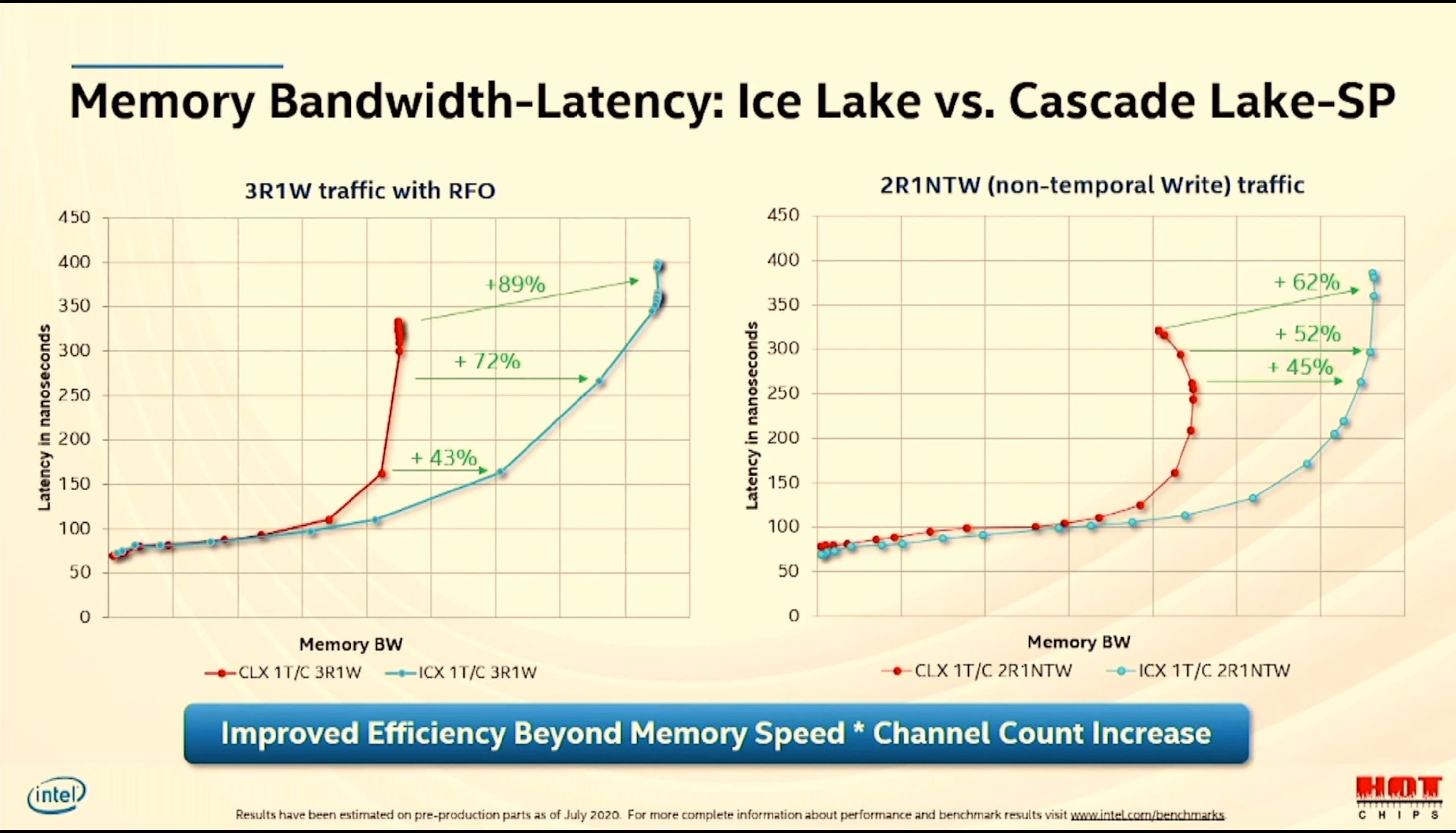
12:54PM EDT - Bandwidth increases compared to Cascade
12:54PM EDT - Now power management latency
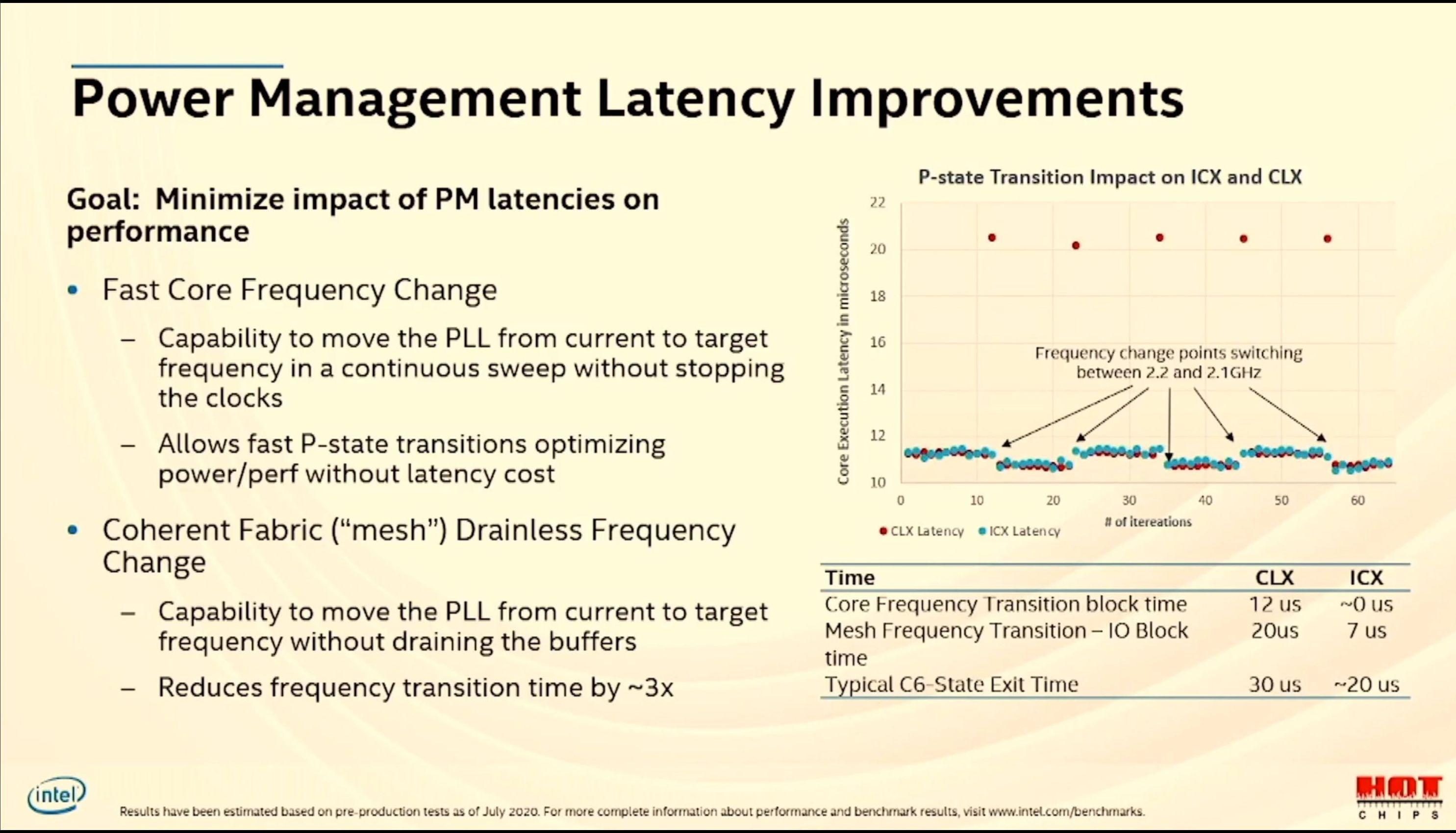
12:55PM EDT - P-state and C-state transition latency were hurting performance
12:55PM EDT - New PLL design allows for not locking
12:55PM EDT - Allows transitions almost not-visible
12:56PM EDT - Latency spikes disappear when P-states change
12:56PM EDT - Also new Fabric frequency change - used to drain buffers and restart clocks. Now no longer needed, reduces latency by 3x
12:56PM EDT - Latencies on bottom right of slide
12:57PM EDT - AVX512 frequency is low compared to SSE - now some improvements

12:57PM EDT - Better power analysis of specific AVX512 instructions
12:57PM EDT - AVX512 now has smarter mapping between instructions and maps
12:57PM EDT - 3 new power levels for AVX512
12:58PM EDT - For specific instructions, end up with better frequency for 256-bit and 512-bit instructions
12:58PM EDT - Provides software writers more incentive to use AVX-512
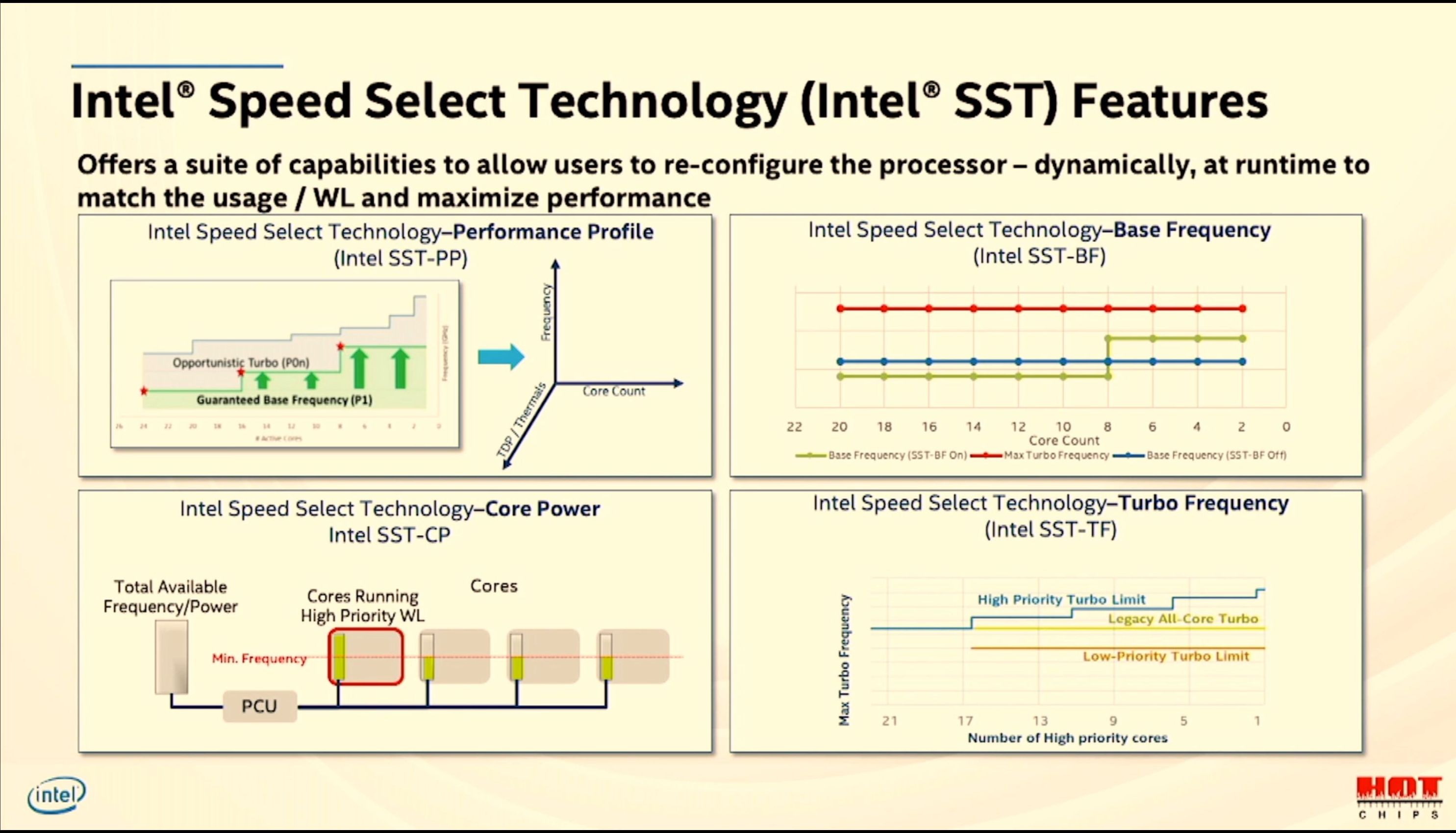
12:59PM EDT - Speed Select Features
12:59PM EDT - SST-PP: Performance Profile
12:59PM EDT - SST-BF: Base Frequency
12:59PM EDT - SST-CP: Core Power
01:00PM EDT - SST-TF: Turbo Frequency
01:00PM EDT - Select Ice Lake SKUs will have Intel SST enabled, allowing customers to change the performance profile of the CPU based on cooling or requirements
01:00PM EDT - Dynamically adjusted at runtime

01:02PM EDT - Wrap up - Sunny Cove in Xeon on 10nm. Better infrastructure and fabric control
01:03PM EDT - Ice Lake: A Balanced CPU for All Server Usages
01:04PM EDT - Now Q&A
01:04PM EDT - Q: What is the perf impact when TME enabled? A: Target was to be less than 5%. We are seeing 1-2% on pre-prod samples. Not more than that.
01:05PM EDT - Q: How will base frequency scale for AVX-512. Only turbo in presentation A: Similar improvements will apply. Less loss of freq for similar instructions
01:06PM EDT - Q: Support additional crypto? A: Reach out to Intel if you want additional algorithms
01:06PM EDT - Q: What change in PCIe for VM improvement? A: New Virtualization engine design. Increased TLB. VT-D IOMMU running at double speed. Large page support for translation requests as well. All new, that's how 2x
01:07PM EDT - Q: 18% IPC at iso-core. How does it compare with Cascade/Cooper A: They were the same arch, cascade/cooper. No comment on SoC level performance. We will see substantial improvements at SoC level.
01:08PM EDT - That's a wrap. Next talk is IBM, head on over to that live blog








24 Comments
View All Comments
SirDragonClaw - Monday, August 17, 2020 - link
I am pumped for the Intel GPU, Nvidia GPU and Xbox Arch talks!jeremyshaw - Monday, August 17, 2020 - link
Nothing new in any of those talks, it appears. Nvidia is going over their A100 material again, Intel Xe, you can get similar if not nearly all relevant information from Anandtech already, and Xbox Arch covers nothing new.Only thing interesting to me is how little IBM talked about their partners this time around. Looks like they really did burn some bridges at the end of POWER9.
nandnandnand - Monday, August 17, 2020 - link
I took some notes back in May. 2nd-gen Cerebras Wafer Scale Engine, Alibaba RISC-V and NPU, 3rd-gen Google TPUs, 4096-core RISC-V Manticore, Marvell ThunderX3, and ARM Cortex-M55 look interesting. Maybe some of those have already been detailed, I didn't check.Samsung could also be sharing some more info about the "X-Cube" 3D TSV SRAM. Ref: https://www.theregister.com/2020/08/13/samsung_tou...
JayNor - Monday, August 17, 2020 - link
would be interesting to know how many avx512 units they put in the server cores.also would be interesting to know if MKTME has any software behind it.
also would be interesting to know if they have some pcie4 peripherals for demo ... Habana NNP, Optane SSD, perhaps a Xe SG1.
JayNor - Tuesday, August 18, 2020 - link
Dr. Cutress answered this on his twitter acct. Intel effectively doubled the avx512 units per Sunny Cove core on the server chip.https://twitter.com/IanCutress/status/129546338432...
TomWomack - Tuesday, August 25, 2020 - link
I think this is "doubled" in the sense that they're at the same level as Skylake-SP (which has 256-bit SIMD units on ports 0 and 1 and a 512-bit unit on port 5); getting substantially lower performance from an i9-11940X than from an i9-7940X would otherwise be embarrassing.Dehjomz - Monday, August 17, 2020 - link
I’m new here.That being said, any speculation as to why Ice lake Xeon is using sunny cove and not willow cove? I thought from the tiger lake stuff that willow cove is a much better core design?? Just curious on if anyone has any thoughts...
Eulytaur - Monday, August 17, 2020 - link
Ice Lake SP is just like Ice Lake U/Y in that they're both Sunny Cove. The cadence for Intel architectures is that consumer gets it first, then it's adapted for Xeon a year later. We get Tiger Lake on Willow Cove for now and then Sapphire Rapids on Willow Cove a year from now.JayNor - Monday, August 17, 2020 - link
but Sapphire Rapids has AMX instructions and Willow Cove does not, based on arch manual, as someone has already pointed out. Also, server cores had avx512 before moving to consumer cores.DanNeely - Monday, August 17, 2020 - link
Specific features can debut on server versions of a specific generation of a core instead of on the consumer version (or vice versa); that doesn't change that due to more extensive pre-release validation that the base server cores lag about a year behind the base consumer ones.